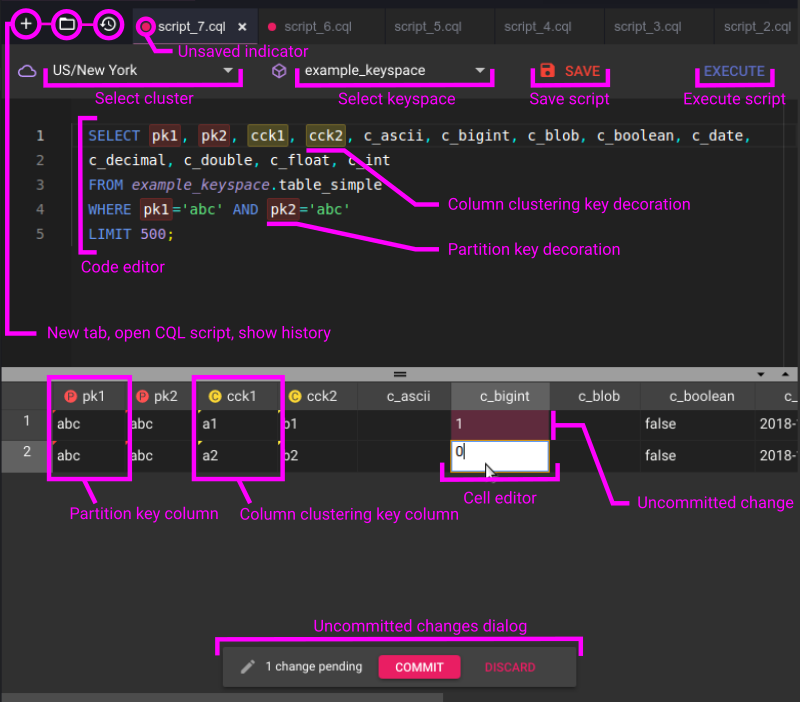
CREATE KEYSPACE temperature
WITH replication =
{'class': 'SimpleTopologyStrategy', 'replication_factor':'2'};Introduction to Apache Cassandra
Plan
Motivation
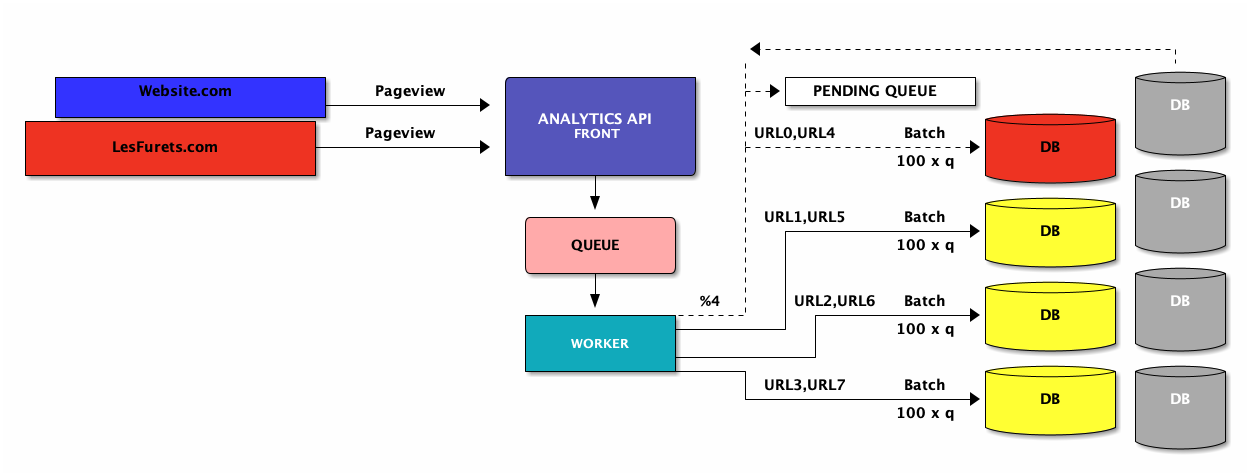
do I build new features for customers?
or just dealing with reading/writting the data?
What went wrong?
Plan
Apache Cassandra
Apache Cassandra
Open source, distributed database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It offers robust support for clusters spanning multiple datacenters, with asynchronous masterless replication allowing low latency operations for all clients.
Apache Cassandra
Apache Cassandra users

source: https://codingjam.it/
Cassandra terminology
Cassandra ring

Gossip
Cassandra replicas

Cassandra node failure

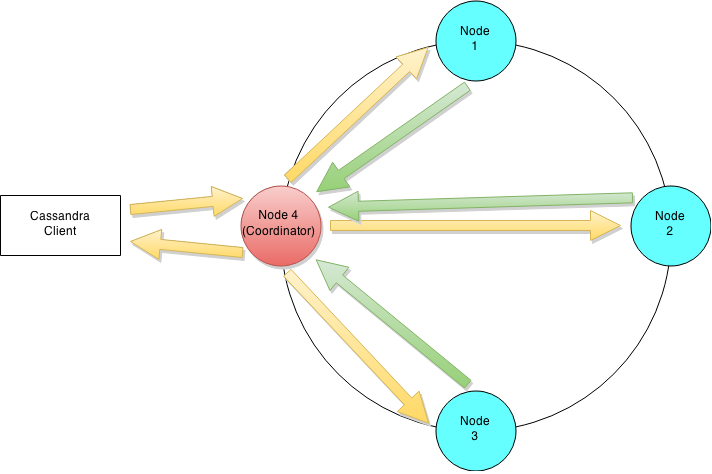
Query
Plan
Cassandra data model
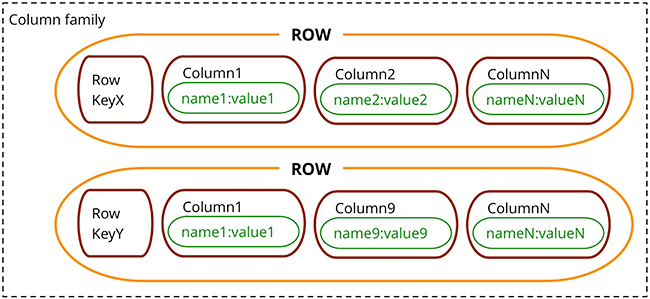
Stores data in tables/column families as rows that have many columns associated to a row key
Map<RowKey, SortedMap<ColumnKey, ColumnValue>>
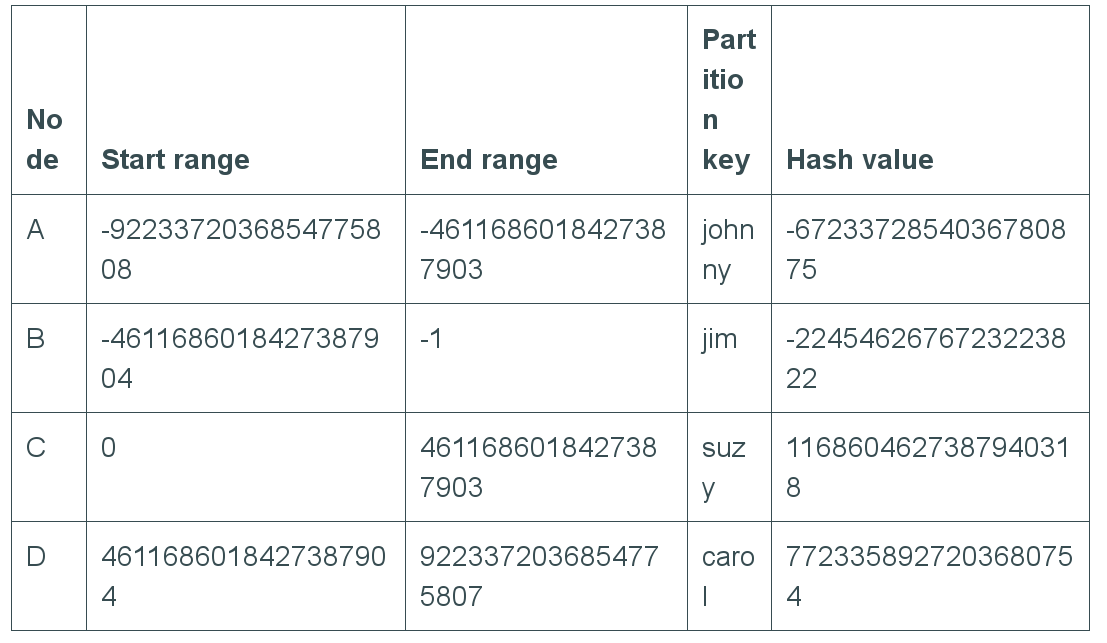
Data partitioning
Mapping data to nodes
Consistent Hashing
Partitioner
Murmur3Partitionner
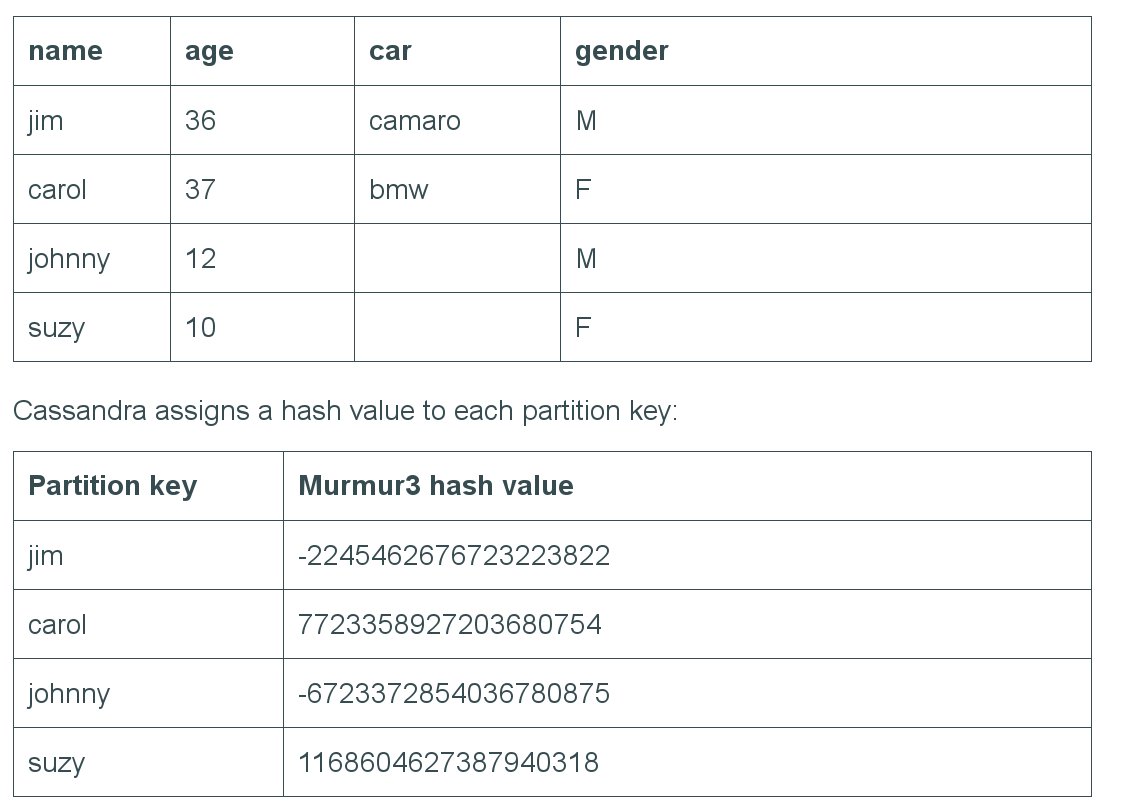
Consistent Hashing: mapping
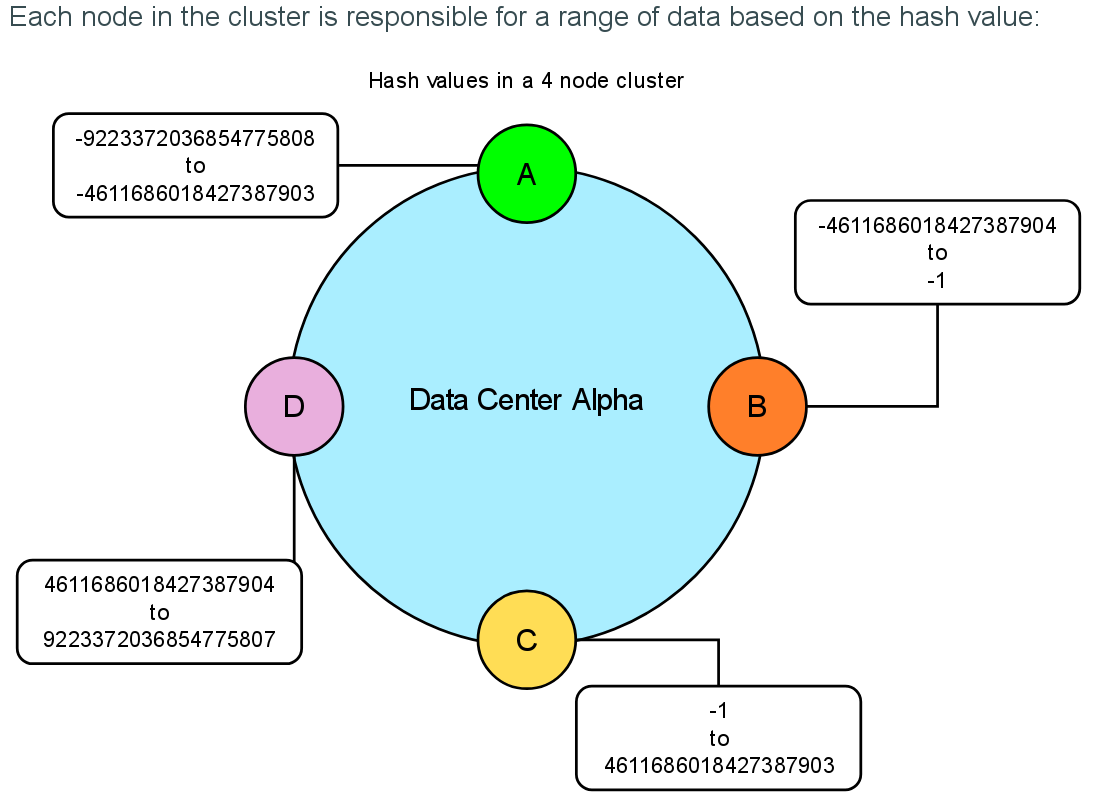
Consistent Hashing: mapping
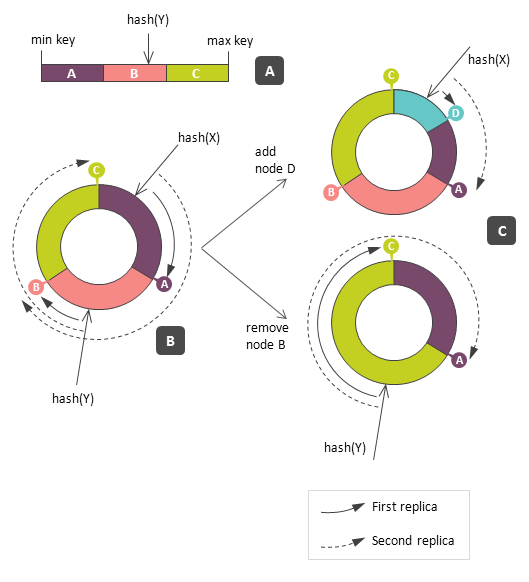
Data Replication
Topology informations: Snitches
Replication strategies
Replication strategies
SimpleReplicationStrategy
NetworkTopologyStrategy
CREATE KEYSPACE lesfurets
WITH replication =
{'class': 'NetworkTopologyStrategy', 'RBX': 2,'GRV':2,'LF':1};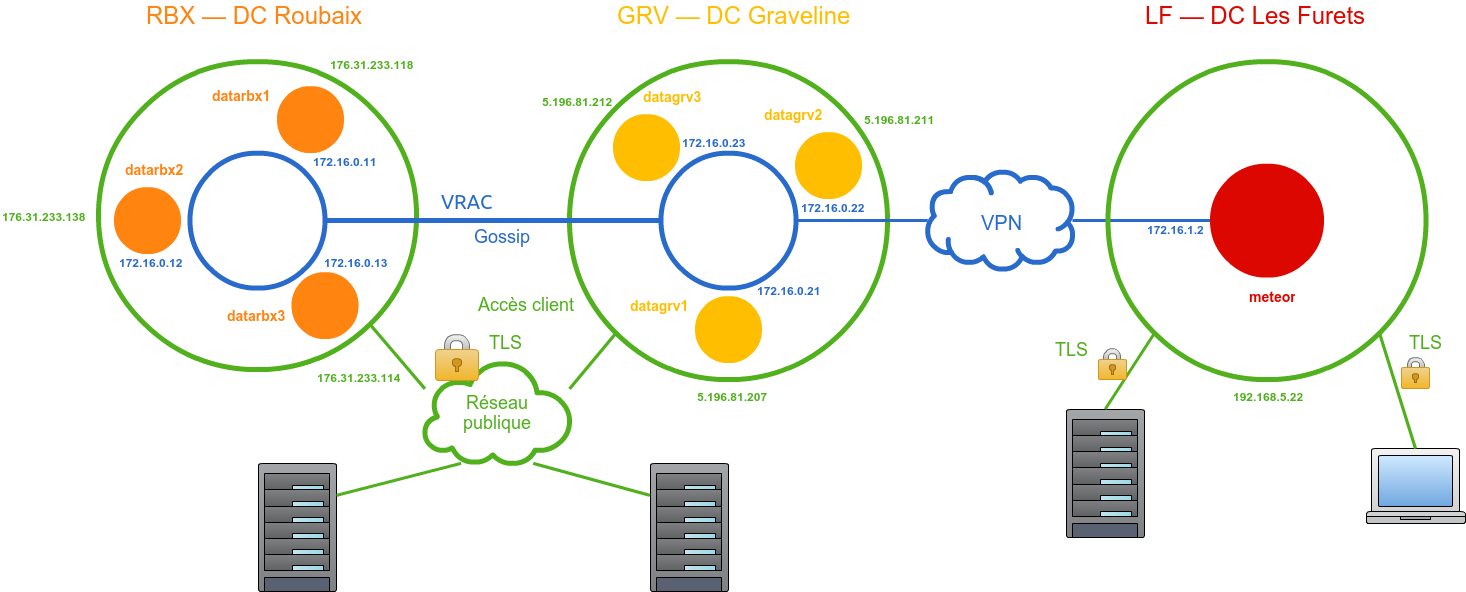
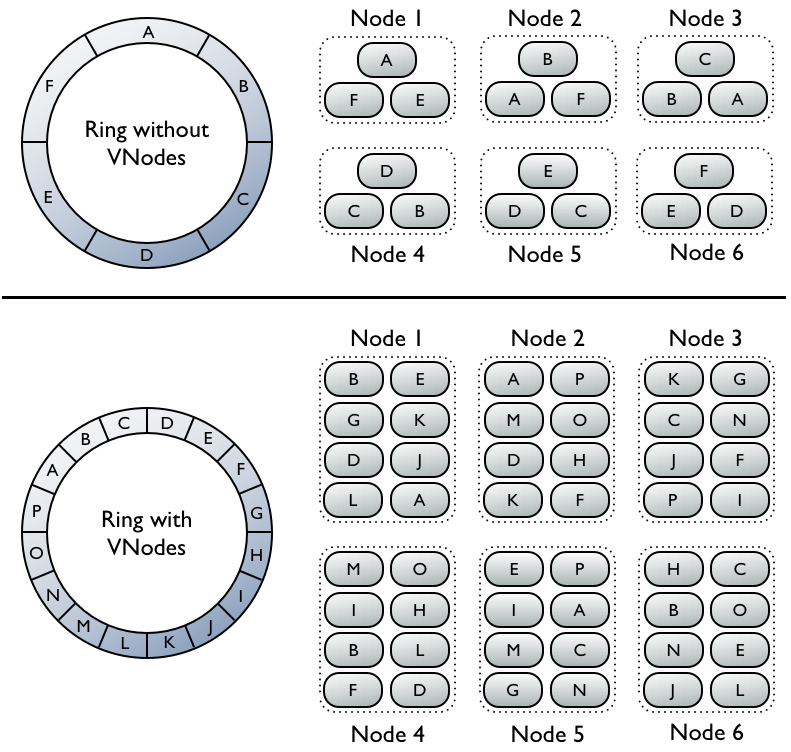
Token allocation
Virtual nodes (VNodes)
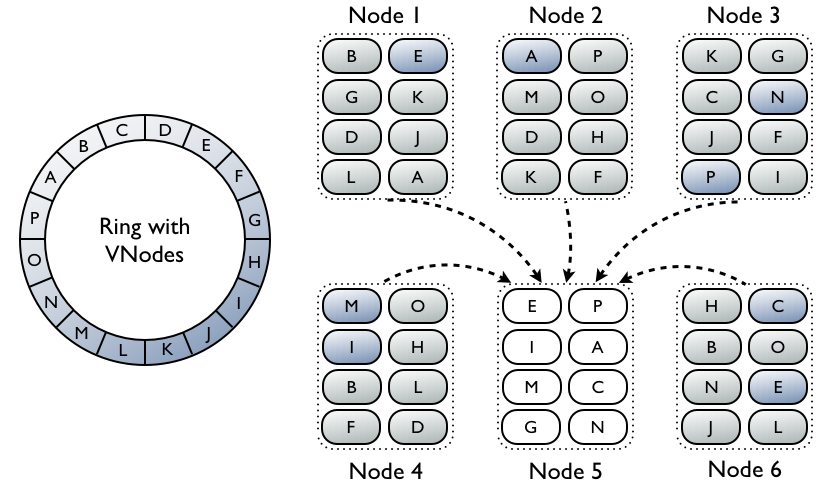
VNodes: remapping keys
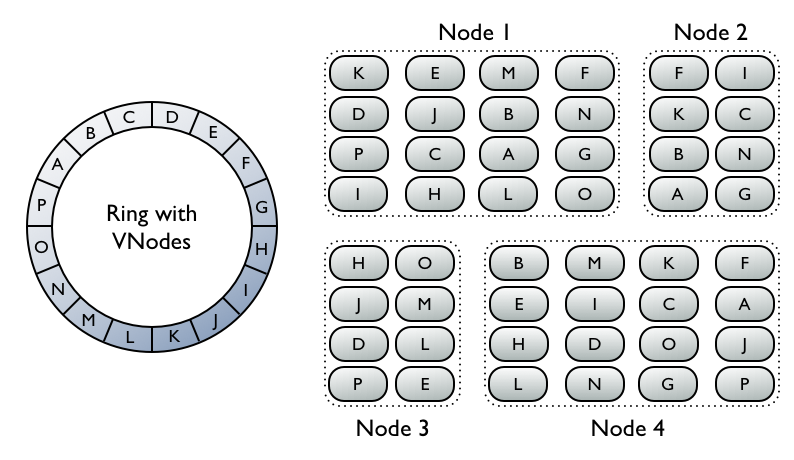
VNodes: heteregenous clusters
Plan
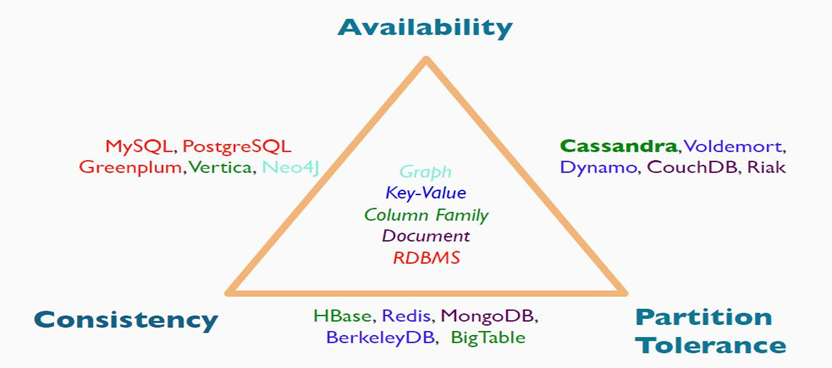
Properties of distributed systems
Consistency
a read returns the most recent write
eventually consistent : guarantee that the system will evolve in a consistent state
provided there are no new updates, all nodes/replicas will eventually return the last updated value (~DNS)
Availability
a non-failing node will return a reasonable response (no error or timeout)

Partition tolerance
ability to function (return a response, error, timeout) when network partitions occur

Partition tolerance
CAP theorem
BASE
Cassandra consistency
Consistency Level (CL)
Which consistency level ?
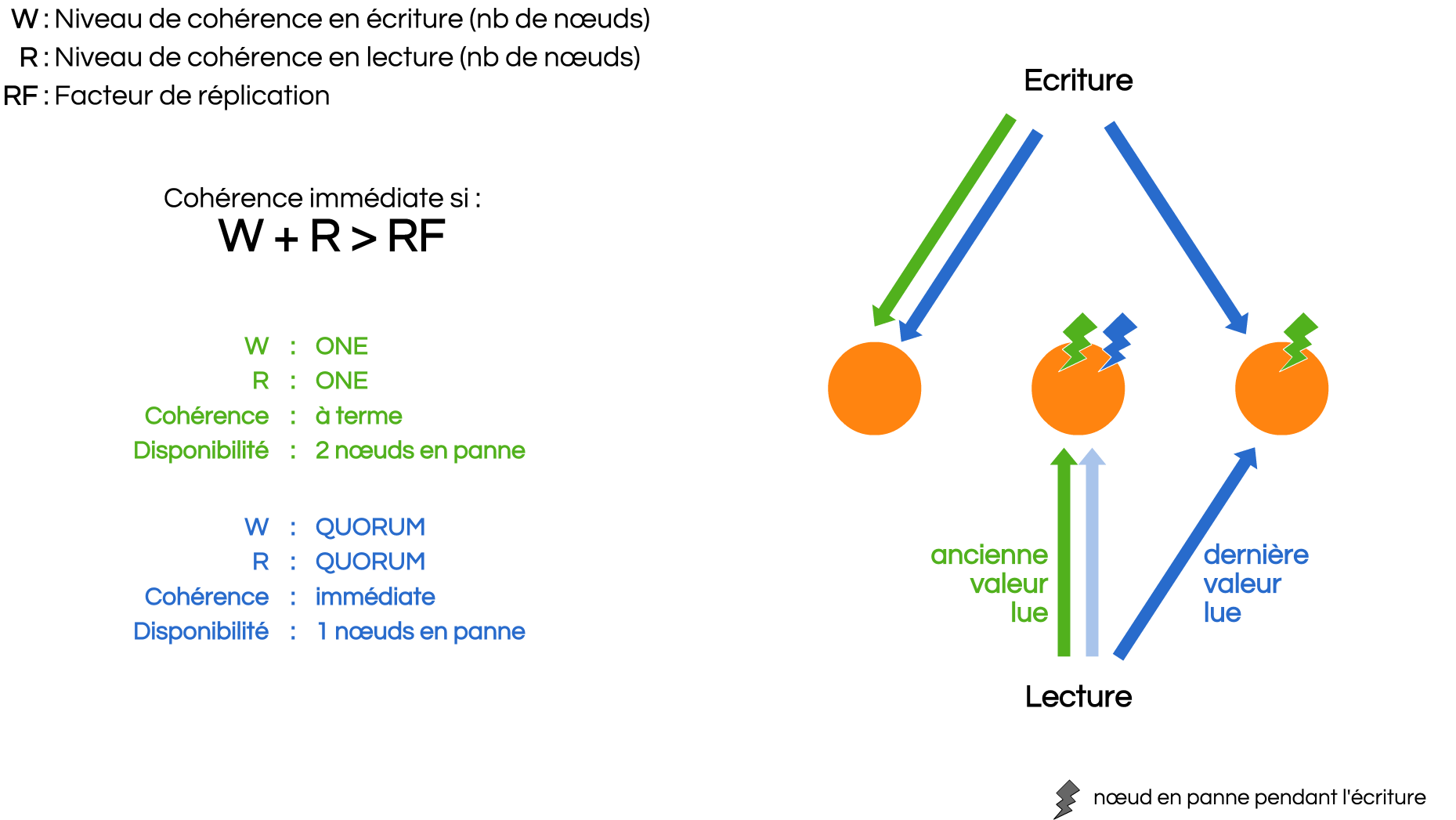
Consistency mechanisms
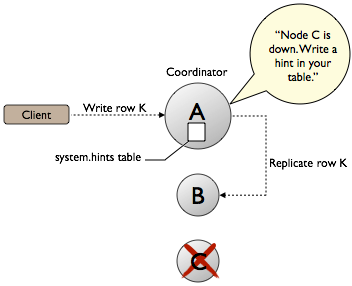
Hinted handoff
ONE/QUORUM vs ANY (any node may ACK even if not a replica)
if one/more replica(s) are down ⇒ hinted handoff
Read repairs
Read repairs ONE

Read repairs QUORUM

Read repairs QUORUM DC

Anti-entropy repair (nodetool repair)
Durability
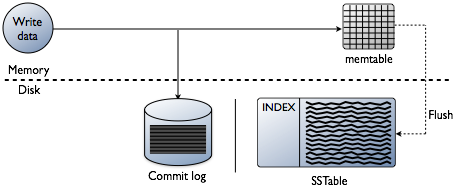
Cassandra write path
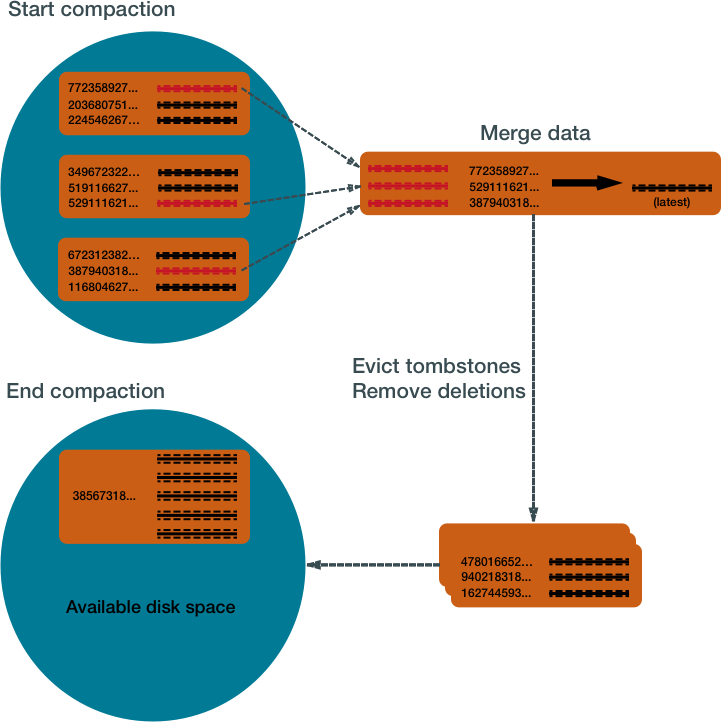
Cassandra compactions
collects all versions of each unique row
assembles one complete row (up-to-date)
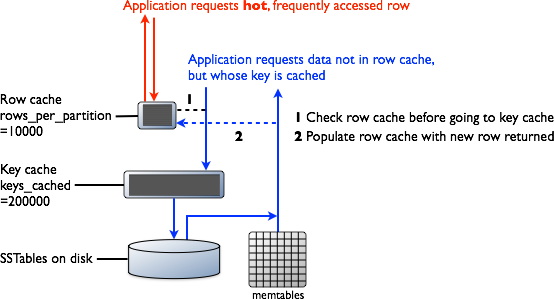
Cassandra read path (caches)
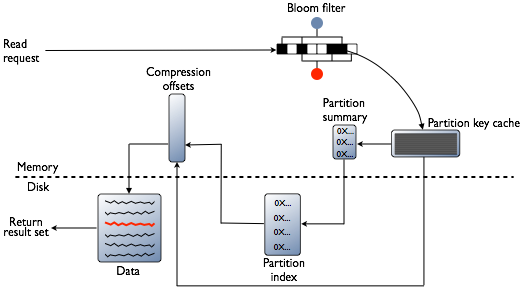
Cassandra read path (disk)
More info
Plan
Practice: Tune consistency in Apache Cassandra
Cassandra cluster manager
Nodetool
CQLSh
VSCODE plugin