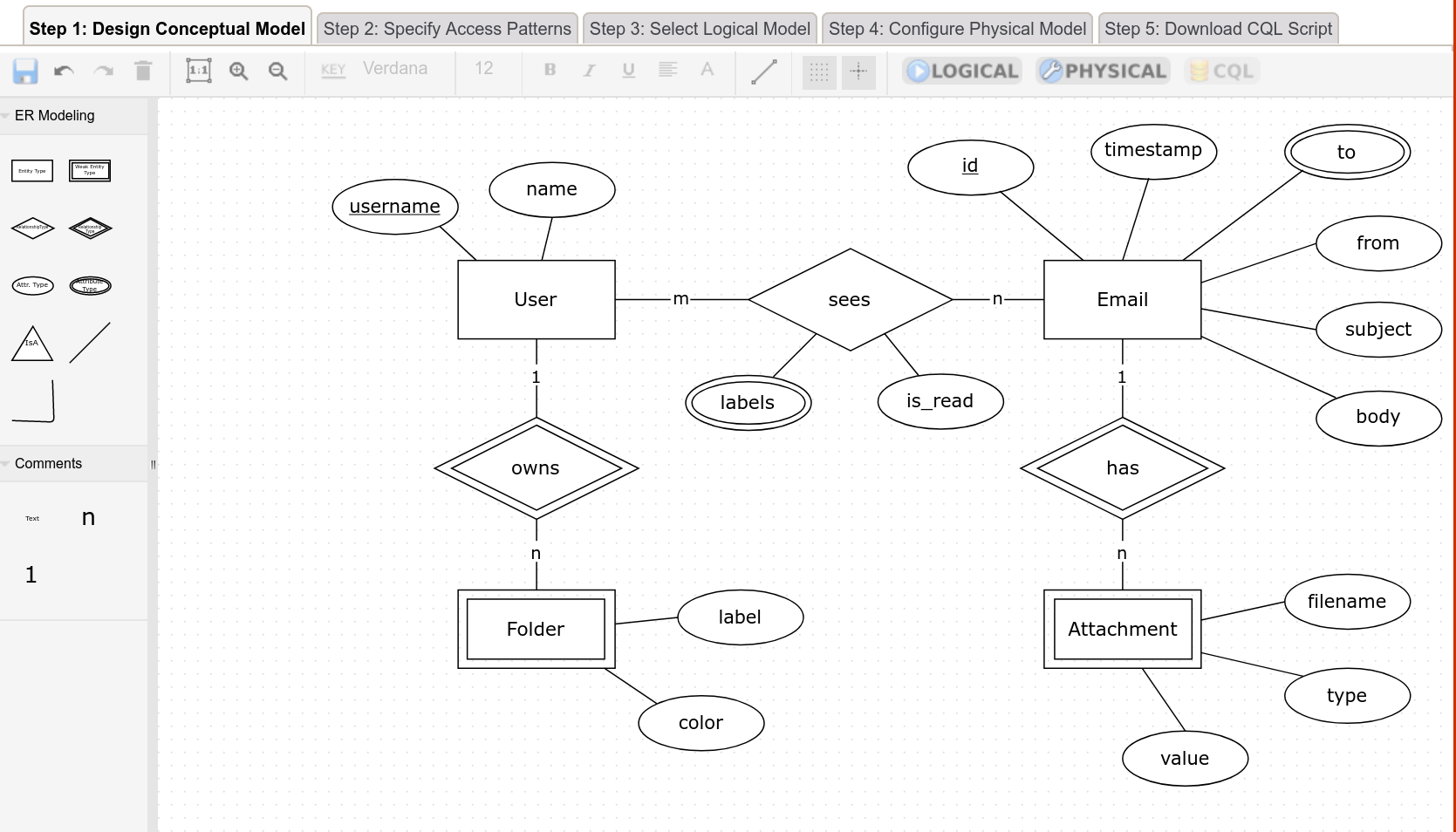
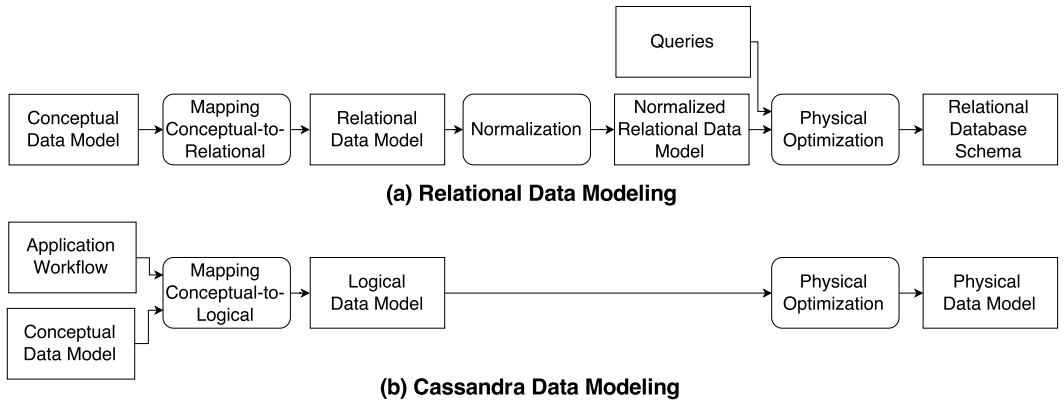
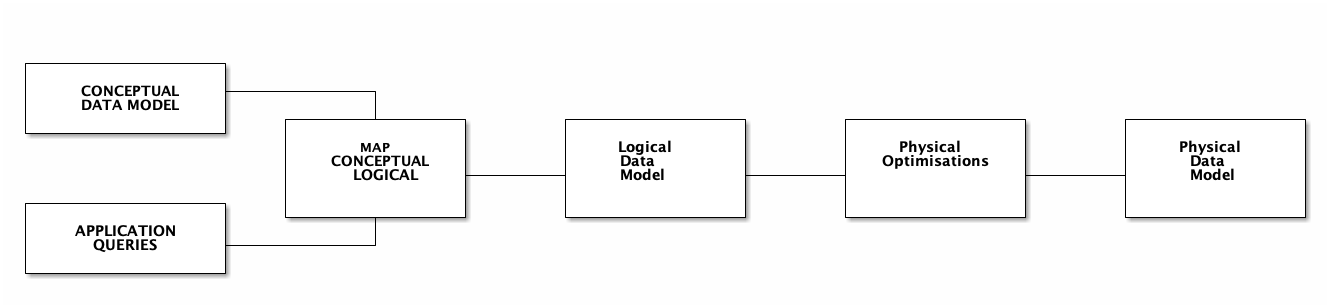
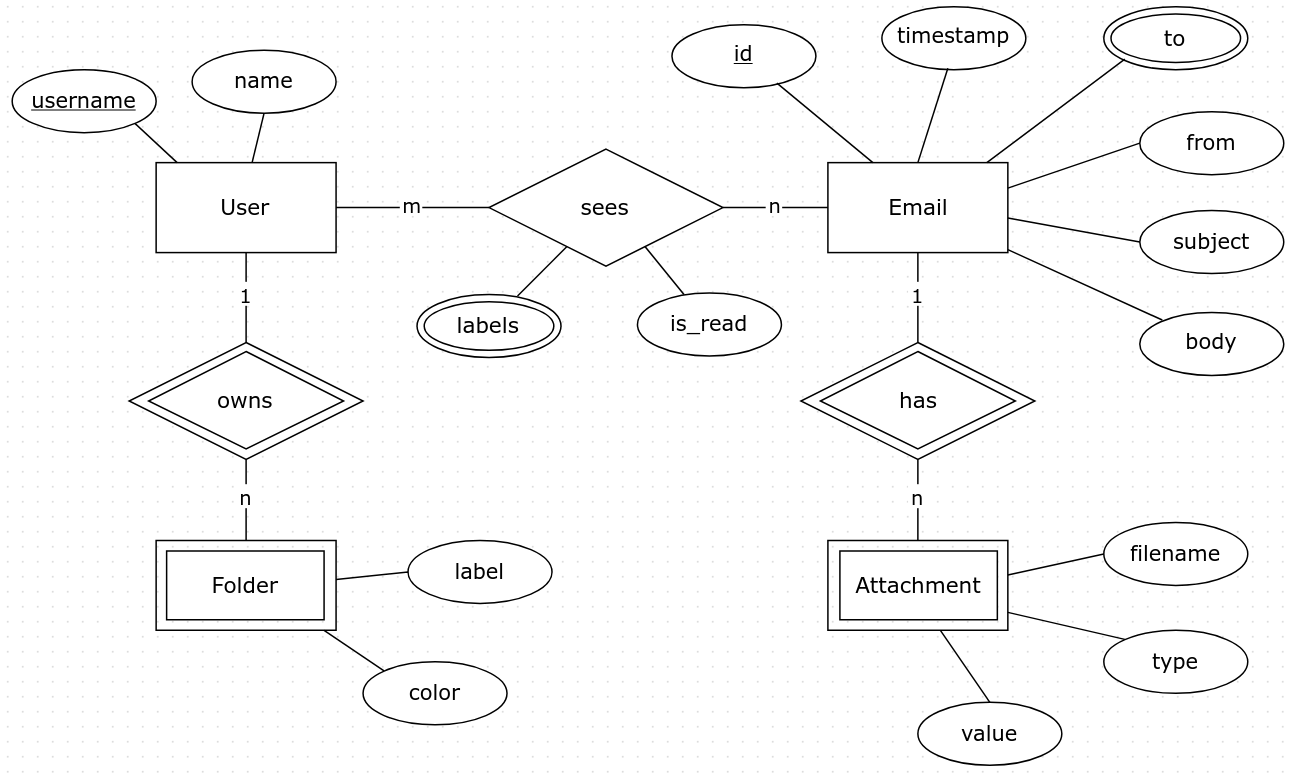
{
"partition" : {
"key" : [ "Red Bull" ],
"position" : 0
},
"rows" : [
{
"type" : "static_block",
"position" : 87,
"cells" : [
{ "name" : "location", "value" : "FR", "tstamp" : "2017-11-15T01:53:29.914293Z" },
{ "name" : "manager", "value" : "Christian Horner", "tstamp" : "2017-11-14T20:04:07.780008Z" }
]
},
{
"type" : "row",
"position" : 87,
"clustering" : [ "Grosjean" ],
"liveness_info" : { "tstamp" : "2017-11-15T01:53:29.914293Z" },
"cells" : [
{ "name" : "nationality", "value" : "French" }
]
},
{
"type" : "row",
"position" : 87,
"clustering" : [ "Kvyat" ],
"liveness_info" : { "tstamp" : "2017-11-15T01:51:53.491421Z" },
"cells" : [
{ "name" : "nationality", "value" : "Russian" },
{ "name" : "position", "value" : "driver", "tstamp" : "2017-11-14T21:35:44.148500Z" }
]
},
{
"type" : "row",
"position" : 124,
"clustering" : [ "Ricciardo" ],
"liveness_info" : { "tstamp" : "2017-11-14T21:35:40.564459Z" },
"cells" : [
{ "name" : "nationality", "value" : "Australian" },
{ "name" : "position", "value" : "driver" }
]
}
]
}