Intro: Scalling Relational Databases + NoSQL | TP Docker
RDBMs at scale & NoSQL
Plan
Andrei ARION
XML databases research, INRIA & UPS
software engineer/consultant
data engineering team, LesFurets.com

Ressources (Slides/TPs/VMs) : bit.ly/bigdata-telecom ⇒ andreiarion.github.io
LesFurets.com
Module Planning
How
How it may seem
Home readings




Plan
Data: the new hope
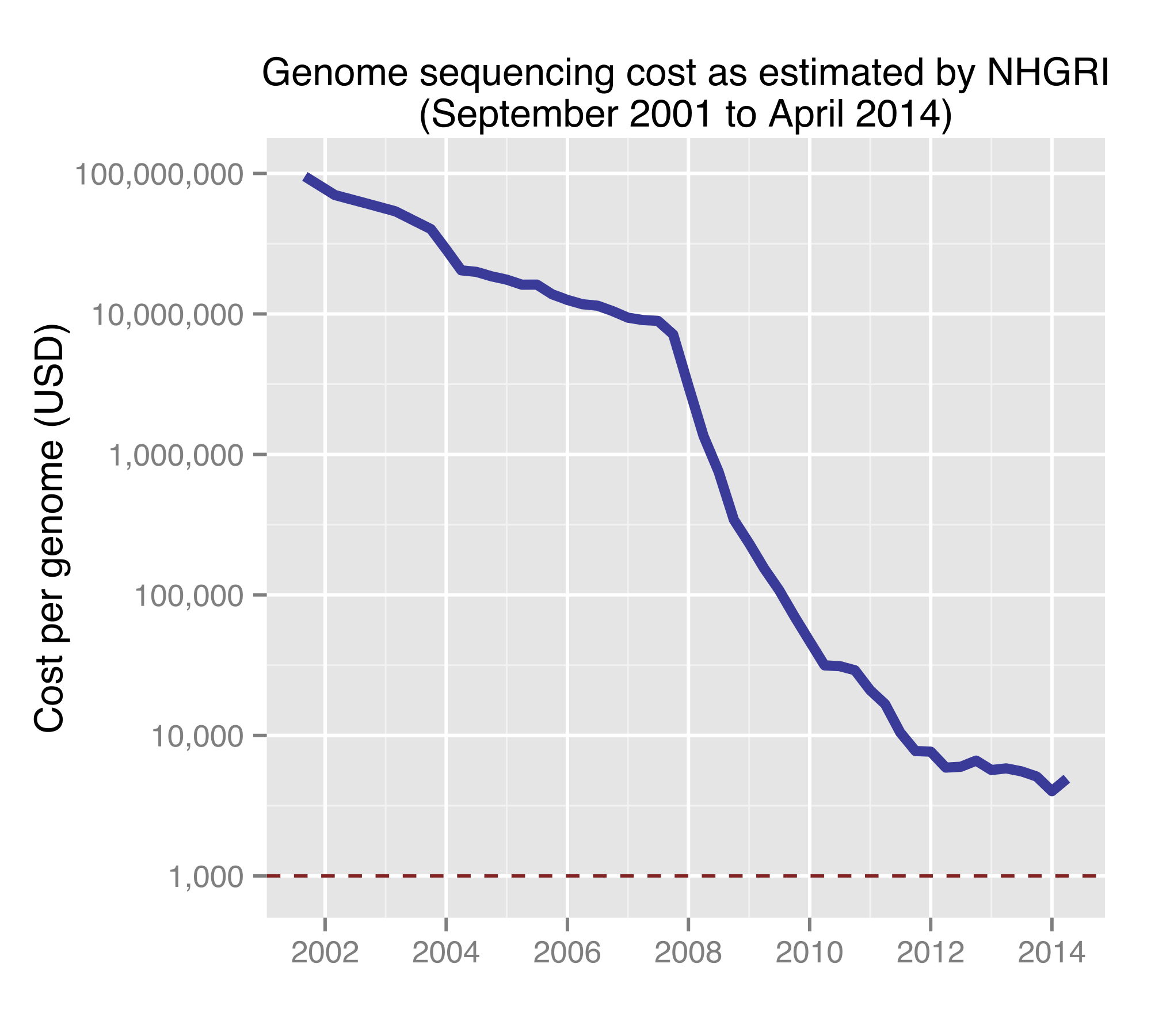
Data: the new oil

Data: most common use
Web analytics applications
track the number of pageviews for each URL
what are the top 100 URLs
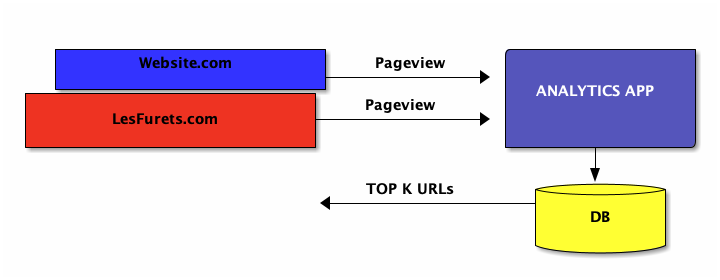
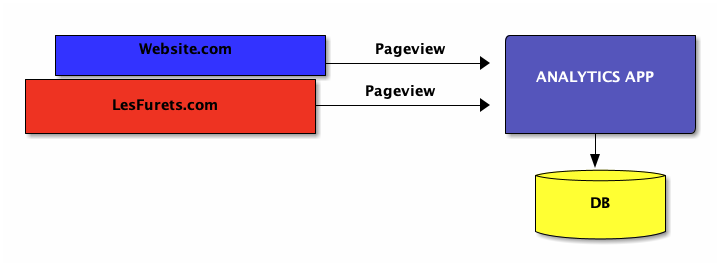
Simplest architecture
track the number of pageviews for each URL
what are the top 100 URLs

Queries
Insert pageviews

INSERT INTO PageViews(app_id, URL, page_views) VALUES
(1,"http://www.lesfurets.com/index.html",1);
INSERT INTO PageViews(app_id, URL, page_views) VALUES
(2,"http://Website.com/base.html",1);
INSERT INTO PageViews(app_id, URL, page_views) VALUES
(1,"http://www.lesfurets.com/assurance-auto",1);Update pageviews
UPDATE PageViews SET page_views = page_views + 1
WHERE app_id="1" AND URL="http://www.lesfurets.com/index.html";Top 100 URLs for a client
SELECT URL,page_views FROM PageViews
WHERE app_id = '1'
ORDER BY page_views DESC LIMIT 100Production load
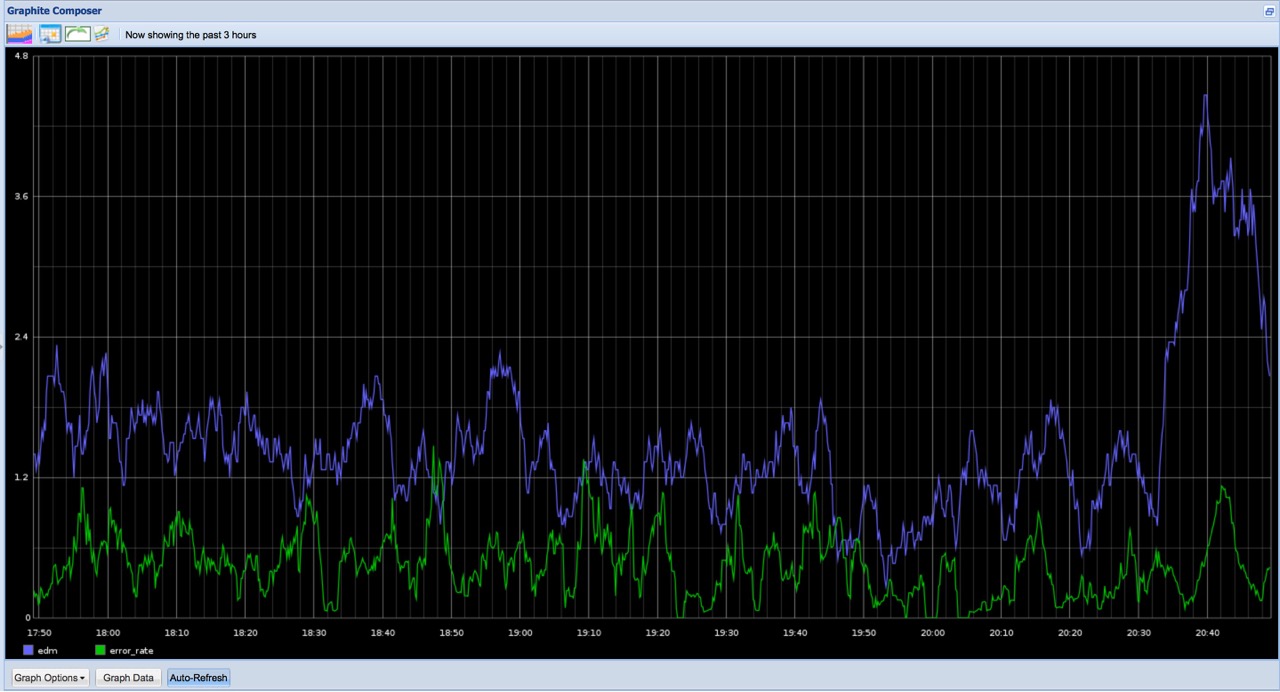
Timeouts
Timeout error on updating the database
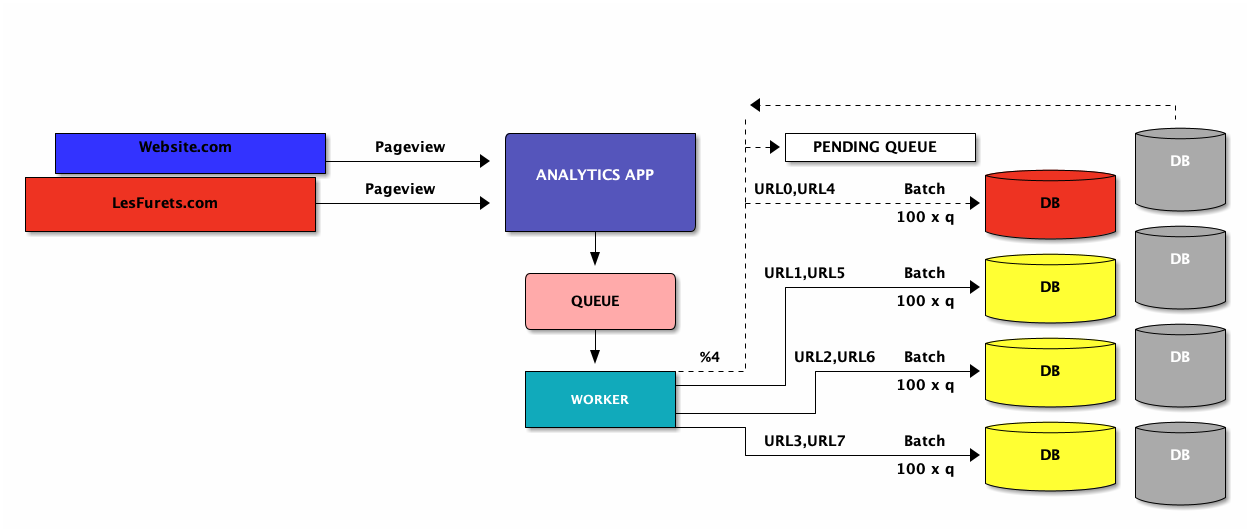
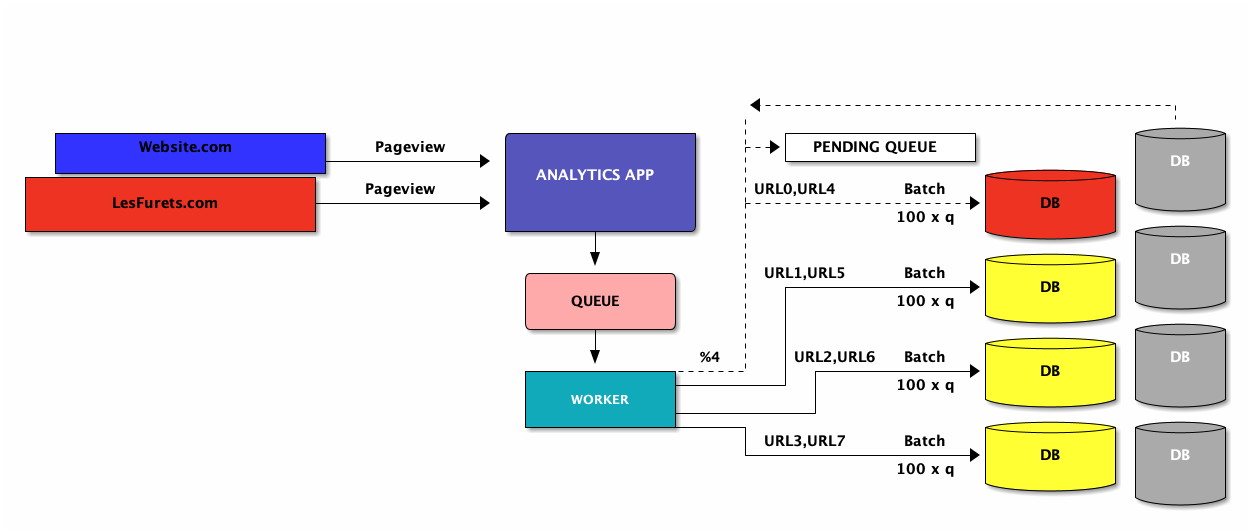
Fix#1: queuing + batching
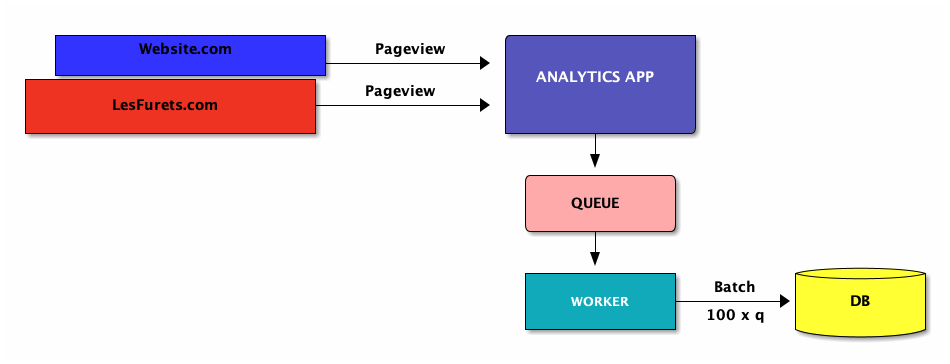
Fix#1: implications
Fix#2: Sharding (horizontal table partitioning)
Fix#2 Sharding
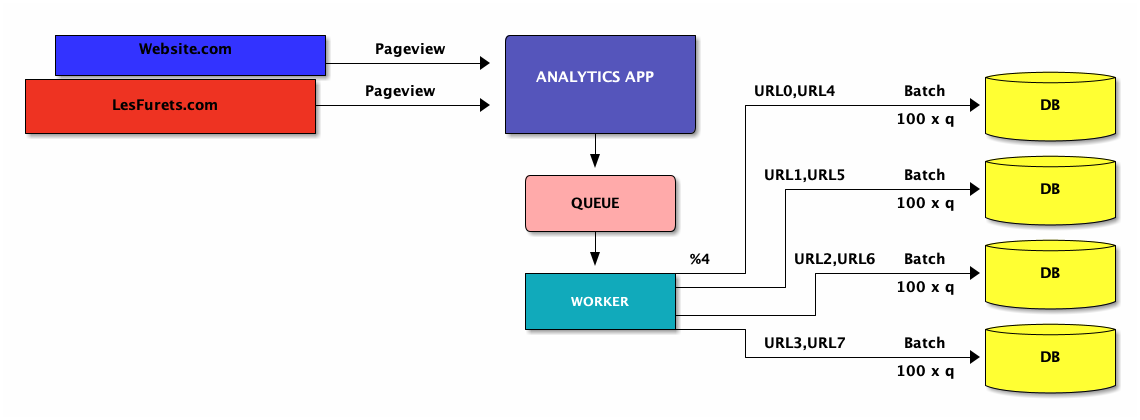
Fix#2: Sharding implications
Fix#2 Sharding
Fix#3 Replication
Human failures
Human failures
Human failures

UPDATE PageView SET page_views = page_views + 2
WHERE user_id='42' AND URL='myurl';Human failures
event logging
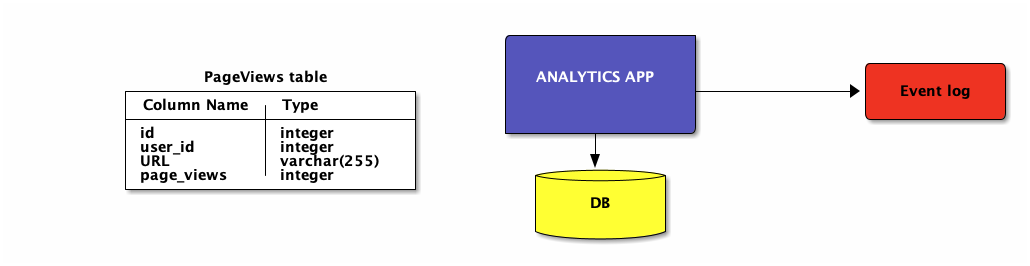
Human failures
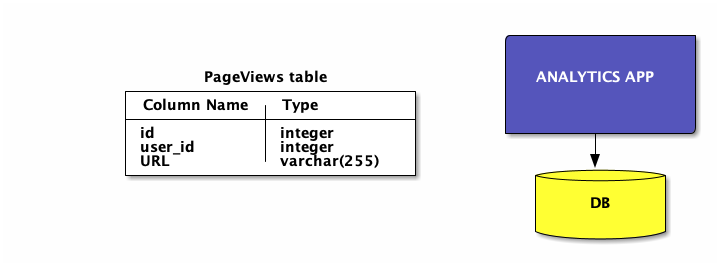
Incremental data model

Incremental data model
Human failures
Incremental data model ⇒ immutable data model
What went wrong?
do I build new features for customers?
or just dealing with reading/writing the data?
What went wrong?
Wishlist 1 : Storage
Wishlist 2 : Queries
Wishlist 3 : Data model
Plan
RDBMS: the good parts
simple model with sound mathematical properties (ACID)
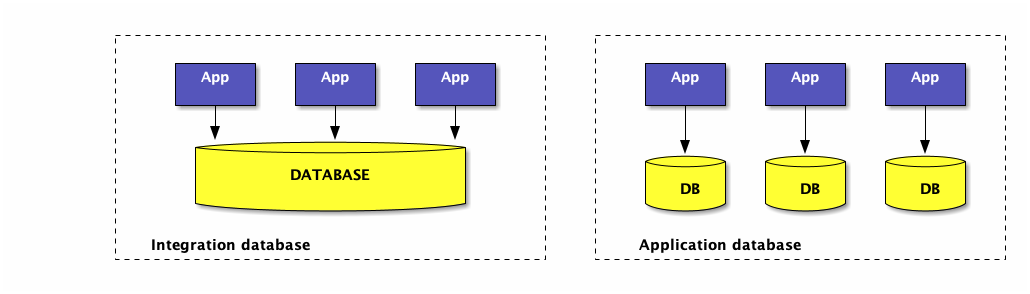
| Integration database | Application database |
|---|---|
consistent data set changes need to be coordinated → side effects | easier to maintain/evolve/scale standard interfaces between systems (SOA) |
"Classical" RDBMS Architecture
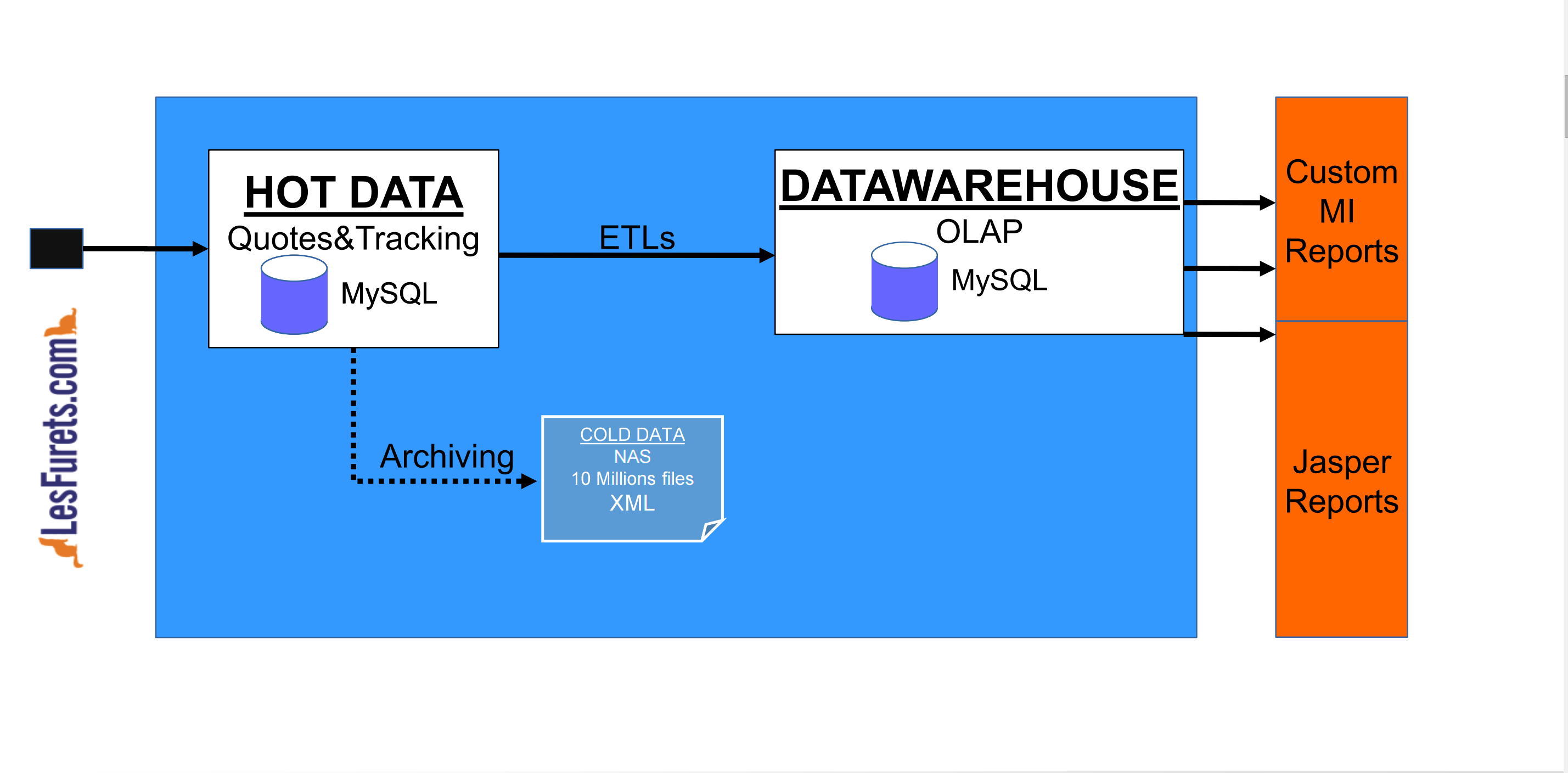
"Classical" RDBMS Architecture concerns
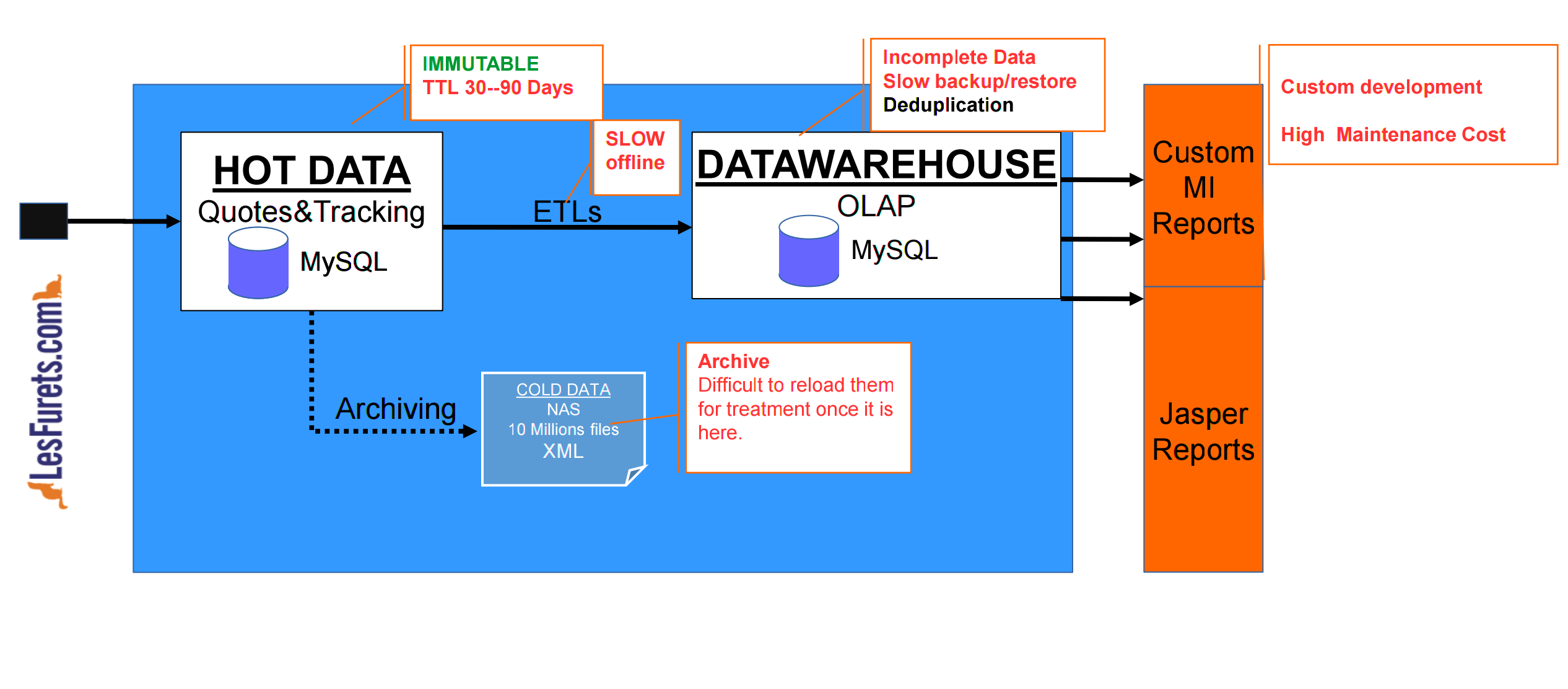
LesFurets Data characteristics
Why replicate?
MySQL scale-out
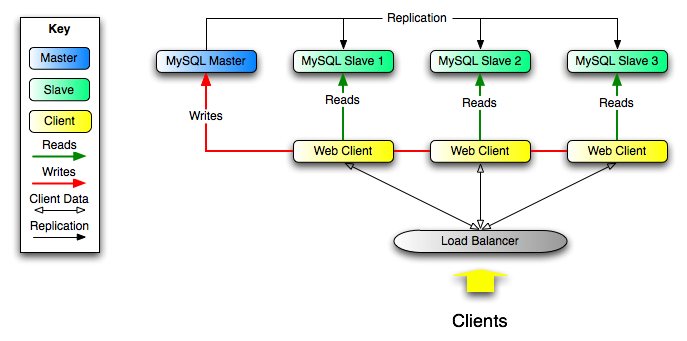
MySQL replication properties
MySQL basic replication
MySQL replication: binlog
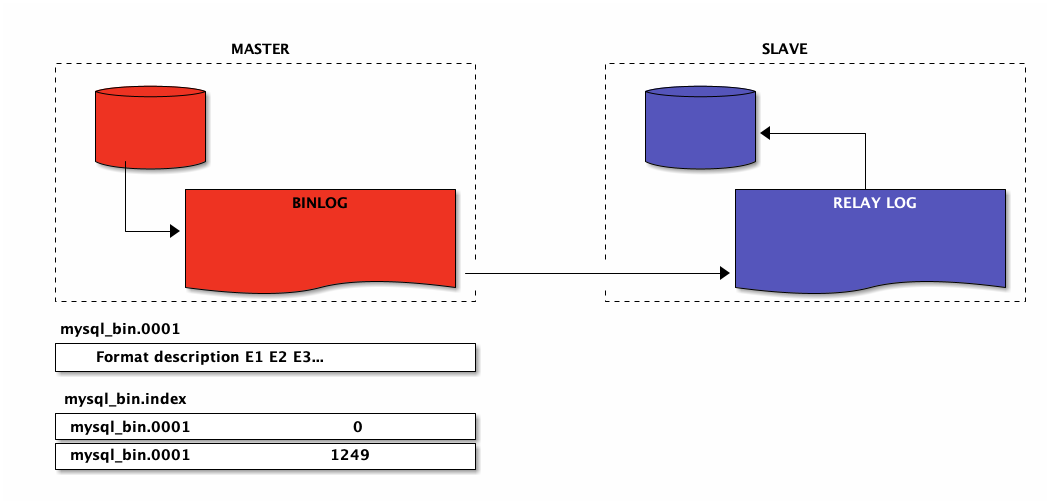
MySQL replication: master configuration
MySQL replication: slave configuration
MySQL replication: slave configuration
MySQL replication: SHOW SLAVE STATUS
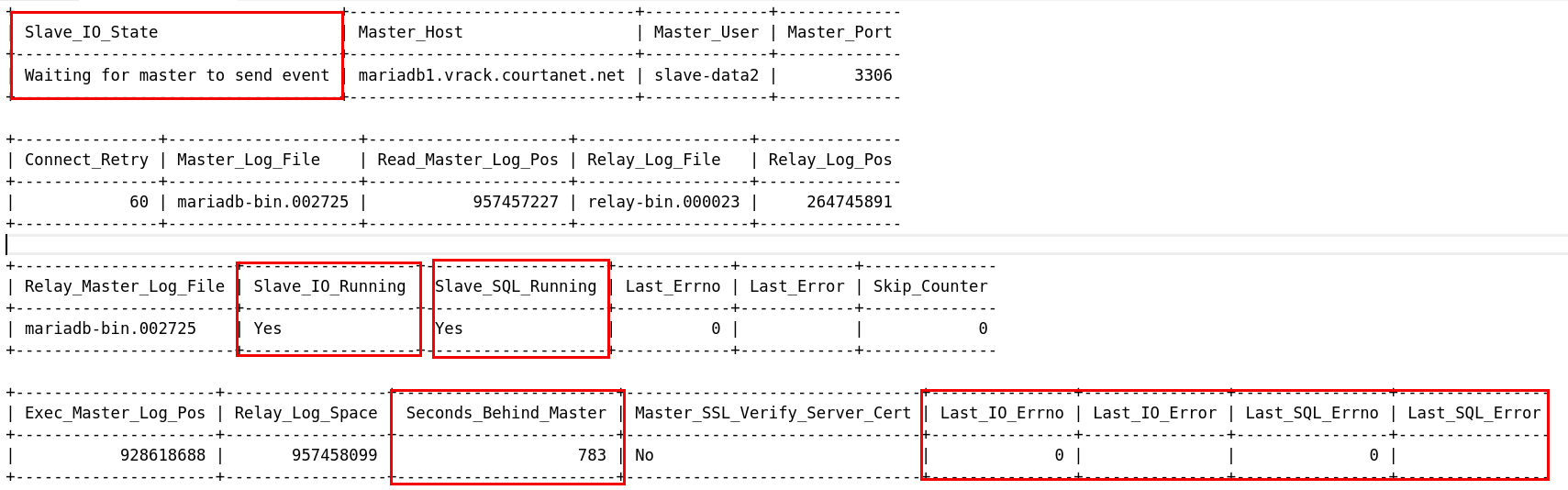
MySQL replication
What is replicated?
SBR
RBR
Mixed
Semi-synchronous replication
Crash recovery (M)
Scaling Writes
Galera Cluster
LF MariaDB Galera Cluster
Scaling MySQL @LF
Plan
SQL models tuples and joins
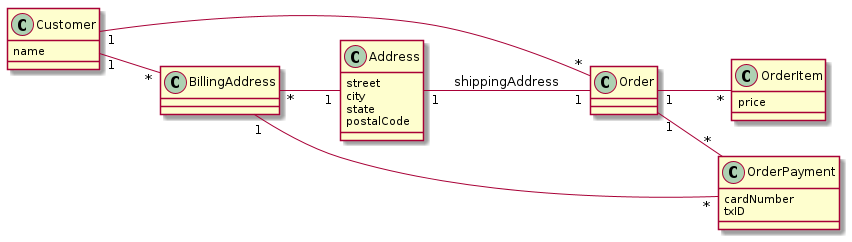
Modeling complex data
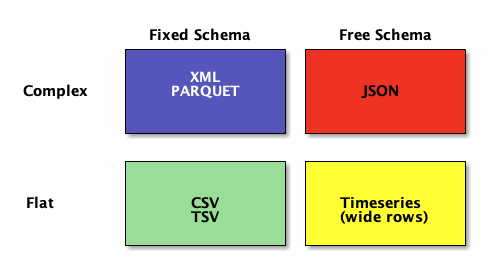
Relational vs Document/Objects
Relational model: relations / tuples + normalization
Memory: rich data structures !
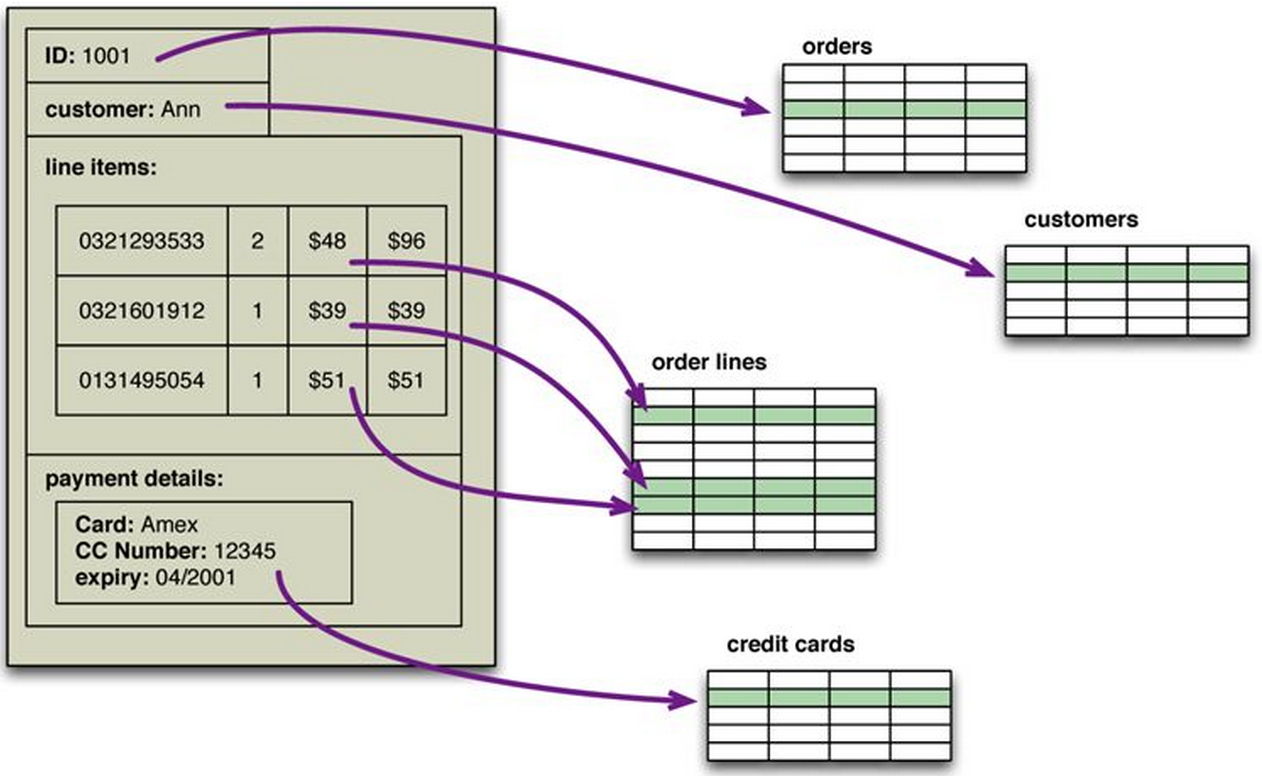
Relational vs Document/Objects
Not only SQL
NoSQL models agregates
collection of related objects that should be treated as a unit (consistency / data management)

Modelling SQL vs NoSQL
NoSQL aggregate types ⇒ APIs
Key-value databases
Document oriented databases
Column oriented databases
Stores data in tables/column families as rows that have many columns associated to a row key
Map of maps (rowId → (columnName → columnValue))
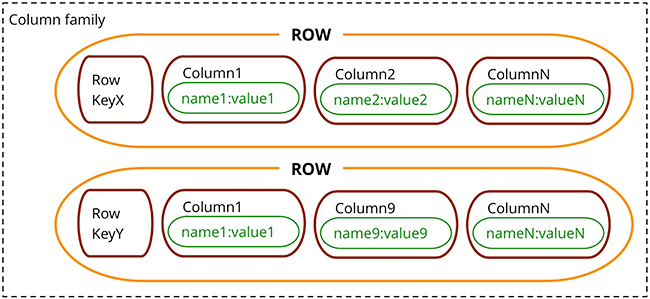
Use cases: Time series, event logging, ...
Graph databases
Stores entities and relations between entities
Query: traversal of the graph
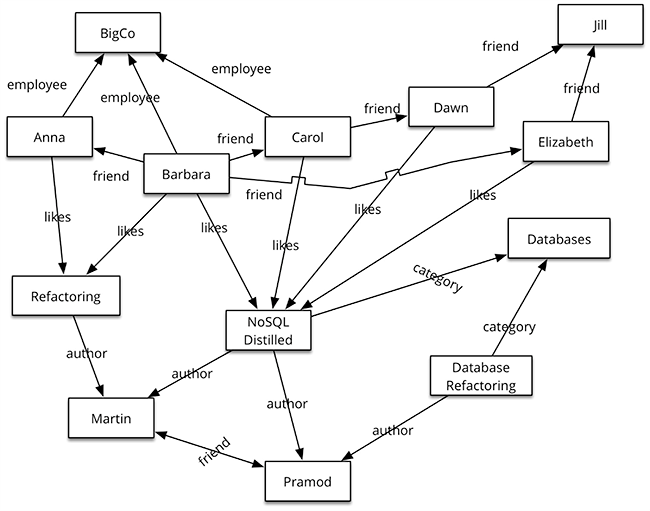
Use cases: Social networks, recommendation engines
Choosing a storage solution:
Business requirements
Technical aspects
Other aspects
Simple decision tree

Tradeoffs
Polyglot persistance
aggregates have different requirements (availability/consistance/backup)
Mix and match relational and non-relational storage
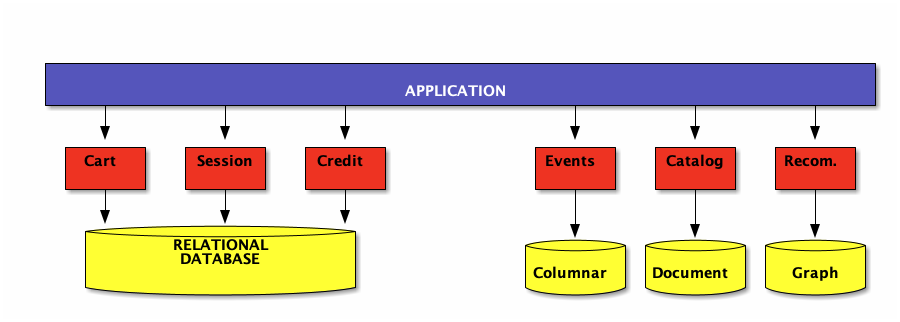
Cloud architecture @LesFurets
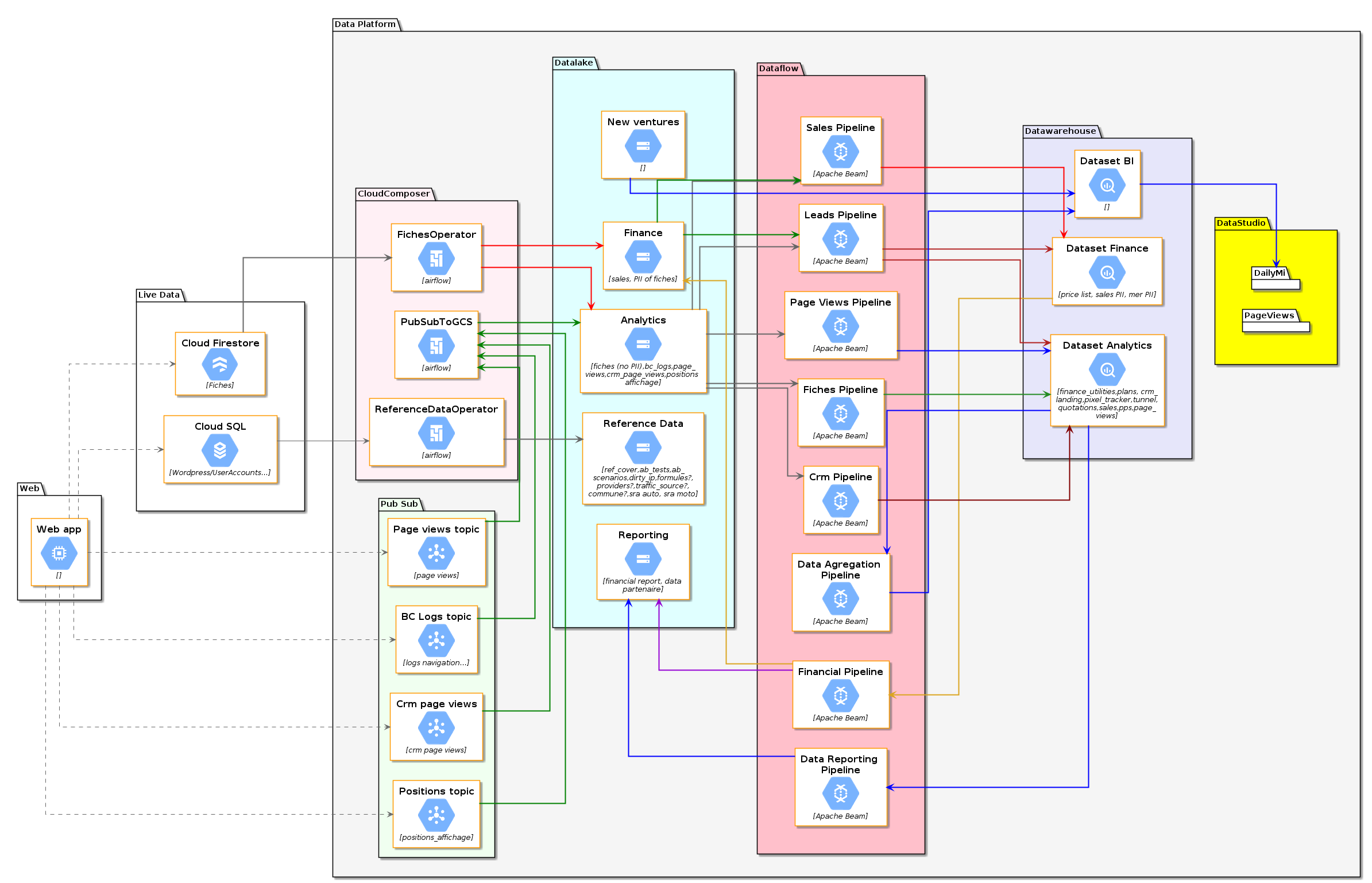
Plan
SQL in 2022 ?
SQL in 2022 ?
Why SQL is beating NoSQL, and what this means for the future of data (2017)
SQL as interface / universal language for data processing
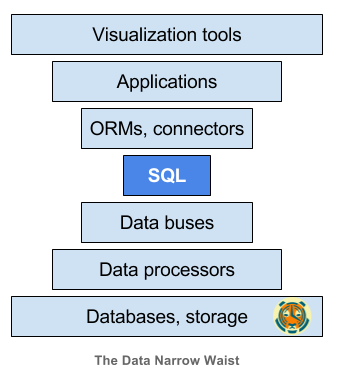
SQL in 2022 - Massively Parallel Processing
SQL in 2022 - ML in SQL

SQL in 2022 - SQL analytics-as-code
Dwh pipelines shift: ETL to ELT
 DBT does the T in ELT (Extract, Load, Transform) processes
DBT does the T in ELT (Extract, Load, Transform) processeswrite transformations as queries and orchestrate them
transform data where it lives
using plain SQL SELECT
infer dependency graphs and run transformation models in order ⇒ pipeline automation
Why PostgreSQL?
PostgreSQL offsprings
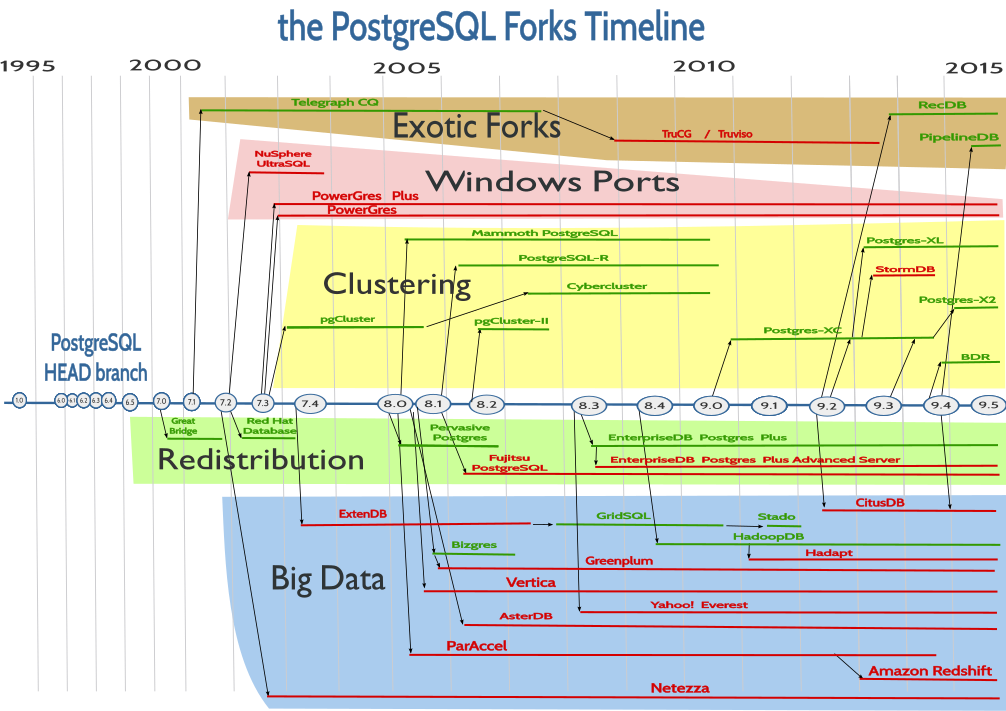
PostgreSQL features
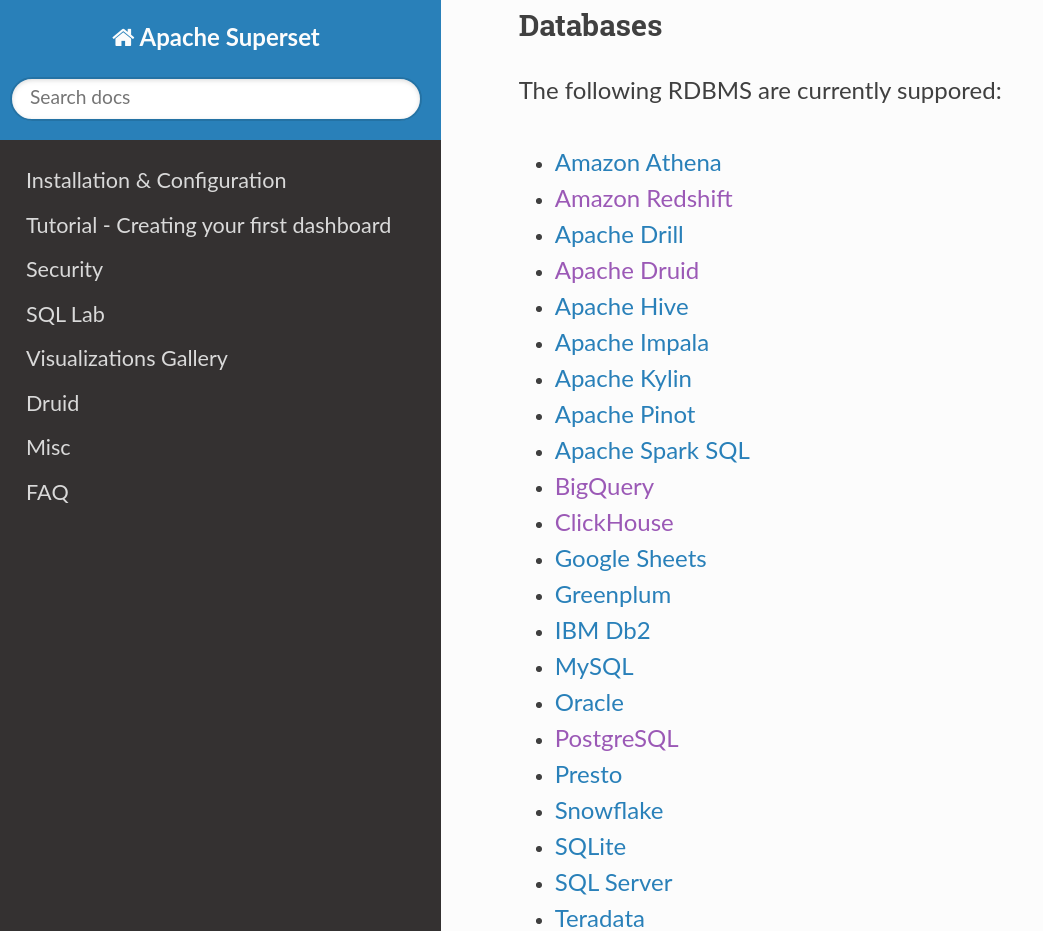
Apache Superset: business intelligence web application
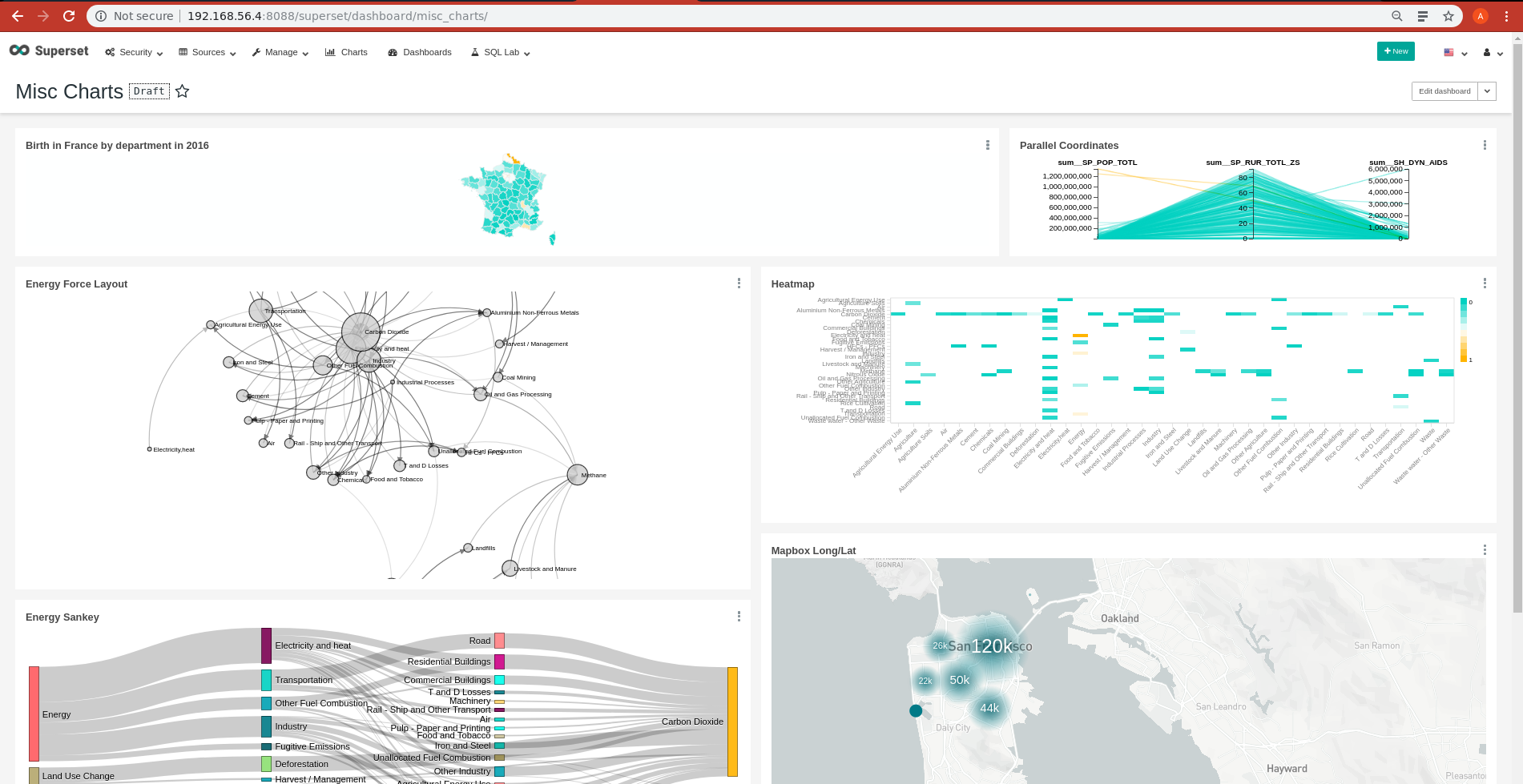
Apache Superset: RDBMS support
Installation de l’environnement pour le TP
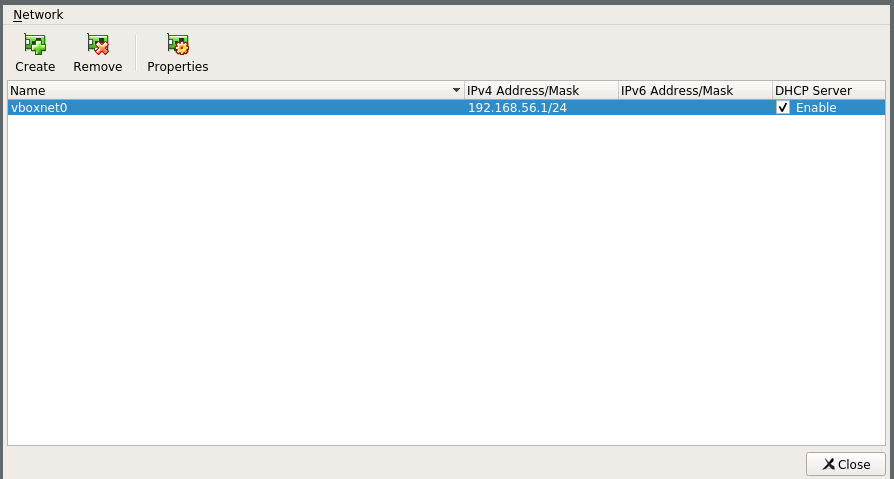
Configuration d’un reseau host-only via Virtualbox
Démarrez l’application Virtualbox
Verifiez/creez un réseau host-only vboxnet0 ("File/Host network Manager" …)
Configuration d’un reseau host-only via VBoxManage
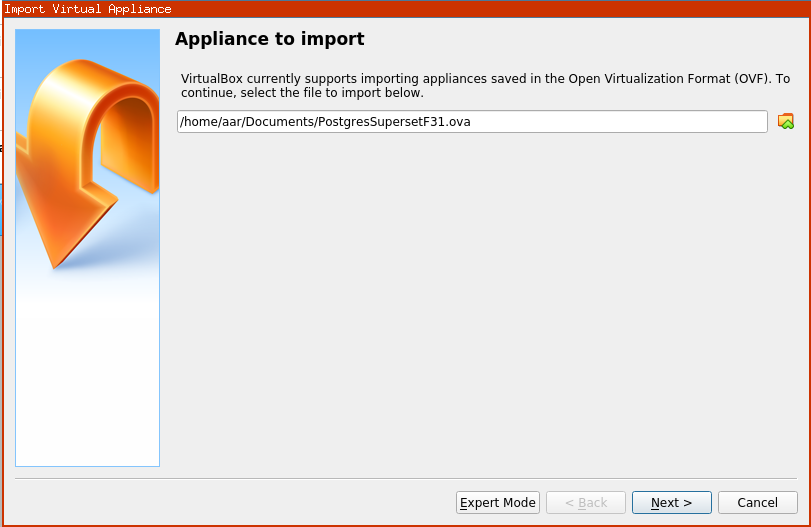
Telecharger la VM pour le tp
Importer la VM
File/Import appliance …
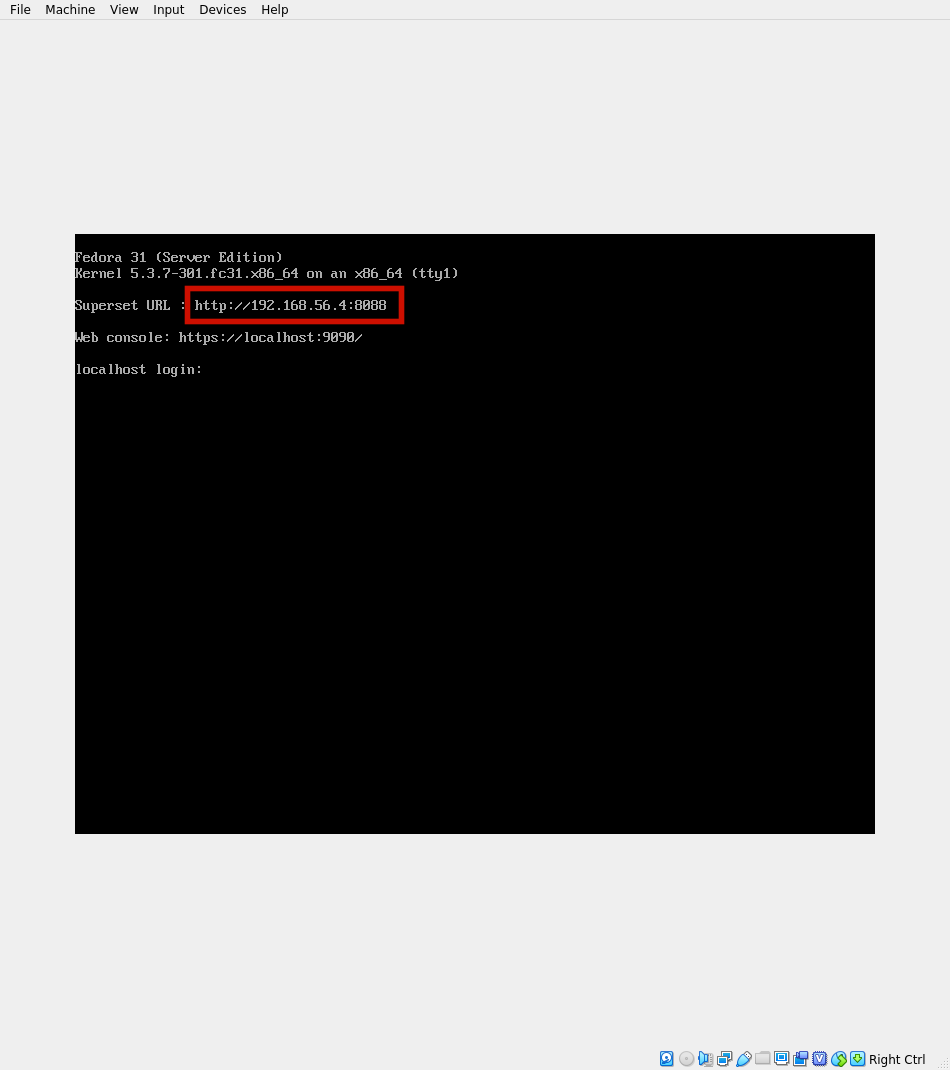
Demarer la VM
via le button Run/Start et noter l’URL pour acceder a Superset
Si votre vm ne demarre pas ou vous n’avez pas de IP, vous pouvez essayer quelques workarounds ici |
Connectez vous a Superset via votre navigateur
Username: admin Password: bigdatafuret
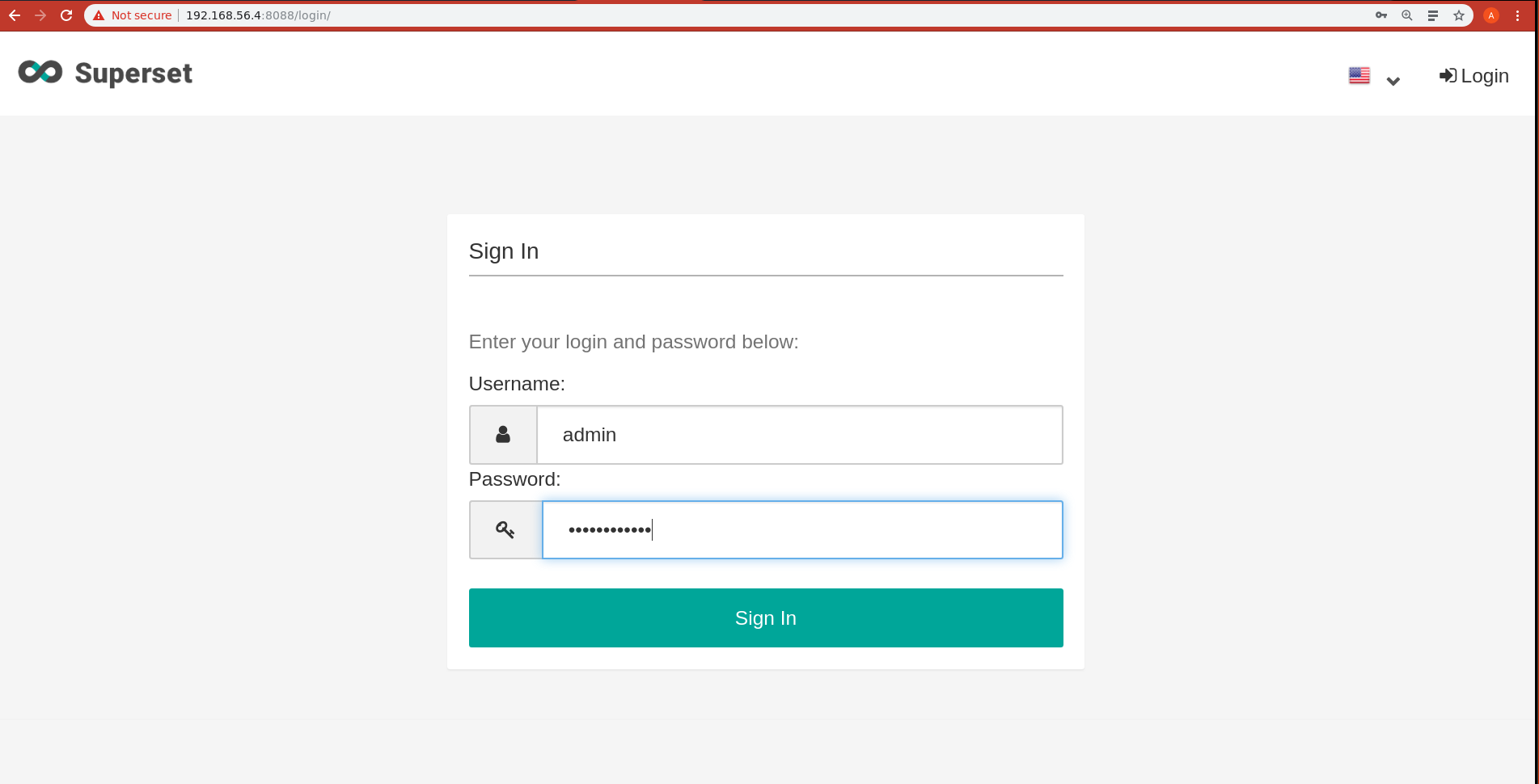
Ouvrez le SQLEditor
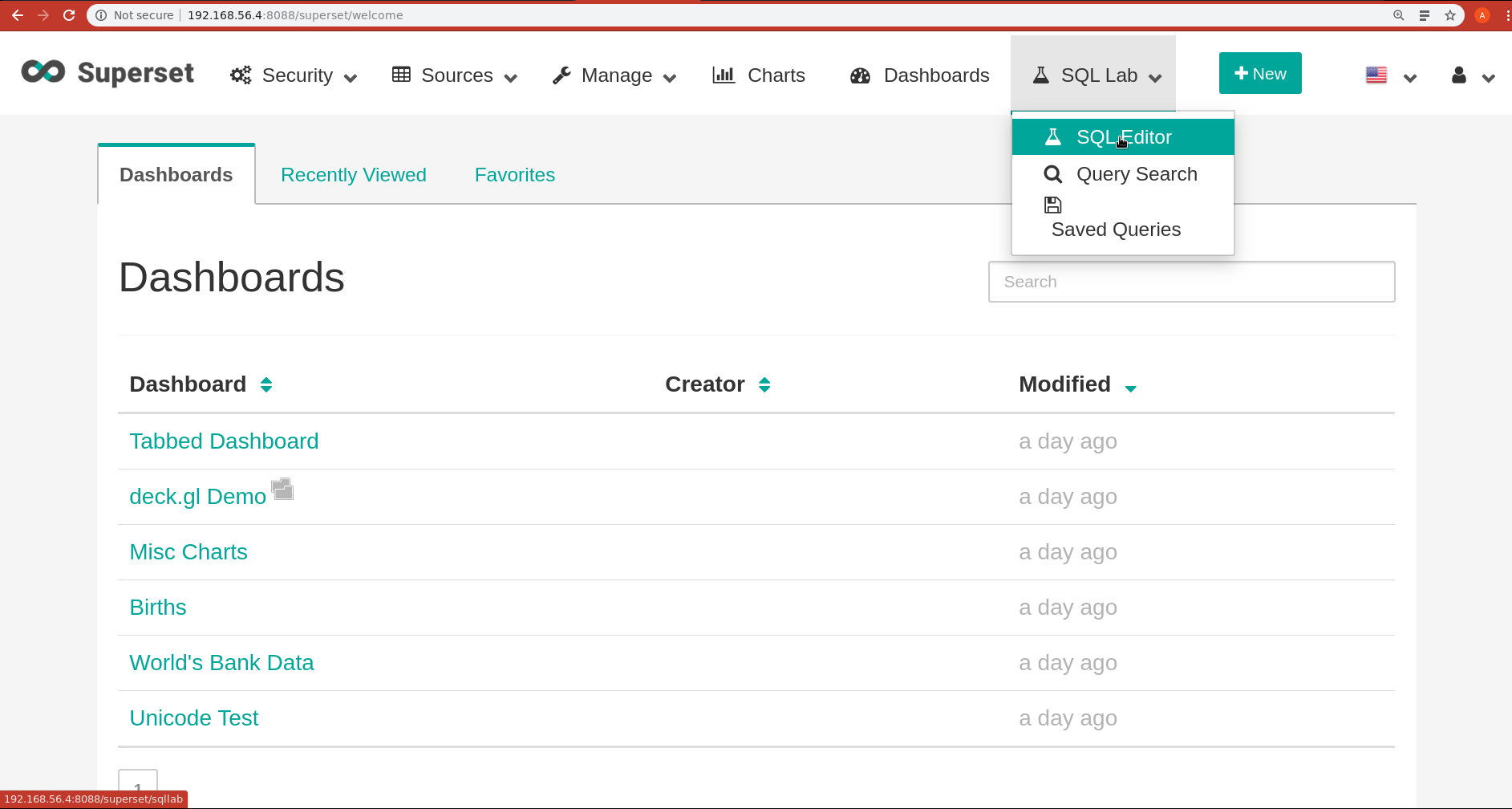
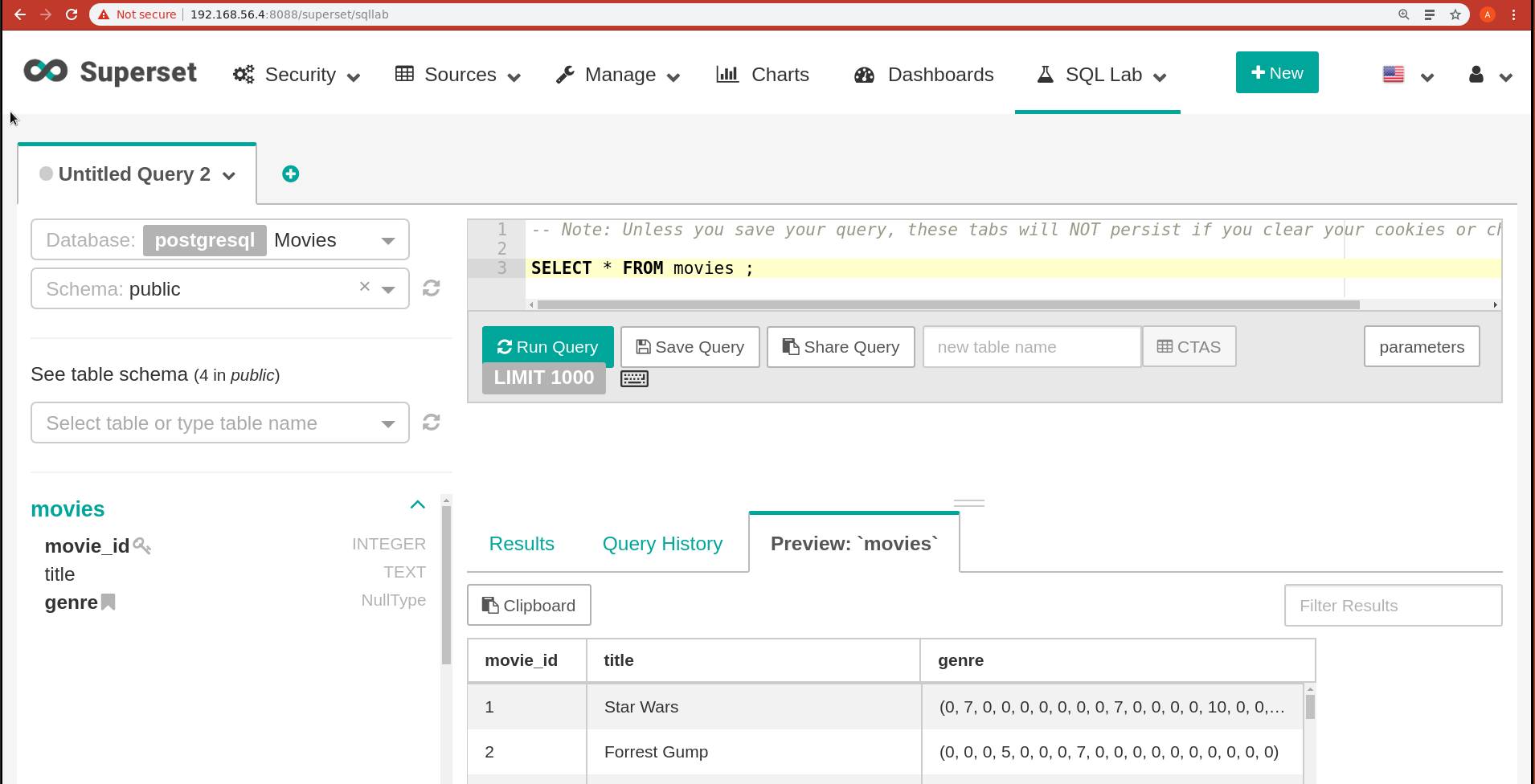
Dans le SQLEditor lancez une requete
Tester la requete _SELECT * FROM MOVIES_ (dans la Database Movies/ Schema: public.
Si vous avez eu des résultats, l'installation s'est bien passe, felicitations !
TP1: PostgreSQL Recherche et recommandation (1h)
Recherche et recommandation
Schéma (déjà créé)
Recherche
Recherche textuelle/patterns
Distance Levenshtein
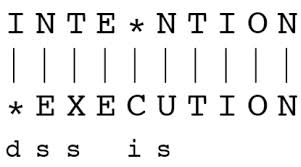
Opérations: Substitute, Insert, Delete
Distance Levenshtein : nb minimal d’opérations
Distance Levenshtein
N-gram
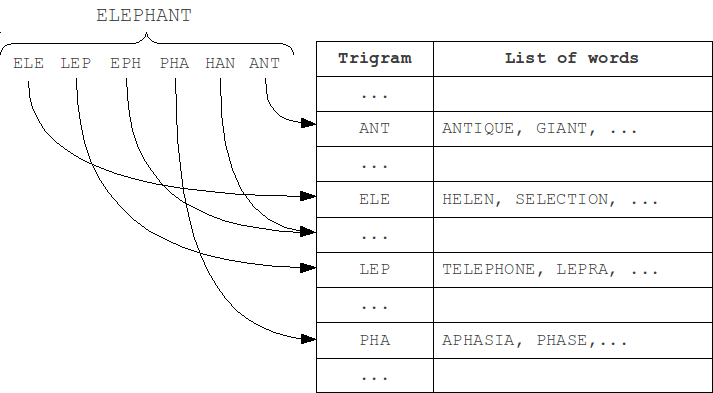
N-gram, similarity search
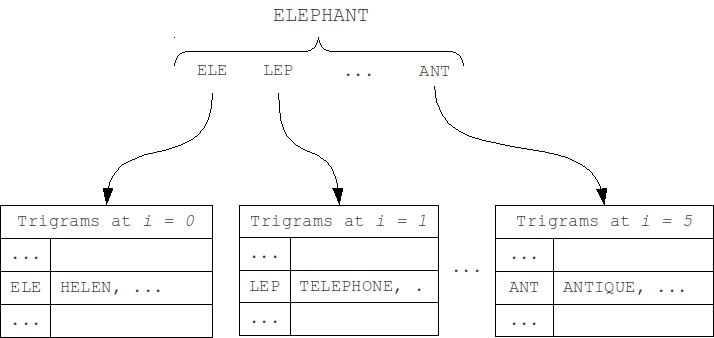
N-gram, similarity search (%)
Full text search
Full text search
Full text search
Recherche phonétique
Recherche phonétique
Search
Recherche "graph"
Trouvez le graph des acteurs connectees a Tom Hanks (ont deja joue dans un film avec l’acteur ou bien il y a un chemin films/acteurs qui mene a l’acteur)
Hint: vous pouvez utiliser les Common Table Expressions
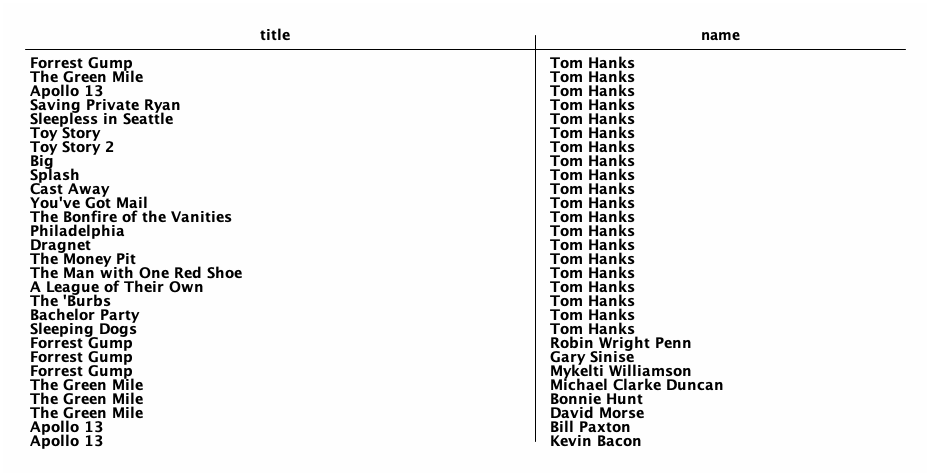
Recherche multi-dimensionnelle
Recherche multi-dimensionnelle
Recherche multi-dimensionnelle
Recherche multi-dimensionnelle
Troubleshoot VM freeze
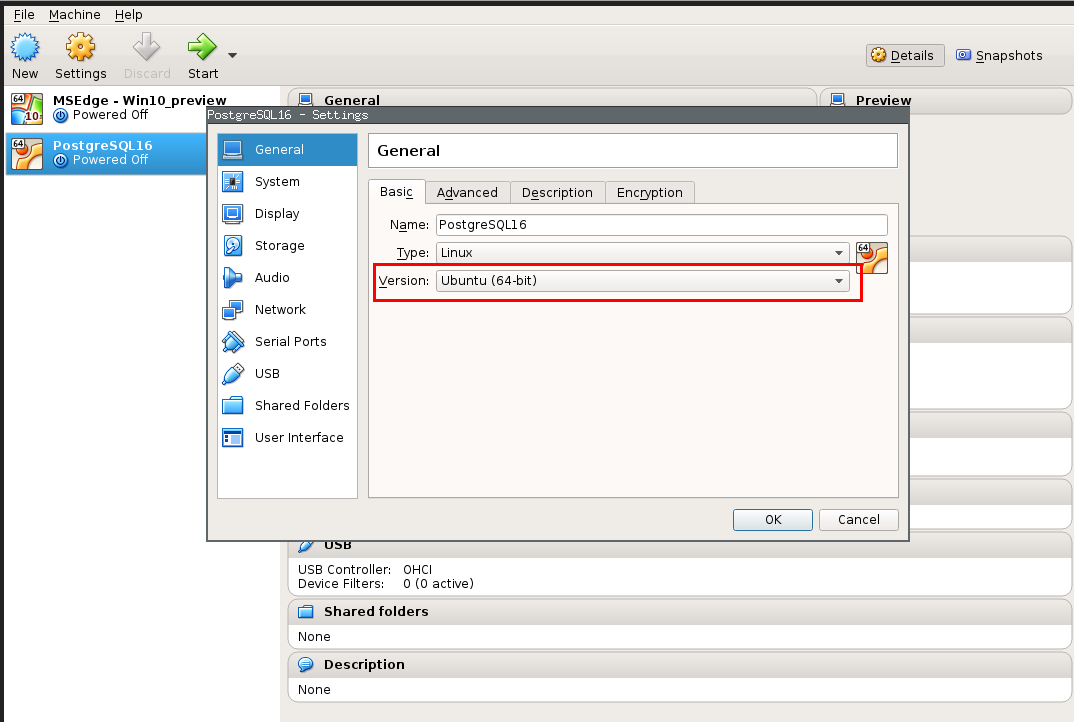
VM hangs at *Loading initial ramdisk … *
check VM type ⇒ Version Ubuntu(64 git)
Troubleshoot no IP
check DHCP settings
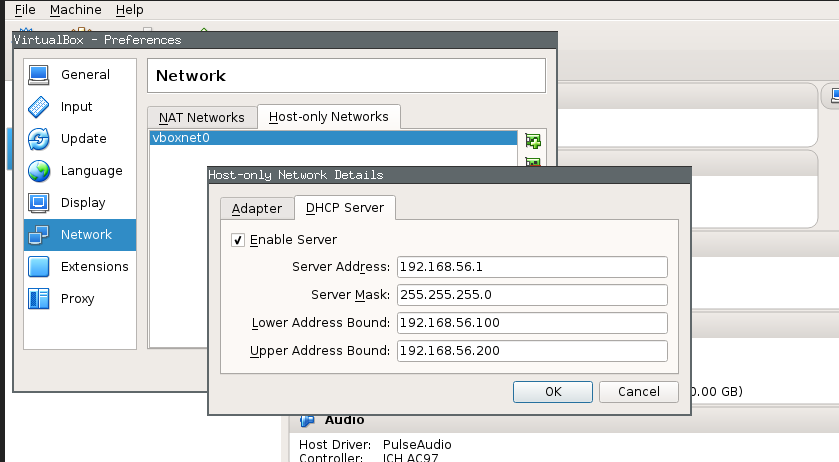
Troubleshoot no IP
Installation en détail
Create index
Ressources:



Ressources:
Other
Master/Slave
Multi - Master replication with DRBD
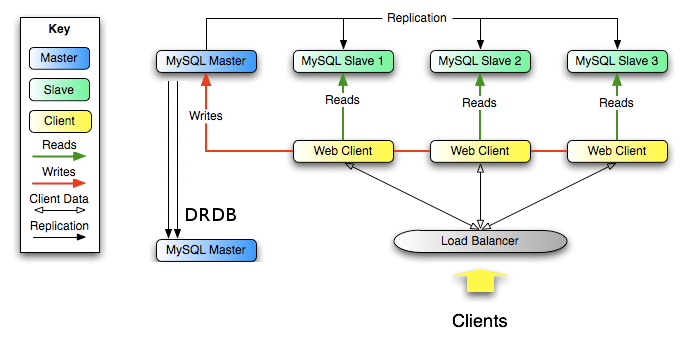
DRBD mirroring
mirroring a linux partition over IP (sync/async)
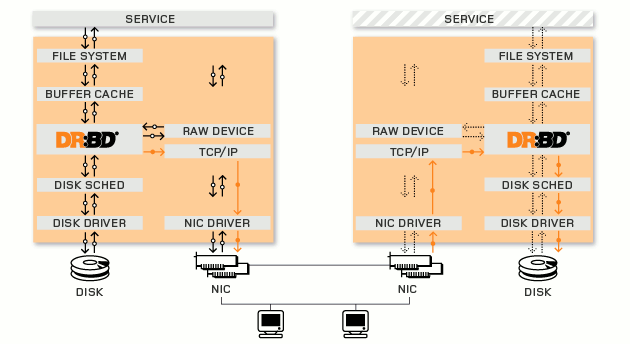
DRBD HA
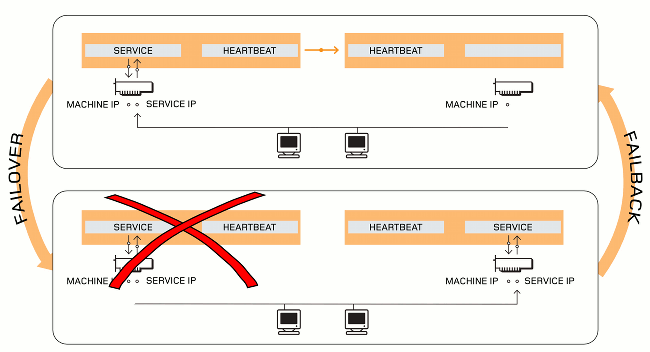
DRBD recovery
Transition to NoSQL
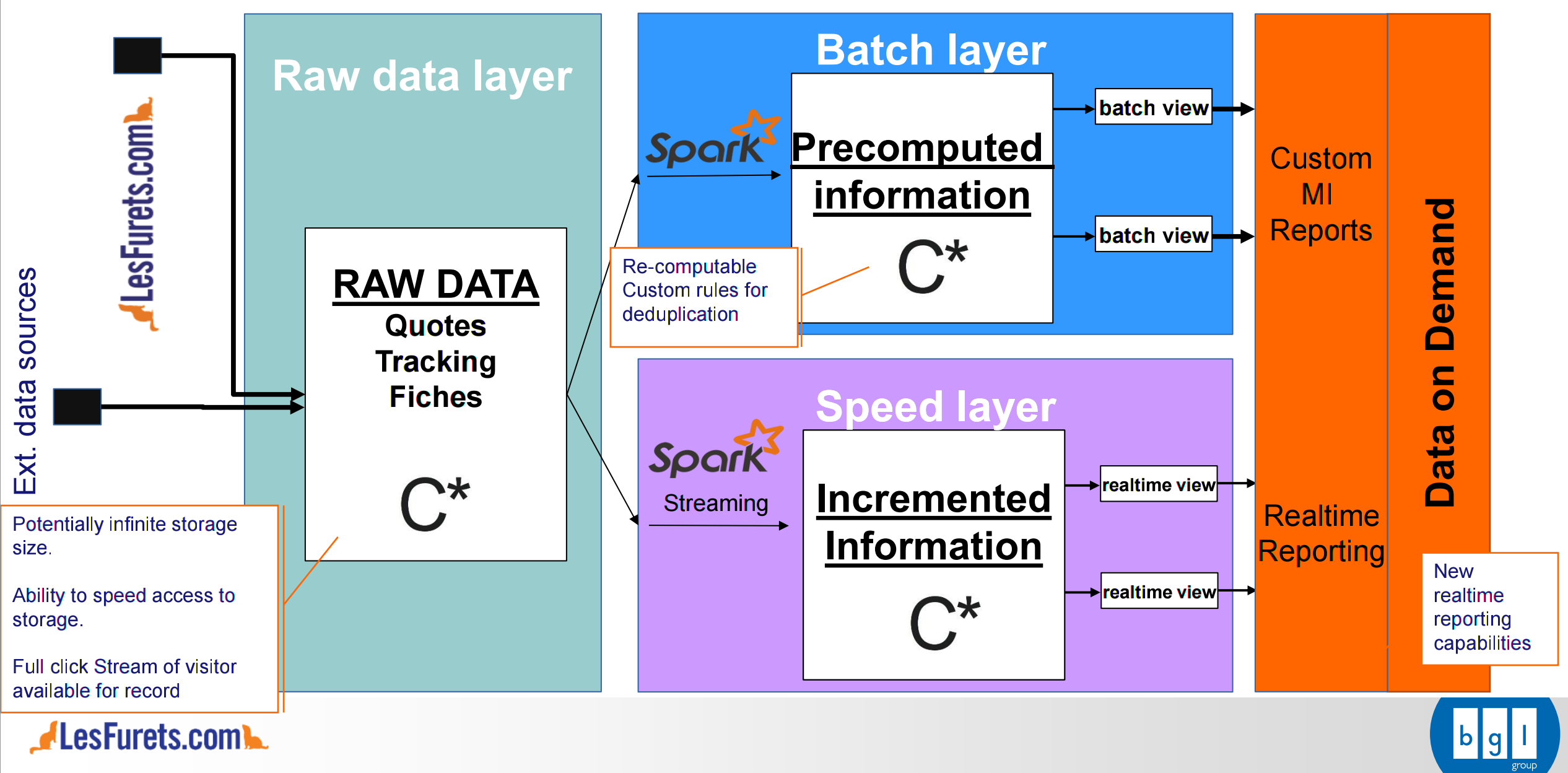
Lambda architecture
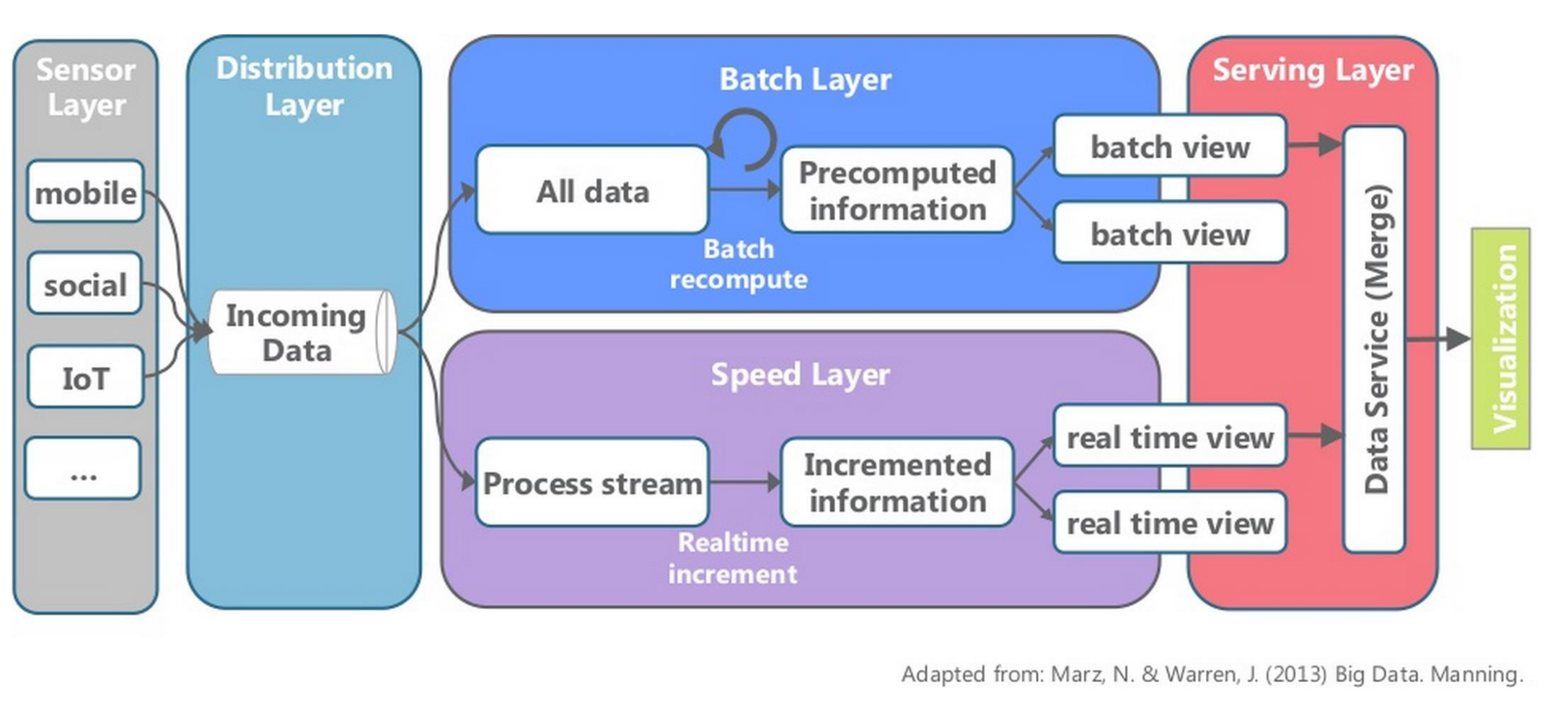
Lambda architecture @LesFurets
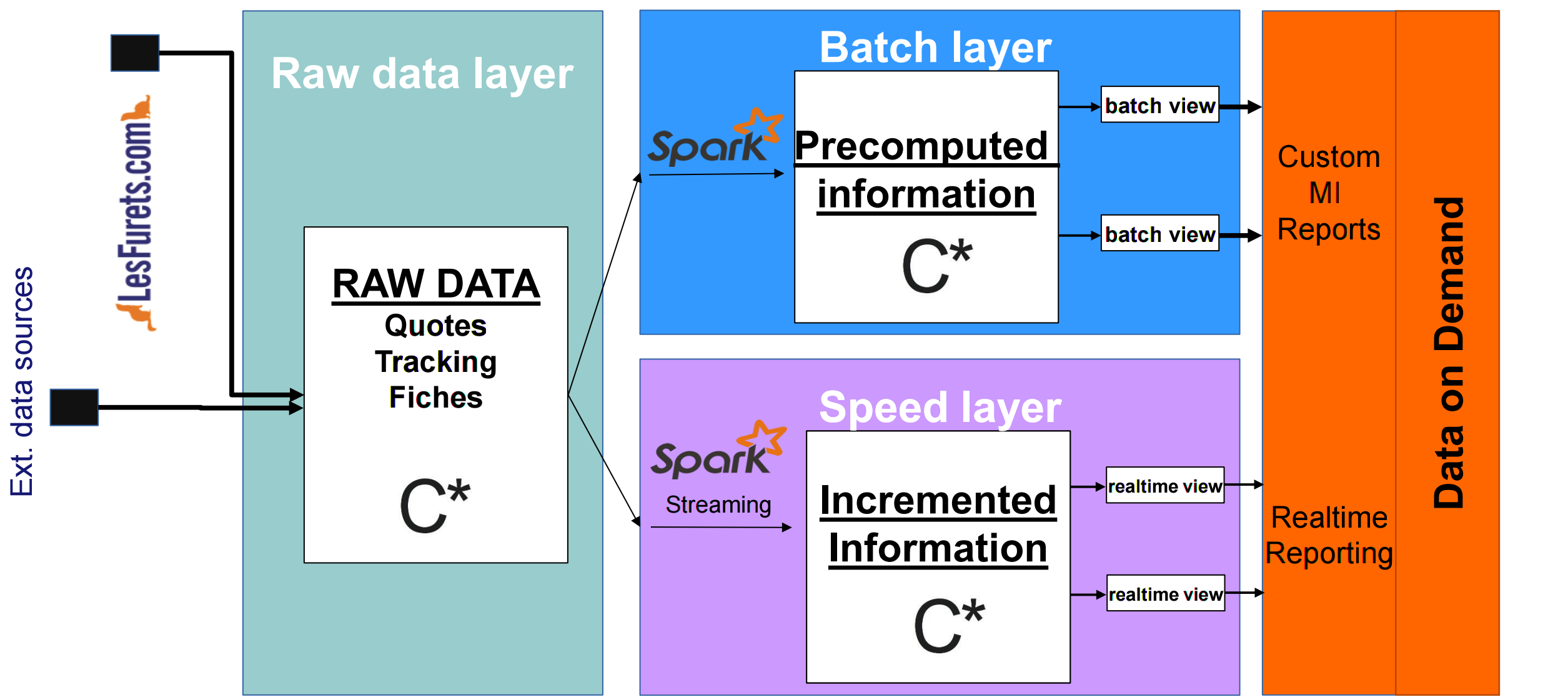
Lambda architecture @LesFurets