mpirun -np 4 simple1Introduction to Apache Spark
Andrei Arion, LesFurets.com, tp-bigdata@lesfurets.com
Plan
Context: Distributed programming
Spark data model
Spark programming
Spark execution model
Spark cluster
Spark ecosystem
Plan
Distributed programming models
Data flow models (MapReduce, Apache Spark, Apache Flink, Apache Beam, Google Dataflow)
Scale-Up / Scale-Out
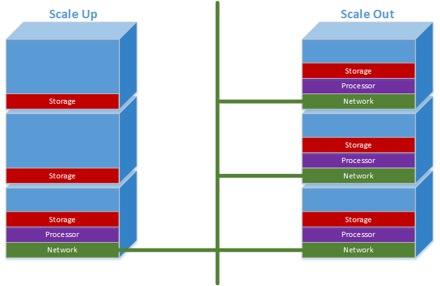
Scale-Up: "single powerfull computer"($$$)
Scale-Out: network of commodity hardware
Distributed programming
unreliable network
hardware/software failures
synchronous ⇒ asynchronous
consistency and ordering are expensive
time
(Distributed) Databases vs Distributed programming
Databases: used as a shared ressource
data persistence
standardized access to data (API / query language)
guaranteed properties (CAP) via sharding and replication
Distributed programming:
express general computation
pipelines of tasks
Databases vs Distributed programming
More and more difficult to distinguish between them !
Distributed Databases:
User Defines Types, User Defined Functions, MapReduce support
Distributed programming frameworks:
SQL like access (SparkSQL, Dataframes on top of RDDs), DSLs as query languages, DB inspired optimizations
Data persistence, partitioning and replication (MEMORY_ONLY_2)
Distributed programming models
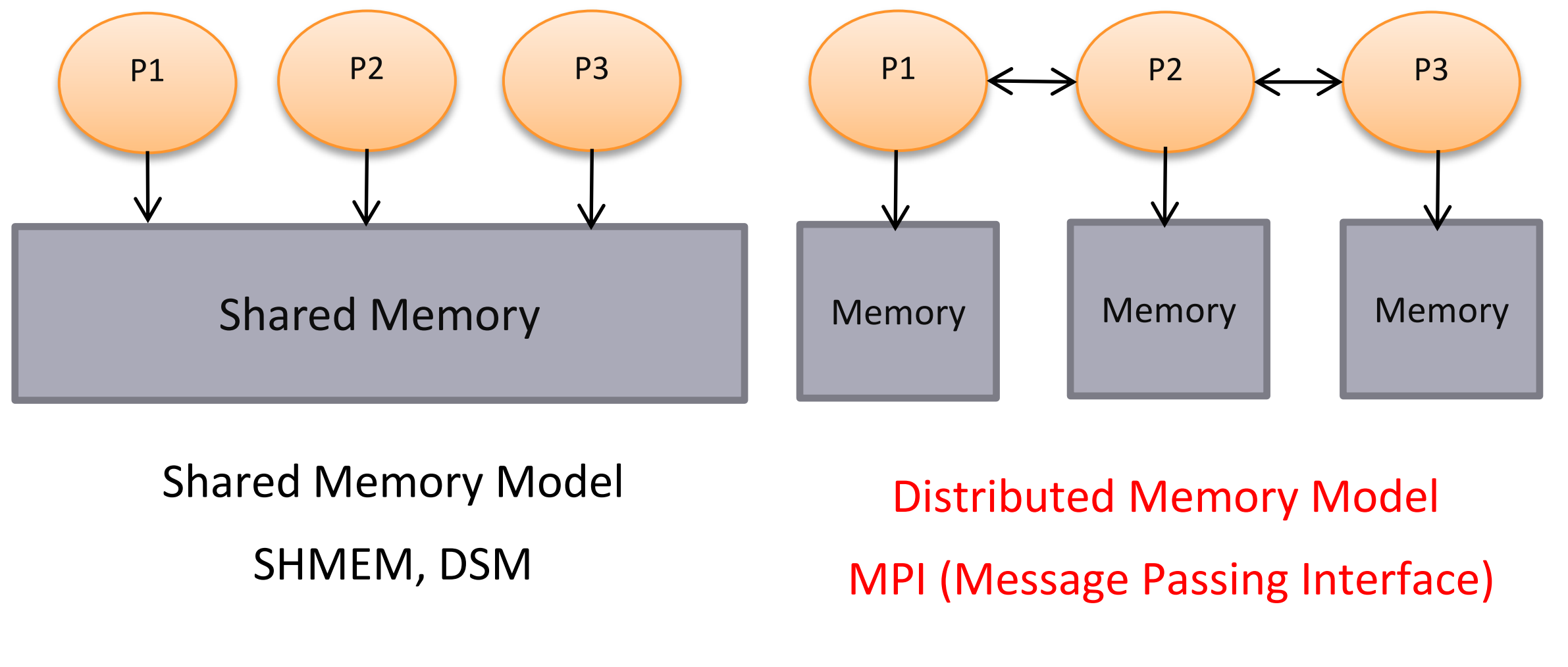
Shared Memory / Shared Nothing
Von Neuman architecture ⇒ instructions executed sequentially by a worker (CPU) and data does not move
Shared Memory
multiple workers (CPU/Cores) executing computations in parallel
use locks, semaphores and monitors to synchronise access to the shared memory
Shared Nothing: Divide&Conquer (ForkJoin/ScatterGather)
distribute data
distribute the computations ( the code)
launch and manage parallel computations
collect results
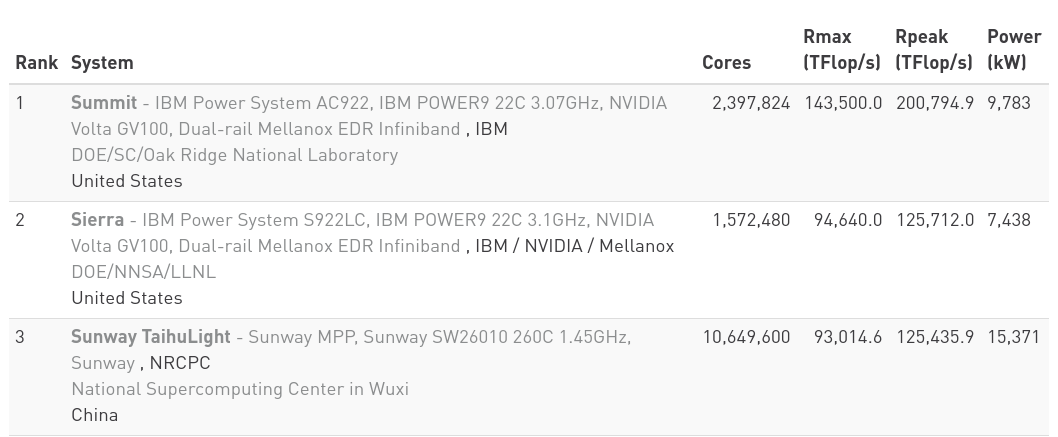
Shared Nothing hegemony
Since 2006, no Shared-Memory system in the first 10 places on TOP500
Share Nothing Architectures
Message Passing (MPI, Actors, CSP)
DataFlow systems
Share Nothing Architectures → Message Passing
Computing grid : MPI (message passing interface) (1993-2012)
launch the same code on multiple nodes
// determining who am I
int myrank;
MPI_Comm_rank(MPI_COMM_WORLD, &myrank); (1)
// determining who are they :
int nprocs;
MPI_Comm_size(MPI_COMM_WORLD, &nprocs); (2)
// sending messages
MPI_Send(buffer, count, datatype, destination, tag, MPI_COMM_WORLD); (3)
//receiving Messages
MPI_Recv(buffer, maxcount, datatype, source, tag, MPI_COMM_WORLD, &status); (4)"Traditional" distributed programming
Low level
manual data decomposition
manual load balancing
difficult to do at scale:
how to efficiently split data/code across nodes?
must consider network & data locality
how to deal with failures? (inevitable at scale)
The Present: Data flow models
Restrict the programming interface so that the system can do more automatically
Express jobs as graphs of high-level operators
System picks how to split each operator into tasks and where to run each task
Tasks executed on workers as soon as soon as input available
Data flow models: Map-Reduce
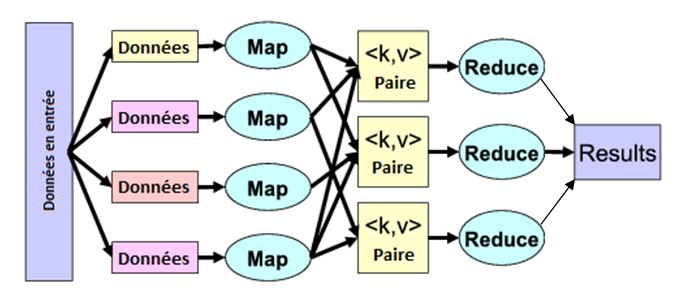
Map Reduce: strong points
Simple programming model
High-level functions instead of message passing
Scalability to very largest clusters
very good performance for simple jobs (one pass algorithms)
Run parts twice fault recovery
Map Reduce iterations
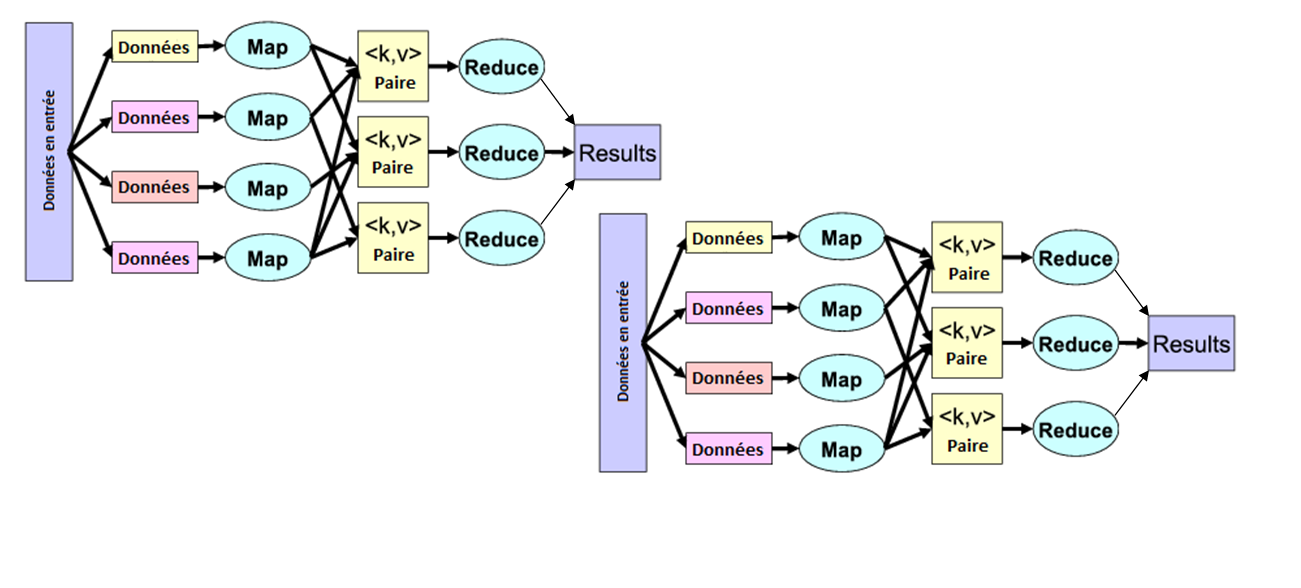
Map Reduce iterations
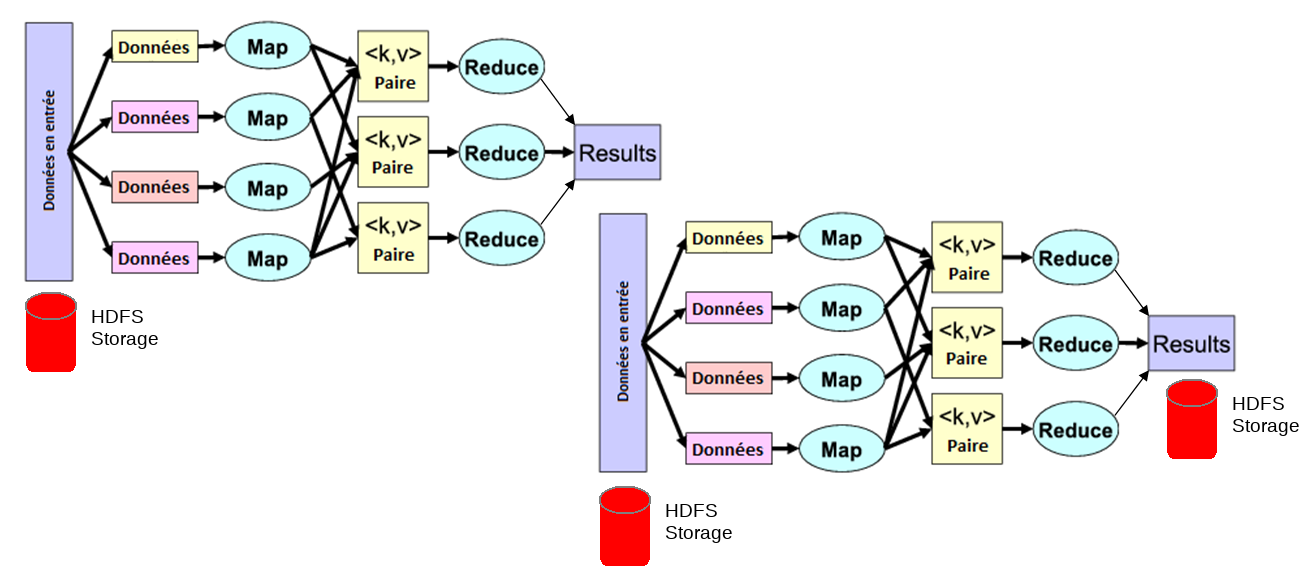
Map Reduce: weak points:
not apropriate for multi-pass /iterative algorithms
no efficient primitives for data sharing
state between steps goes to distributed file system
cumbersome to write
Apache Spark
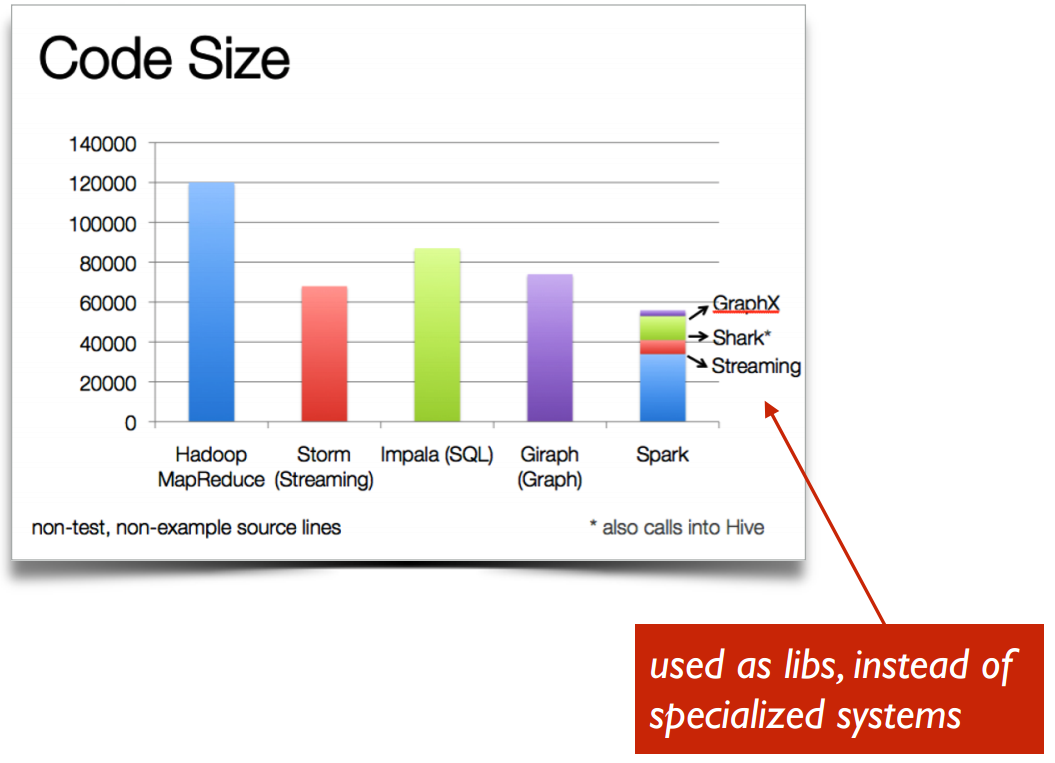
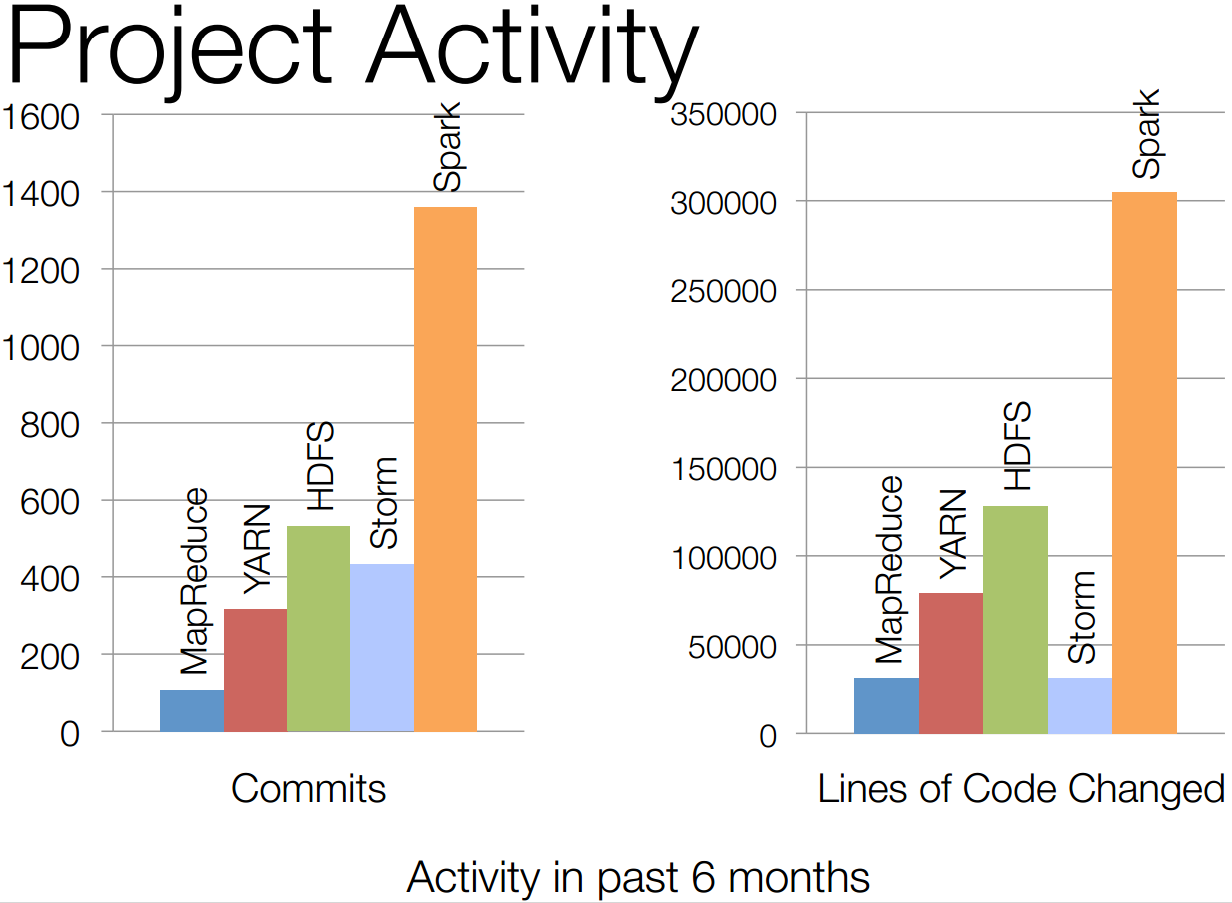
Spark code size (2015)
Spark project activity (2015)
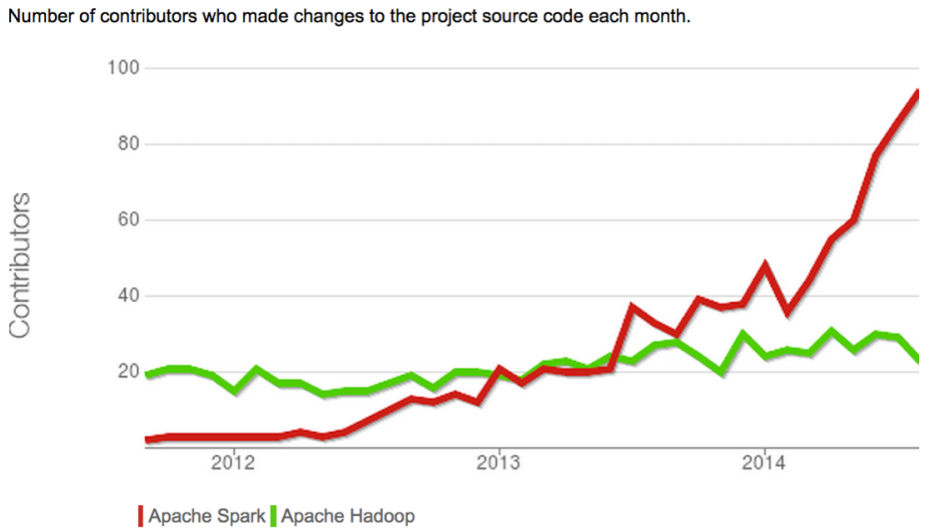
Spark contributors
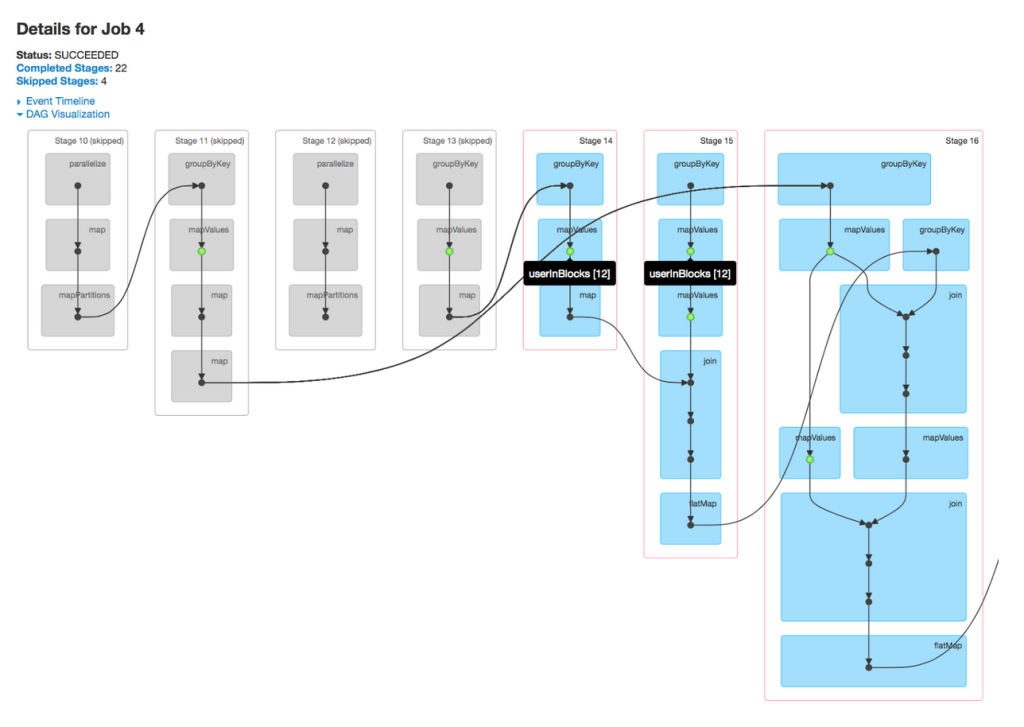
Apache Spark: general dataflow model
express general computations in a DAG form
using a simple distributed list paradigm
Spark vs MapReduce
Performance:
RDDs in memory Resilient Distributed Datasets
custom caching on nodes
lazy evaluation of the lineage graph ⇒ reduces wait states, better pipelining
generational differences in hardware ⇒ off-heap use of large memory spaces
lower overhead for starting jobs / less expensive shuffles
Expressiveness:
generalized patterns ⇒ unified engine for many use cases
functional programming ⇒ maintenance cost for large apps
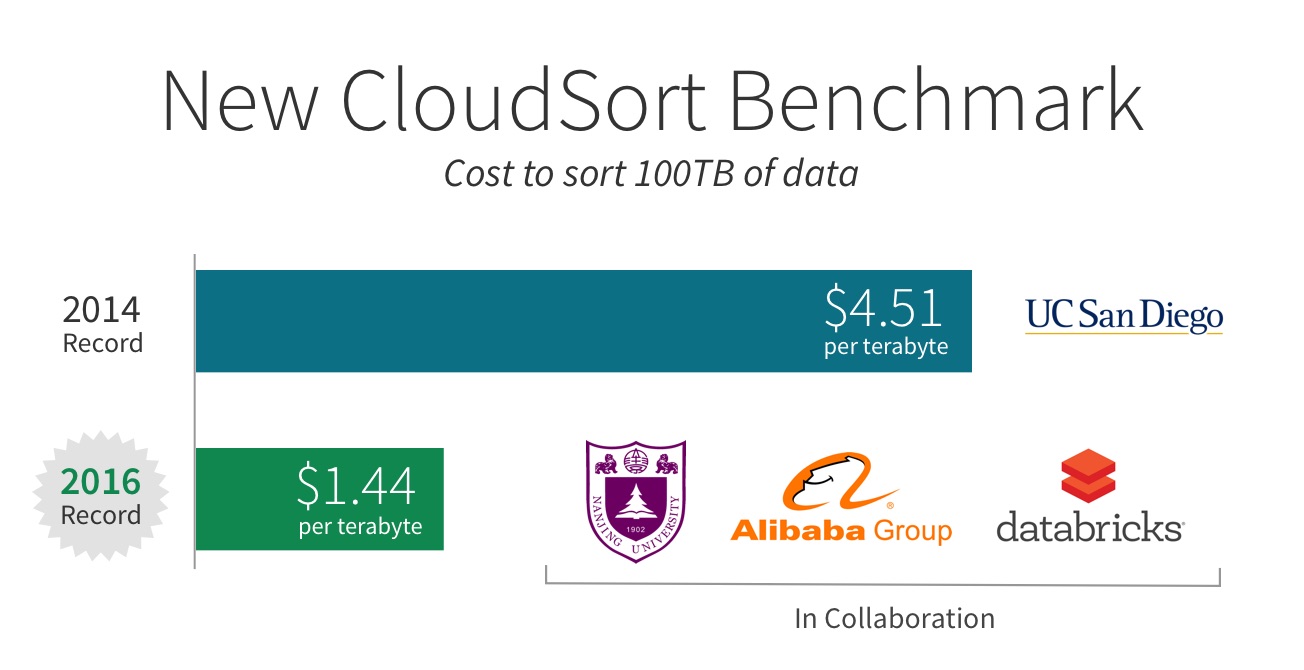
Performance: 3X faster using 10X fewer machines
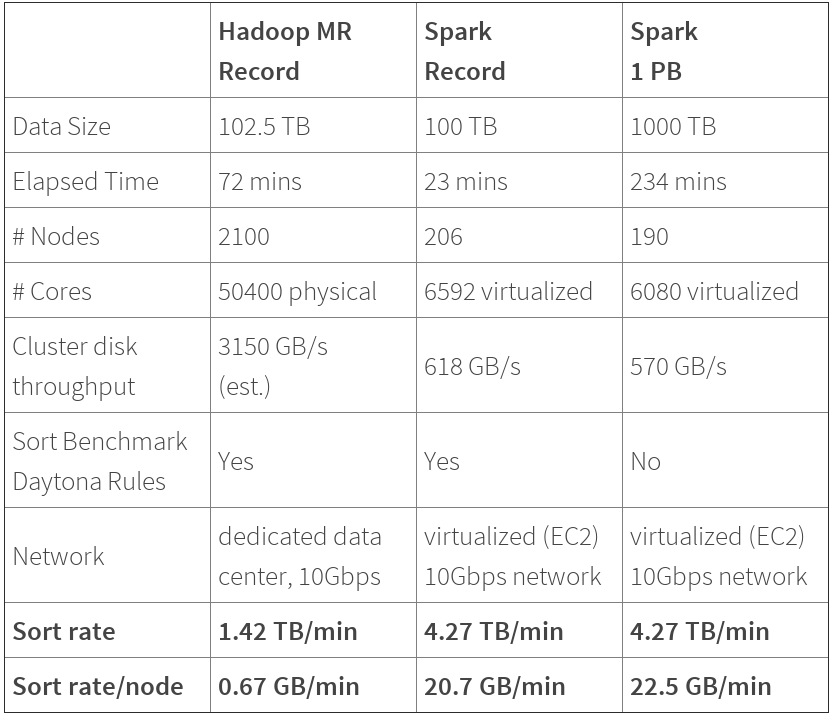
Performance vs cost
Plan
Context: Distributed programming
Spark data model
RDDs
Spark execution model
Spark cluster
Spark ecosystem
Spark Idea
Distributed programming should be no different than standard programming
val data = 1 to 1000
val filteredData= data.filter( _%2==0)Spark Idea
Distributed programming should be no different than standard programming
val data = 1 to 1000
val filteredData = sc.parallelize(data).filter(_%2==0) (1) (2)
filteredData.collect (3)| 1 | distribute data to nodes |
| 2 | distributed filtering |
| 3 | collect the result from nodes |
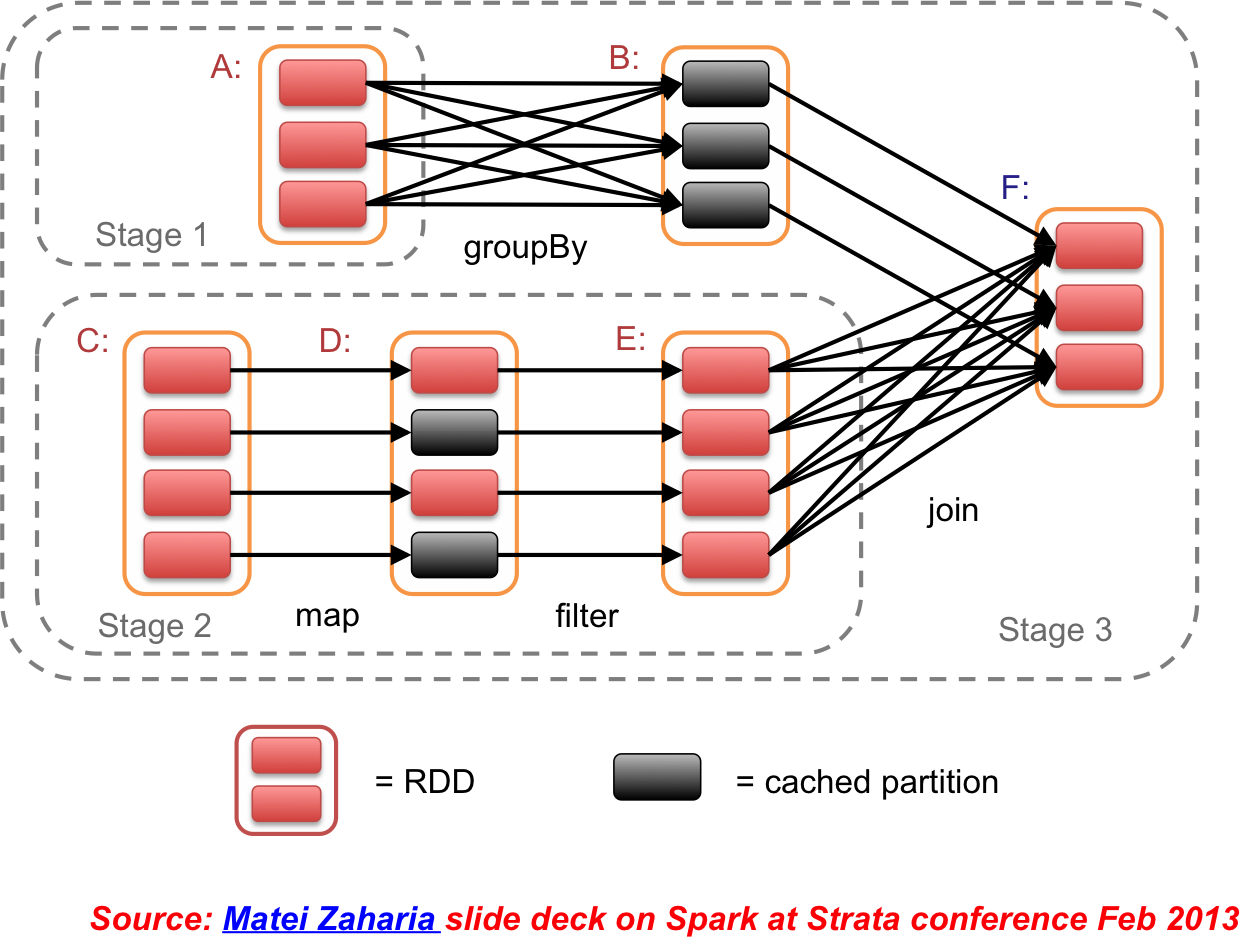
Resilient Distributed Datasets (RDDs)
Collections of objects across a cluster with user controlled partitioning & storage (memory, disk, …)
Building RDDs
Built via :
paralelization of data (sc.parallelize)
reading from parallel data sources (hdfs, s3, Cassandra)
parallel transformations of other RDDs(map, filter, …)
Automatically rebuilt on failure (lineage)
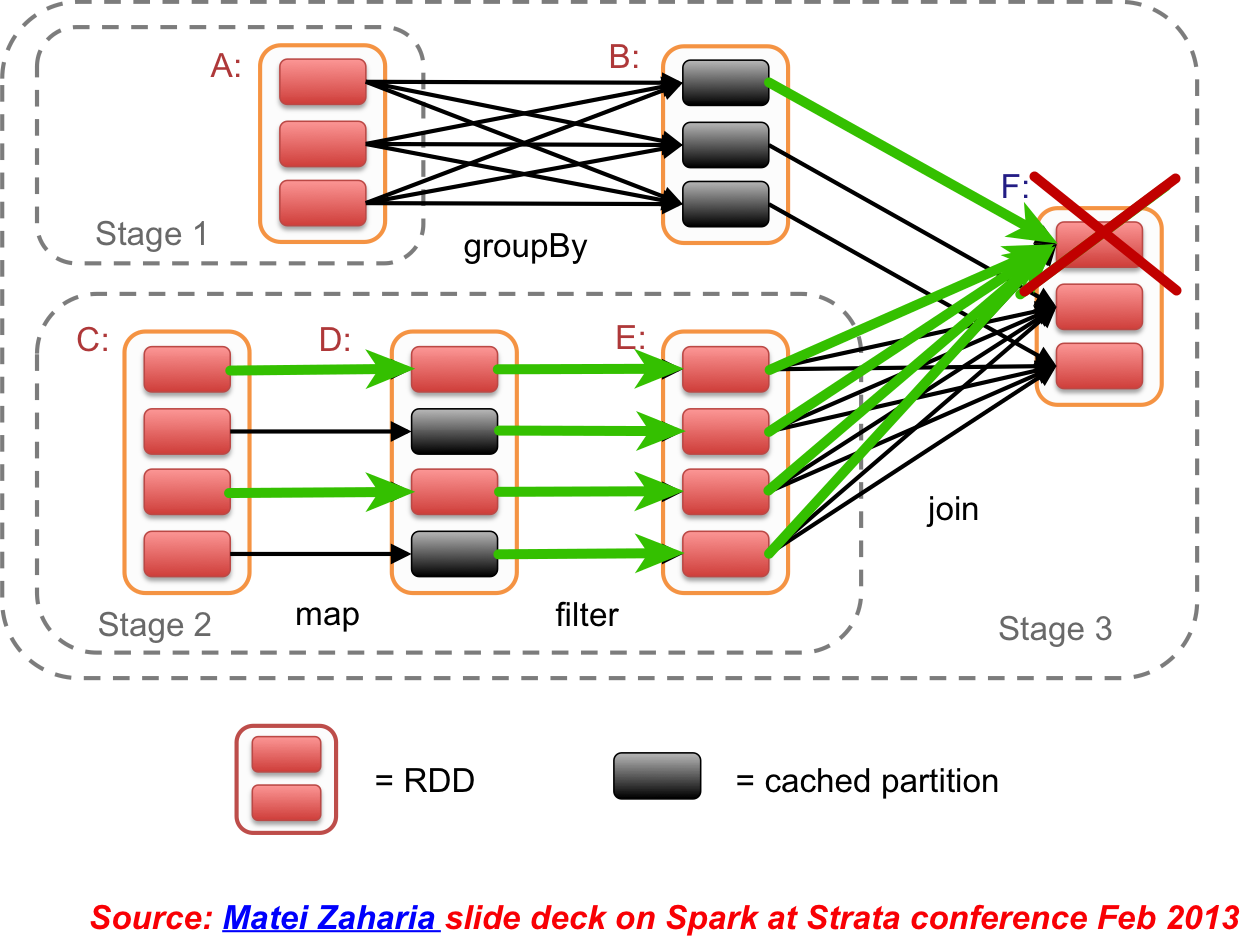
Resilient Distributed Datasets (RDDs)
Resilient Distributed Datasets (RDDs)
Plan
Distributed programming
Spark data model
Spark programming
Spark execution model
Spark ecosystem: SparkSQL et Cassandra
First program in Spark
val data = 1 to 1000 (1)
val firstRDD = sc.parallelize(data) (2)
val secondRDD = firstRDD.filter( _ < 10) (3)
secondRDD.collect (4)First program in Spark
val data = 1 to 1000 (1)| 1 | Local data generation |
First program in Spark
val firstRDD = sc.parallelize(data) (1)| 1 | Dispatch |
def parallelize[T](seq: Seq[T], numSlices: Int): rdd.RDD[T]First program in Spark
(distributed) filtering
val secondRDD = firstRDD.filter( _ < 10)First program in Spark
collect the results
secondRDD.collect (4)Spark Word Count
val input = sc.textFile("s3://...") (1)
val words = input.flatMap(x => x.split(" ")) (2)
val result = words.map(x => (x, 1))(3)
.reduceByKey((x, y) => x + y) (4)| 1 | construit un input RDD pour lire le contenu d’un fichier depuis AWS S3 |
| 2 | transformer le RDD input pour construir un RDD qui contient tous les mots du fichier |
| 3 | construit un RDD qui contient des paires (mots,1) |
| 4 | construit un RDD qui fait le comptage des occurences |
Spark Word Count - optimisation
val input = sc.textFile("s3://...") (1)
val result = lines.flatMap(x => x.split(" ")).countByValue() (2)| 1 | construit un input RDD pour lire le contenu d’un fichier depuis AWS S3 |
| 2 | utilisation de countByValue |
Spark programming in 3 steps
Create RDDs
Parallelize: sc.parallelize(Array)
Reading from file/HDFS/S3: sc.textFile(FileURL)
Transform RDDs

Transform RDDs
Actions

Actions

Plan
Context: Distributed programming
Spark data model
Spark programming
Spark execution model
Spark ecosystem
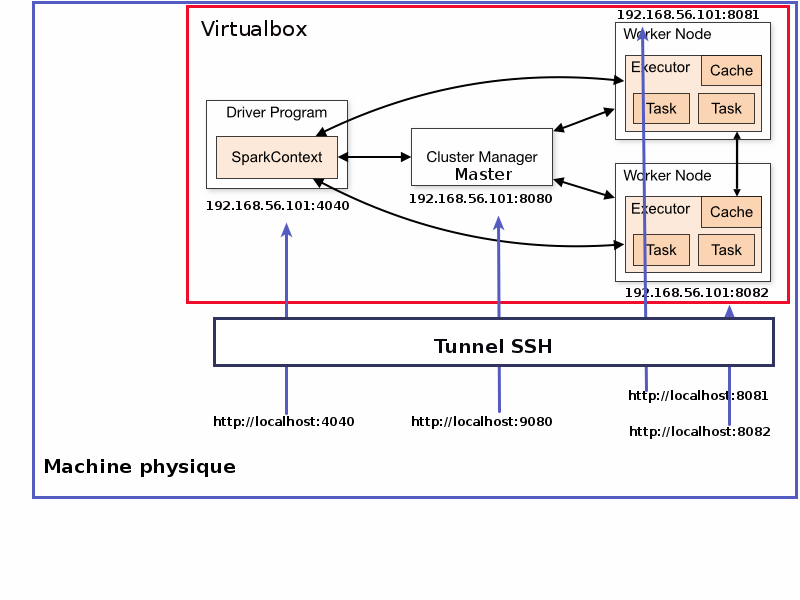
Spark Cluster Architecture
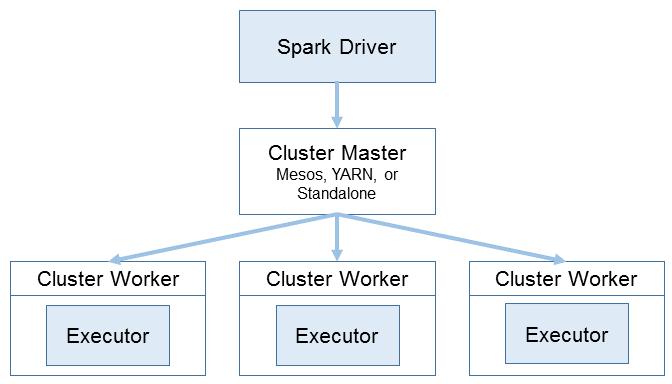
Follow execution in SparkUI (1)
val data = 1 to 1000 (1)(1) DRIVER: generate a sequence of numbers
Follow execution in SparkUI (2)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)(2) DRIVER: define a RDD by parallelizing local data
Follow execution in SparkUI (3)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)
val filteredData = parallelizedData.filter(_%2==0) (3)(3) DRIVER: define another RDD that contains the filtered data
Follow execution in SparkUI (4)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)
val filteredData = parallelizedData.filter(_%2==0) (3)
val sortedData = filteredData.sortBy( (x:Int) => - x ) (4)(4) DRIVER: define another RDD that contains sorted data
Follow execution in SparkUI (5)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)
val filteredData = parallelizedData.filter(_%2==0) (3)
val sortedData = filteredData.sortBy( (x:Int) => - x ) (4)
val groupedData = sortedData.groupBy( (x:Int)=> x%3) (5)(5) DRIVER: define another RDD that contains groupped data
Follow execution in SparkUI (5)
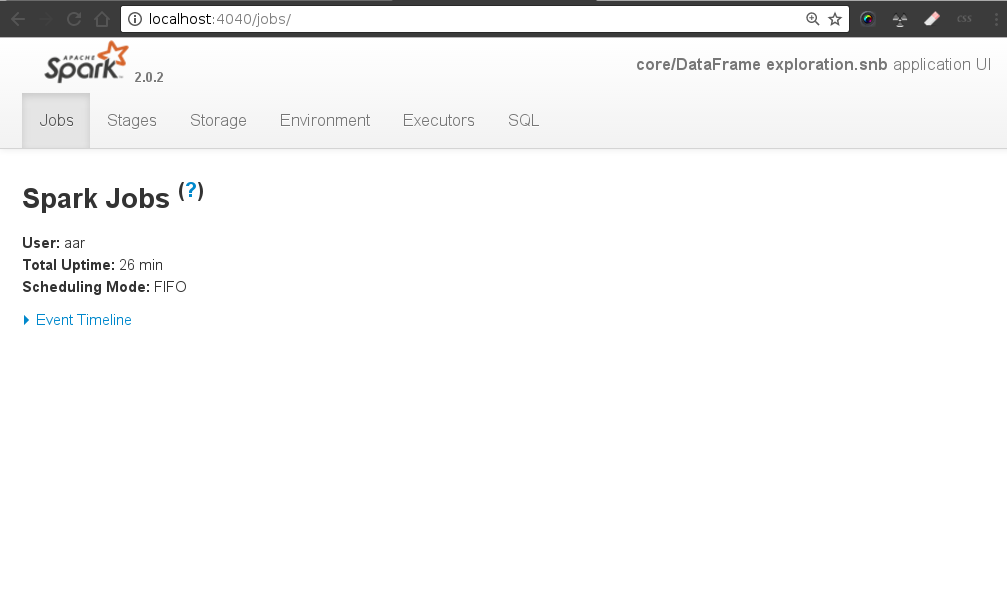
Follow execution in SparkUI (6)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)
val filteredData = parallelizedData.filter(_%2==0) (3)
val sortedData = filteredData.sortBy( (x:Int) => - x ) (4)
val groupedData = sortedData.groupBy( (x:Int)=> x%3) (5)
groupedData.collect (6)(6) DRIVER→ MASTER → WORKERs → MASTER → DRIVER
An action invoked on a RDD (sortBy) ⇒ starts the distributed computation:
DRIVER: sends a JOB to the MASTER (DAG + data)
MASTER: partition the data, calculate the pysical plan (Stages/) and sends tasks to the WORKERS
WORKERs: execute tasks and return to the MASTER
MASTER sends the response back to the DRIVER
Follow execution in SparkUI (6)
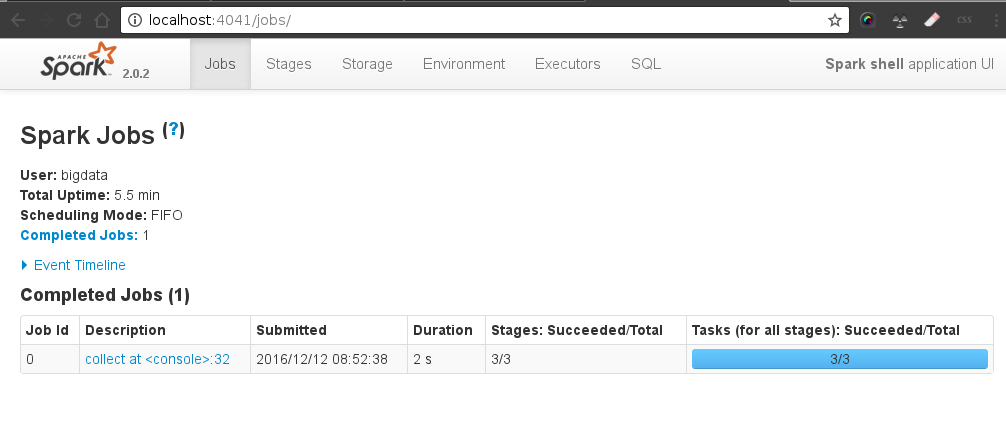
Follow execution in SparkUI (6)
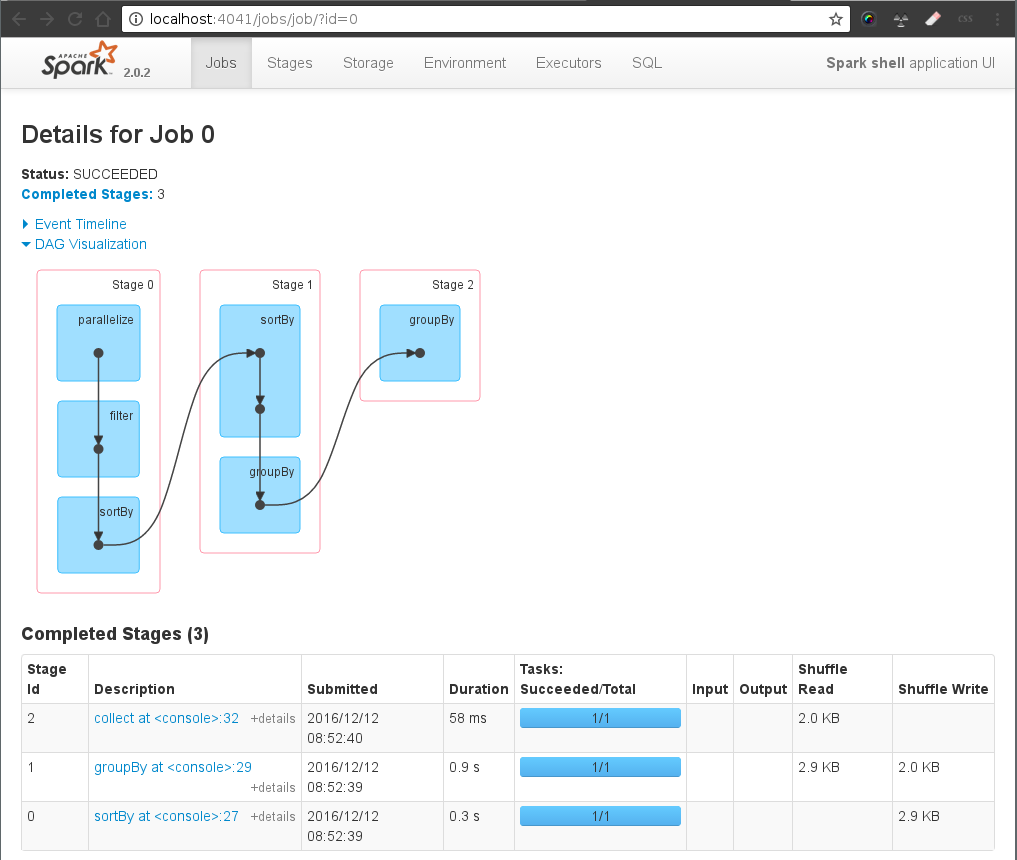
Follow execution in SparkUI (6)
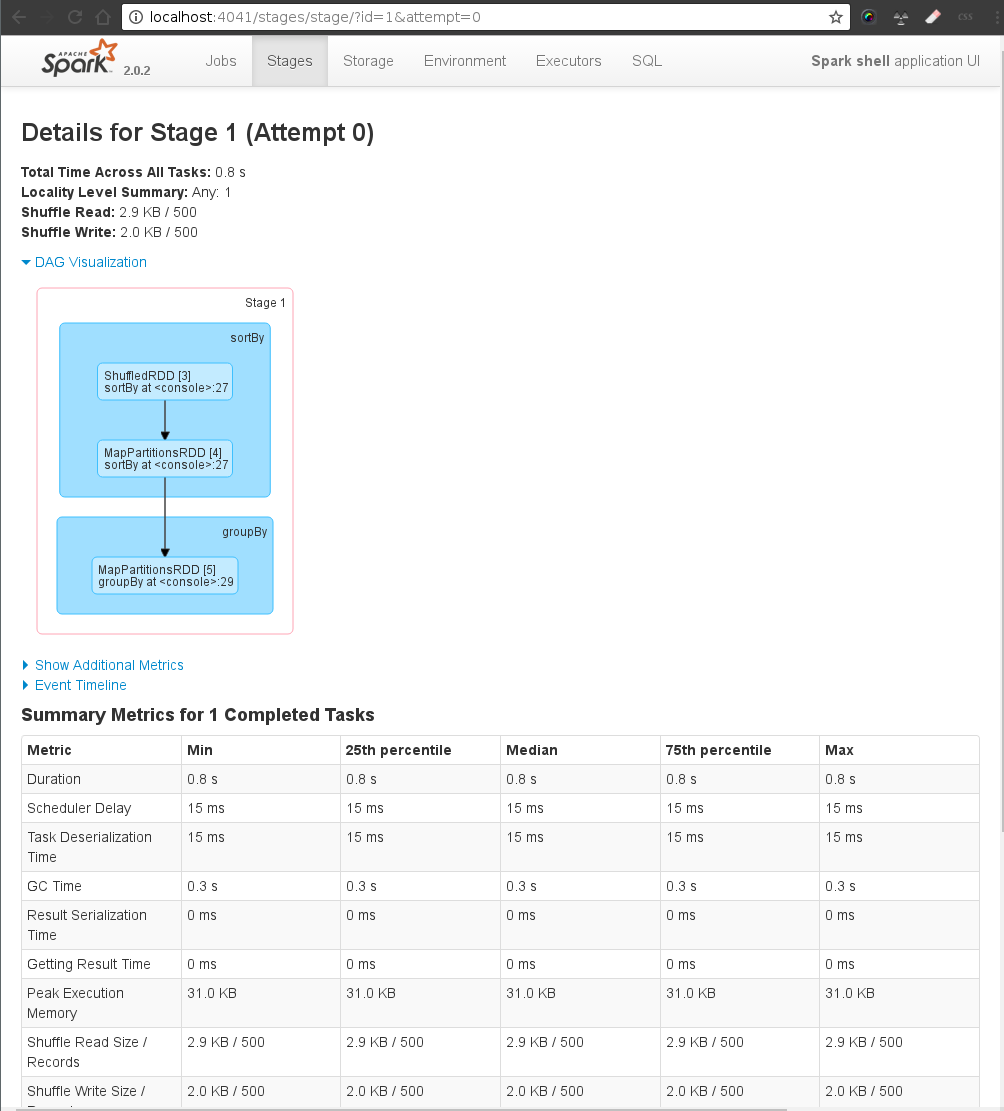
Plan
Context: Distributed programming
Spark data model
Spark programming
Spark execution model
Spark ecosystem
SparkSQL
storing general objects in relational like tables
provide a SQL like interface for querying
SparkSQL example
val sqlContext = new org.apache.spark.sql.SQLContext(sc) (1)
case class Person(name: String, age: Int) (2)
val people = sc.textFile("persons.txt")
.map(_.split(","))
.map(p => Person(p(0), p(1).trim.toInt)
.toDF (3)
people.createOrReplaceTempView("people") (4)
val teenagers = sql("""
SELECT * from people
WHERE age < 15
""") (5)
teenagers.show (6)http://spark.apache.org/docs/latest/sql-programming-guide.html
Cassandra and Spark
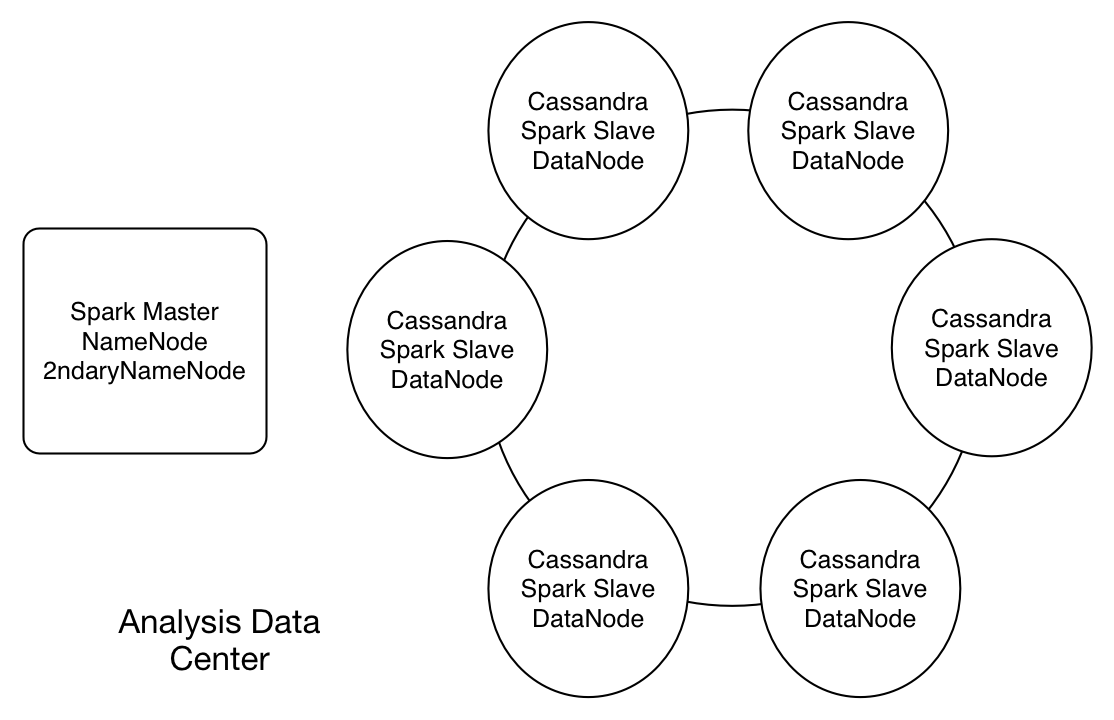
Cassandra and Spark example
CassandraConnector(conf).withSessionDo { session =>
session.execute(s"""
CREATE KEYSPACE IF NOT EXISTS demo
WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1 }""")
session.execute(s"CREATE TABLE IF NOT EXISTS demo.wordcount (word TEXT PRIMARY KEY, count COUNTER)")
}
sc.textFile(words)
.flatMap(_.split("\\s+"))
.map(word => (word.toLowerCase, 1))
.reduceByKey(_ + _)
.saveToCassandra("demo", "wordcount")
// print out the data saved from Spark to Cassandra
sc.cassandraTable("demo", "wordcount")
.collect.foreach(println)TP Spark: RDDs on sparkShell
Spark Dataframes & Datasets
Plan
RDD execution review
Best practices
Dataframes & Dataset API
Spark notebooks
TP2 Data exploration with the Dataframe API
Spark Cluster Architecture
Follow execution in SparkUI (1)
val data = 1 to 1000 (1)(1) DRIVER: generate a sequence of numbers
Follow execution in SparkUI (2)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)(2) DRIVER: define a RDD by parallelizing local data
Follow execution in SparkUI (3)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)
val filteredData = parallelizedData.filter(_%2==0) (3)(3) DRIVER: define another RDD that contains the filtered data
Follow execution in SparkUI (4)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)
val filteredData = parallelizedData.filter(_%2==0) (3)
val sortedData = filteredData.sortBy( (x:Int) => - x ) (4)(4) DRIVER: define another RDD that contains sorted data
Follow execution in SparkUI (5)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)
val filteredData = parallelizedData.filter(_%2==0) (3)
val sortedData = filteredData.sortBy( (x:Int) => - x ) (4)
val groupedData = sortedData.groupBy( (x:Int)=> x%3) (5)(5) DRIVER: define another RDD that contains groupped data
Follow execution in SparkUI (5)
Follow execution in SparkUI (6)
val data = 1 to 1000 (1)
val parallelizedData = sc.parallelize(data) (2)
val filteredData = parallelizedData.filter(_%2==0) (3)
val sortedData = filteredData.sortBy( (x:Int) => - x ) (4)
val groupedData = sortedData.groupBy( (x:Int)=> x%3) (5)
groupedData.collect (6)(6) DRIVER→ MASTER → WORKERs → MASTER → DRIVER
An action invoked on a RDD (sortBy) ⇒ starts the distributed computation:
DRIVER: sends a JOB to the MASTER (DAG + data)
MASTER: partition the data, calculate the pysical plan (Stages/) and sends tasks to the WORKERS
WORKERs: execute tasks and return to the MASTER
MASTER sends the response back to the DRIVER
Follow execution in SparkUI (6)
Follow execution in SparkUI (6)
Follow execution in SparkUI (6)
RDD review
construct a RDD ( parallelize/ read from distributed datasources)
transformations ⇒ DAG (lazy)
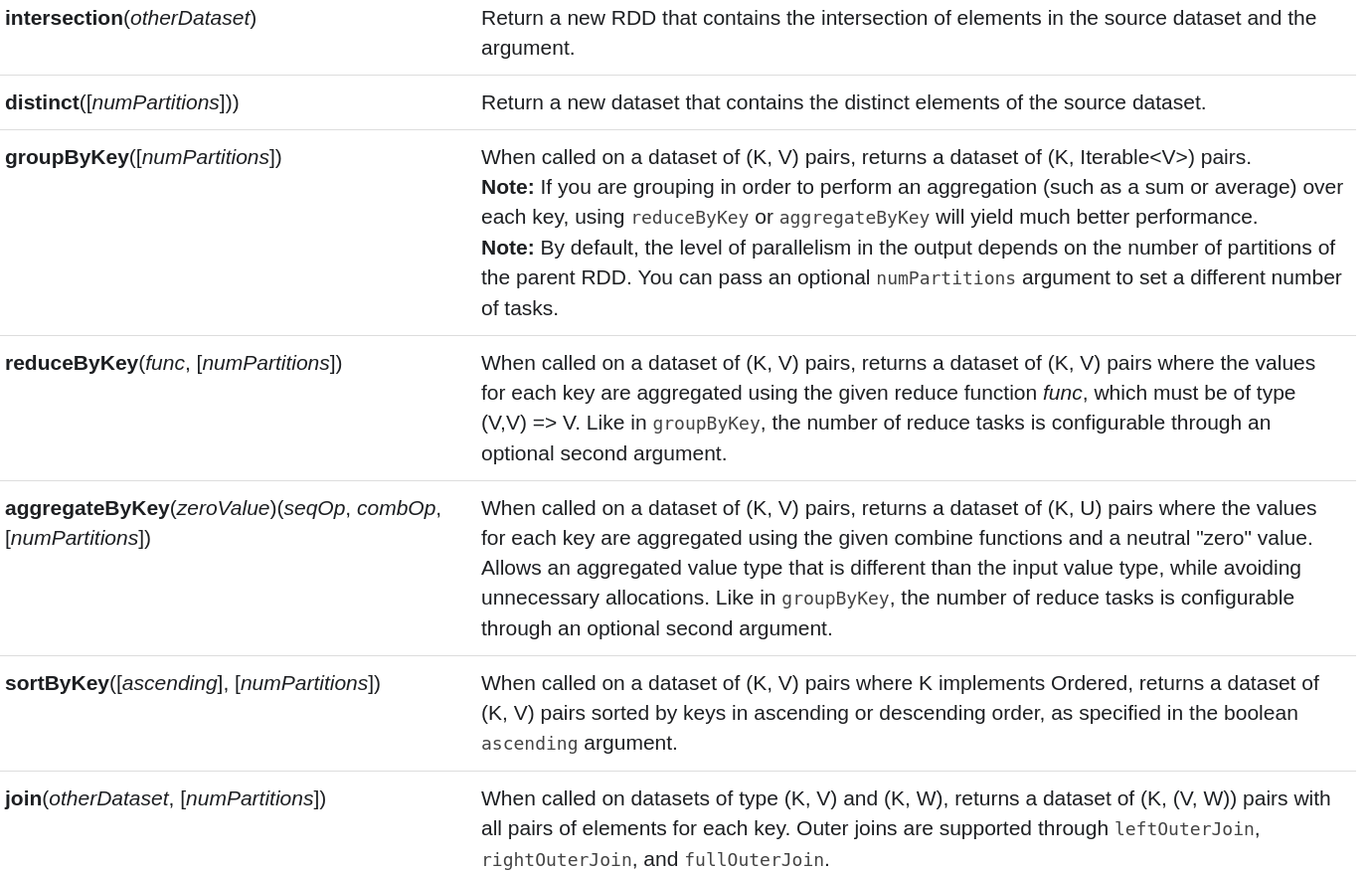
map, filter, flatMap, mapPartitions, mapPartitionsWithIndex, sample, union, intersection, distinct, groupByKey, reduceByKey, sortByKey, join, cogroup, repatition, cartesian, glom, …
actions ⇒ execute DAG + retrieve result on the DRIVER
reduce, collect, count, first, take, foreach, saveAs…, min, max, …
Cassandra and Spark
Spark Cluster Architecture
Cassandra and Spark example
CassandraConnector(conf).withSessionDo { session =>
session.execute(s"""
CREATE KEYSPACE IF NOT EXISTS demo
WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1 }""")
session.execute(s"CREATE TABLE IF NOT EXISTS demo.wordcount (word TEXT PRIMARY KEY, count COUNTER)")
}
sc.textFile(words)
.flatMap(_.split("\\s+"))
.map(word => (word.toLowerCase, 1))
.reduceByKey(_ + _)
.saveToCassandra("demo", "wordcount")
// print out the data saved from Spark to Cassandra
sc.cassandraTable("demo", "wordcount")
.collect.foreach(println)Plan
RDD execution review
Best practices
Dataframes & Dataset API
Spark notebooks
TP2 Data exploration with the Dataframe API
Use ReduceByKey over GroupByKey
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD
.reduceByKey(_ + _)
.collect()
val wordCountsWithGroup = wordPairsRDD
.groupByKey()
.map(t => (t._1, t._2.sum))
.collect()groupByKey - all the key-value pairs are shuffled around
reduceByKey - combine output with a common key on each partition before shuffling the data.
Counting
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter)Spark Cluster Architecture
Spark execution modes
Local: run locally with as many worker threads as logical cores
./bin/spark-shell --master local[*]
Standalone
./bin/spark-shell --master spark://HOST1:PORT1 ./bin/spark-shell --master spark://HOST1:PORT1,HOST2:PORT2
Cluster mode (Mesos, Yarn, Kubernetes)
./bin/spark-shell --master mesos://HOST:PORT ./bin/spark-shell --master yarn ./bin/spark-shell --master k8s://HOST:PORT
Closure
Closure = variables and methods which must be visible for the executor (context)
Spark computes the task’s closure before execution
The closure is serialized and sent to each executor
the counter in the memory of the driver node but this is no longer visible to the executors
the executors only see the copy from the serialized closure
Result ⇒ counter=0 (or something else if local[*])
Data serialization
convenience (work with any Java type) VS performance
Java serialization [default]: works with any class you create that implements java.io.Serializable
flexible but often quite slow, and leads to large serialized formats for many classes
Kryo serialization: significantly faster and more compact (10x)
does not support all Serializable types, requires you to register the classes you’ll use in the program in advance for best performance
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)Task not serializable Exception (1)
var myClass = new NonSerializableClass()
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach( ... myClass ...)Task not serializable Exception (2)
var myClass = new NonSerializableClass()
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach( ... myClass ...)use only serializable classes in closures
Task not serializable Exception (3)
object AwsClient{
val s3 = new AmazonS3Client(new BasicAWSCredentials(AWS_ID, AWS_KEY))
}
sampleDF.foreach( r=> {
...
AwsClient.s3.putObject(... ,... ,... )
})or you can just wrap it in an object to make it available at the worker side
Shared variables: Accumulators and Brodcast variables
closures - should not be used to mutate some global state
accumulators ⇒ mechanism for safely updating a variable
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
scala> accum.value
res2: Long = 10broadcast variables ⇒ give every node a copy of a large input dataset (efficient manner)
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)Brodcast variables:
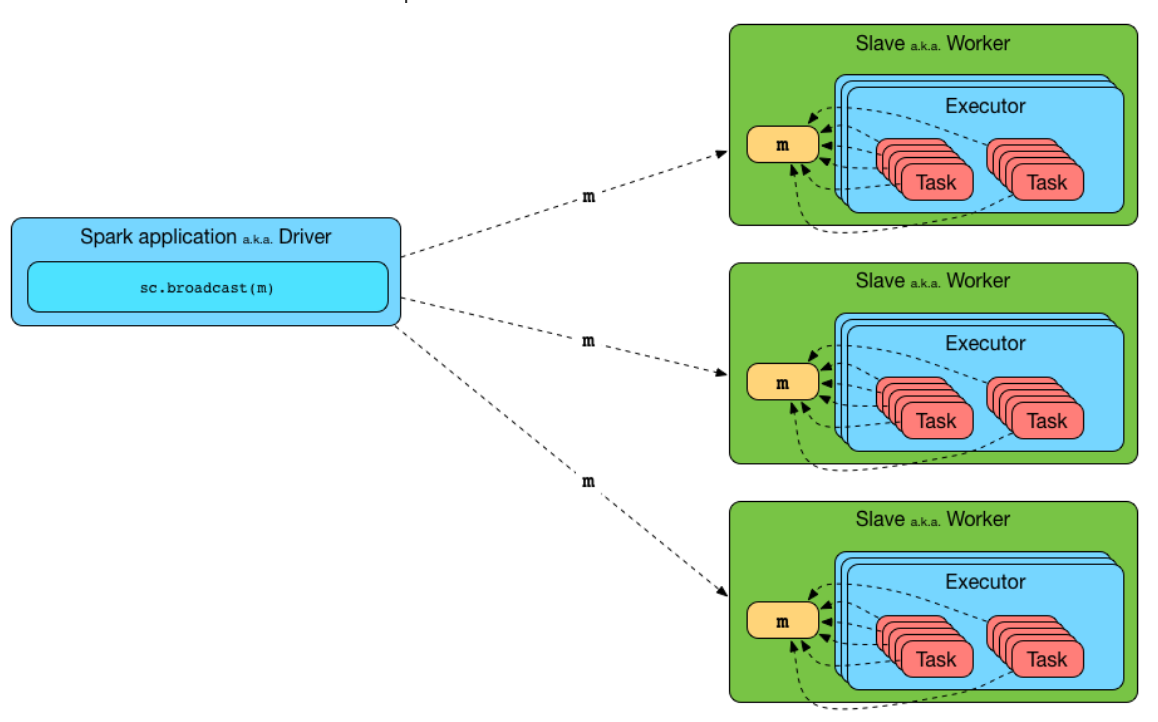
Test on cluster mode !
most of the problems do not appear in local mode (serialization, classloading, network issue)
something that works well in a small dataset hangs forever in production
⇒ test early in cluster mode
Tuning Apache Spark
collect
caching
parallelism level / partitioning
shuffles
Avoid collect
collect ⇒ often OutOfMemoryError trying to load results back to driver
not only collect(): averageByKey(), collectByKey(), …
alternatives: count() before collect or sample
Caching levels
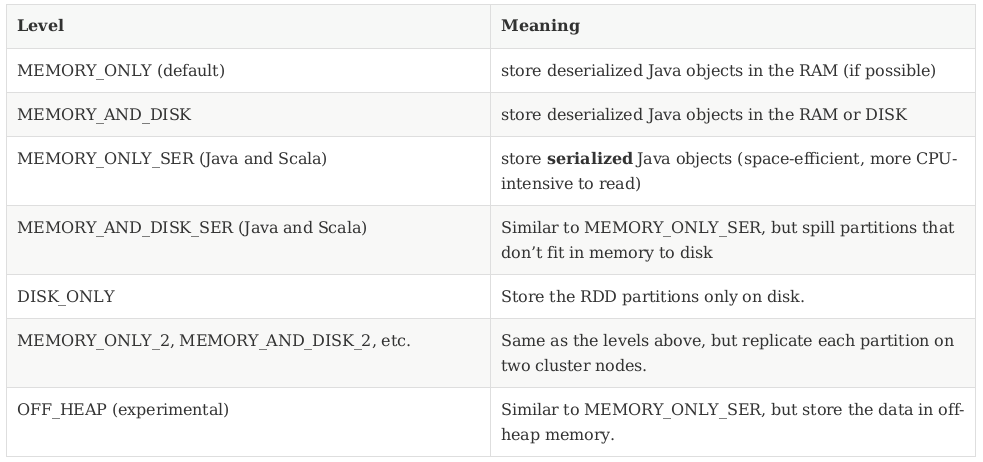
Decide caching level
If your RDDs fit in RAM ⇒ MEMORY_ONLY
If not ⇒ try MEMORY_ONLY_SER + a fast serialization library
DISK? ⇒ unless the DAG is expensive to compute or filters a large amount of the data !
Replicated storage levels? ⇒ fast fault recovery (e.g. using Spark to serve requests from a web application).
all the storage levels provide full fault tolerance by recomputing lost data !
the replicated ones let you continue running tasks on the RDD without waiting to recompute a lost partition.
Parallelism level / partitioning (1)
Goal: fully utilize ressources while minimizing waits and recompute lost partitions
Parallelism level
Spark automatically sets the number of “map” tasks to run on each file according to its size
You can control it through optional parameters ex: SparkContext.textFile("file",numpartitions)
For distributed “reduce” operations, such as groupByKey and reduceByKey, it uses the largest parent RDD’s number of partitions.
spark.default.parallelism ⇒ recommend 2-3 tasks per CPU core in your cluster
repartion(num_partitions) and coalesce(num_partitions) ⇒ change number of partitions
Tuning parallelism level
a tasks should take at least 200 ms to execute (monitoring the task execution latency from the Spark UI!)
considerable longer tasks ⇒ increase the level of parallelism (until performance stops improving)
OutOfMemoryError? often one of the reduce tasks in groupByKey is too large (shuffles (sortByKey, groupByKey, reduceByKey, join, etc) build a hash table within each task to perform the grouping, which can often be large)⇒ increase the level of parallelism ⇒ smaller tasks
Shuffle
Number of shuffles
Shuffle ⇒ high CPU, network, IO cost
In general⇒ avoiding shuffle will make your program run faster
Exception: data arrives in a few large unsplittable files
large numbers of records in each partition
not enough partitions to take advantage of all the available cores
repartition with a high number of partitions (⇒shuffle) ⇒ leverage more of the cluster’s CPU.
Plan
RDD execution review
Best practices
Dataframes & Dataset API
Spark notebooks
TP2 Data exploration with the Dataframe API
RDD API
Most data is structured (JSON, CSV, Avro, Parquet, Hive …)
Programming RDDs inevitably ends up with a lot of tuples (_1, _2, …)
Functional transformations (e.g. map/reduce) are not as intuitive
val myRDD = sc.parallelize(persons)
myRDD.map(x=>(x.dept,(x.age,1)))
.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
.map(p=>(p._1,p._2._1/p._2._2))
.collectRDD vs SQL
val myRDD = sc.parallelize(persons)
myRDD.map(x=>(x.dept,(x.age,1)))
.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
.map(p=>(p._1,p._2._1/p._2._2))
.collect --- SQL LIKE
SELECT avg(age) FROM pdata
GROUP BY dept;RDD vs DataFrames
val myRDD = sc.parallelize(persons)
myRDD.map(x=>(x.dept,(x.age,1)))
.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
.map(p=>(p._1,p._2._1/p._2._2))
.collectdata.groupBy("dept").avg("age")Introducing DataFrames and SparkSQL
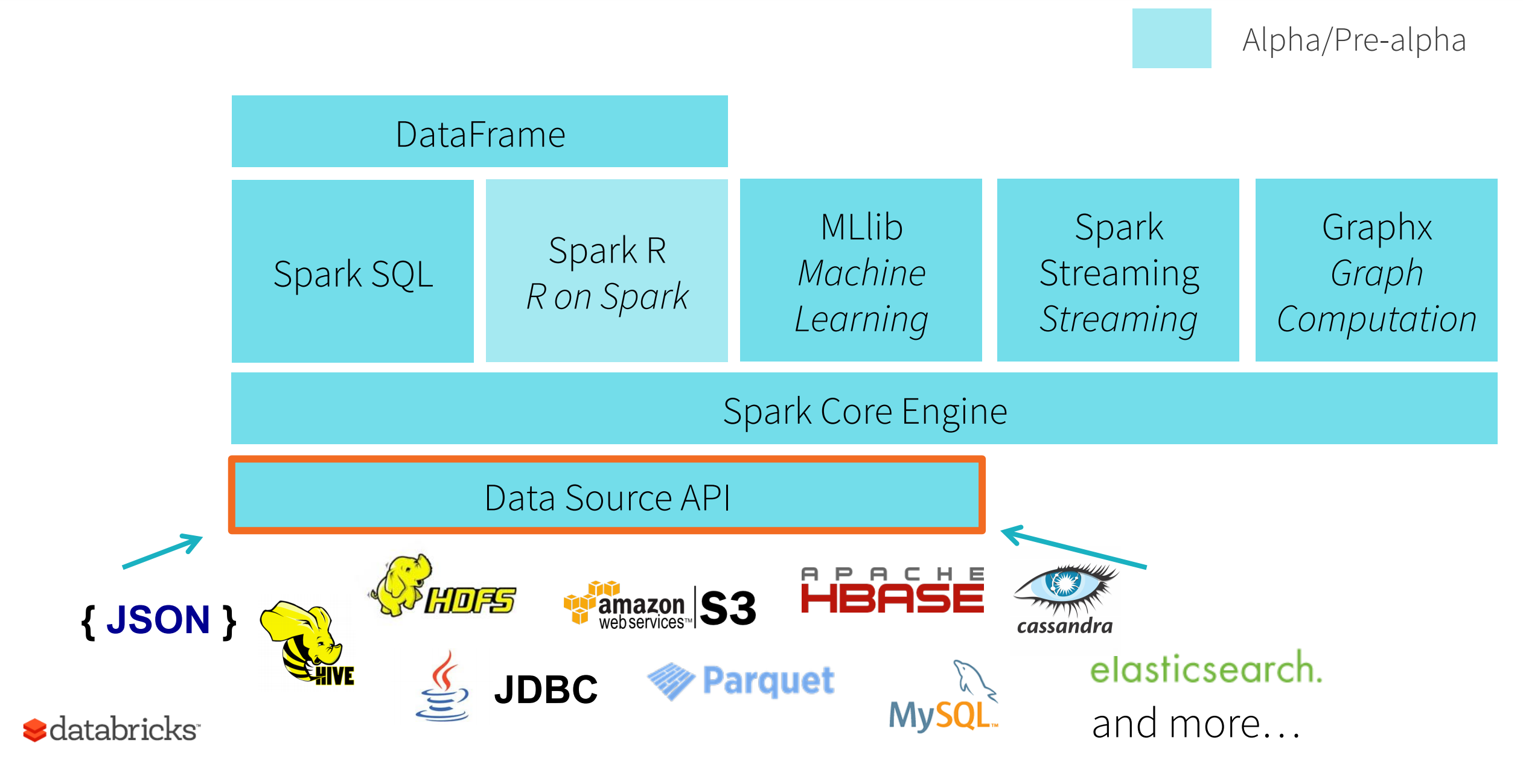
Spark Dataframes
RDD with schema
Distributed collection of data grouped into named columns
Domain-specific functions designed for common tasks
Metadata
Relational data processing: project, filter, aggregation, join
Spark Dataframes Examples
// Create from RDD
val dfFromRDD = myRDD.df
// Create from JSON
val df = sparkSession.read.json("examples/src/main/resources/people.json")
// Show the content of the DataFrame
df.show()
// age name
// 30 Andy
// 19 Justin
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)Spark Dataframes : Column selection
// Select only the "name" column
df.select("name").show() // implicit conversion from string to Column
// name
// Michael
// Andy
// Justin
//Equivalent column selection
df.select(df("name")).show() // apply function on dataframe
df.select(col("name")).show() //using the col function
df.select(df.col("name")).show() //using the col method
df.select($"name").show // easy scala shorcutSpark Dataframes: simple column computations
// Select everybody, but increment the age by 1
df.select(df("name"), df("age") + 1).show()
// name (age + 1)
// Michael null
// Andy 31
// Justin 20Spark Dataframes Filtering
// Select people older than 21
df.filter(df("age") > 21).show()
// age name
// 30 Andy
// Count people by age
df.groupBy("age").count().show()
// age count
// null 1
// 19 1
// 30 1Complex example
val accidents = usagers
.filter($"grav" == 2 ) // on filtre les victimes
.groupBy("Num_Acc") // on groupe sur l'id de l'accident
.count() // on compte le nombre des victimes
.sort(desc("count"))// on trie par le nombre des victimes
.limit(3)// on garde uniquement les 3 accidents les plus meurtirers
.withColumnRenamed("count","nb_victimes")
.join(caracteristiques, usagers("Num_acc")== caracteristiques("Num_Acc"))// on fait le jointure avec les caracteristiques
.join(lieux, usagers("Num_acc")== lieux("Num_Acc"))// on fait le jointure avec les lieux
.join(vehicules, usagers("Num_Acc")== vehicules("Num_Acc")) // on fait la jointure avec les vehicules
.groupBy(caracteristiques("an"),caracteristiques("mois"),
caracteristiques("jour"),caracteristiques("adr"),
caracteristiques("dep"), caracteristiques("atm"),
$"nb_victimes") // on groupe sur les colonnes qui nous interessent
.count().withColumnRenamed("count","nb_vehicules") // on compte le nombre des vehiculesDataframe vs Datasets
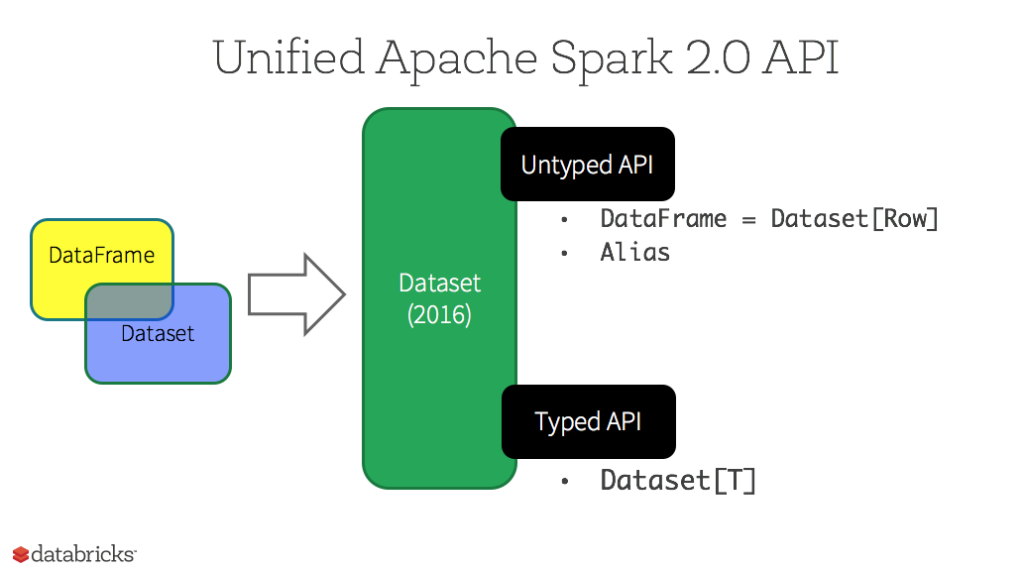
Spark Datasets
type safe generalisation of Dataframes
all the methods available to Dataframes are the same
type Dataframe = Dataset[Row]
use native types instead of Row
Spark Dataset example
case class University(name: String, numStudents: Long, yearFounded: Long)
val schools = sqlContext.read.json("/schools.json").as[University]
schools.map(s => s"${s.name} is ${2015 – s.yearFounded} years old")SparkSQL/Dataframes execution model
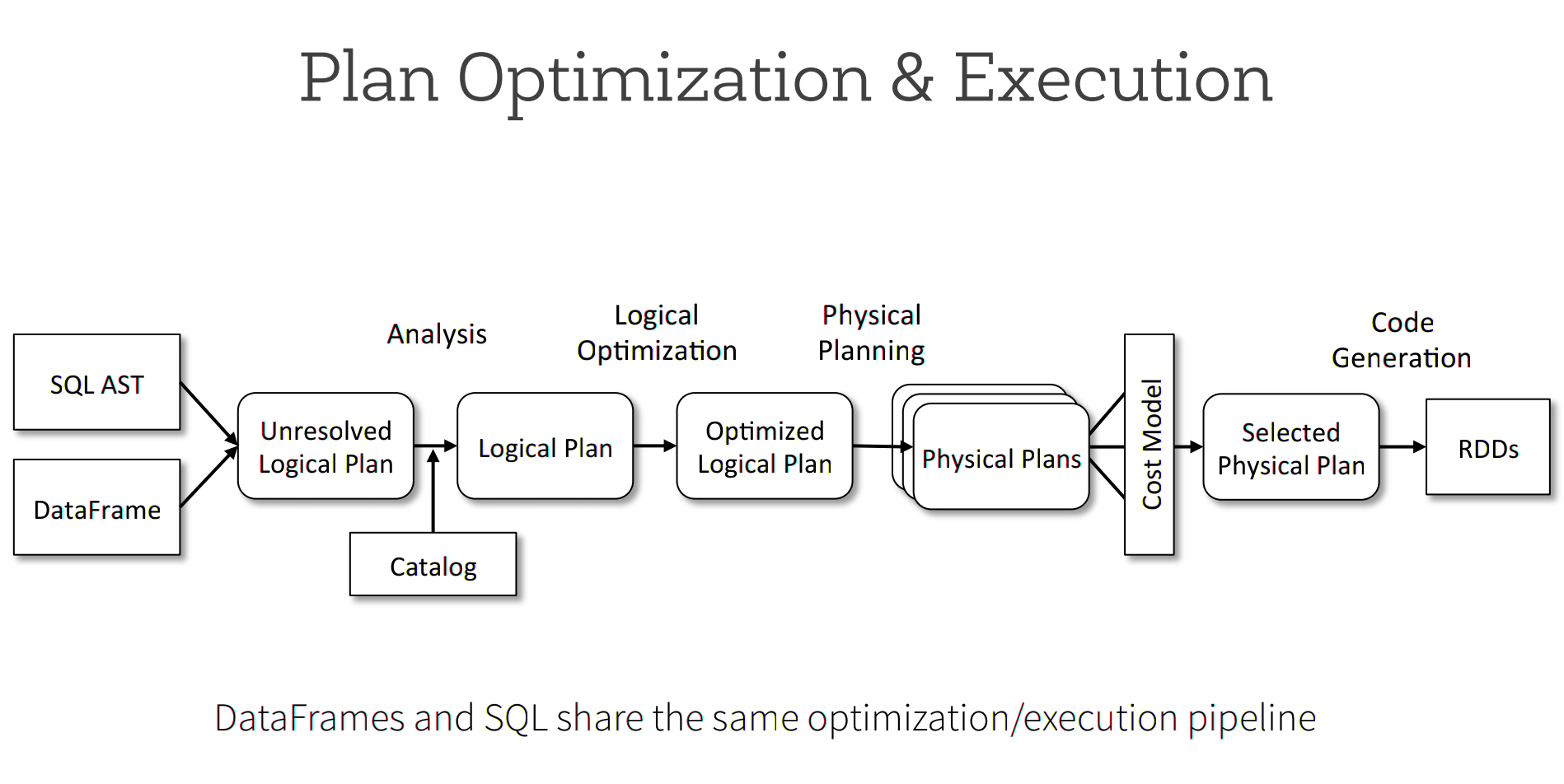
SparkSQL/Dataframe optimisations
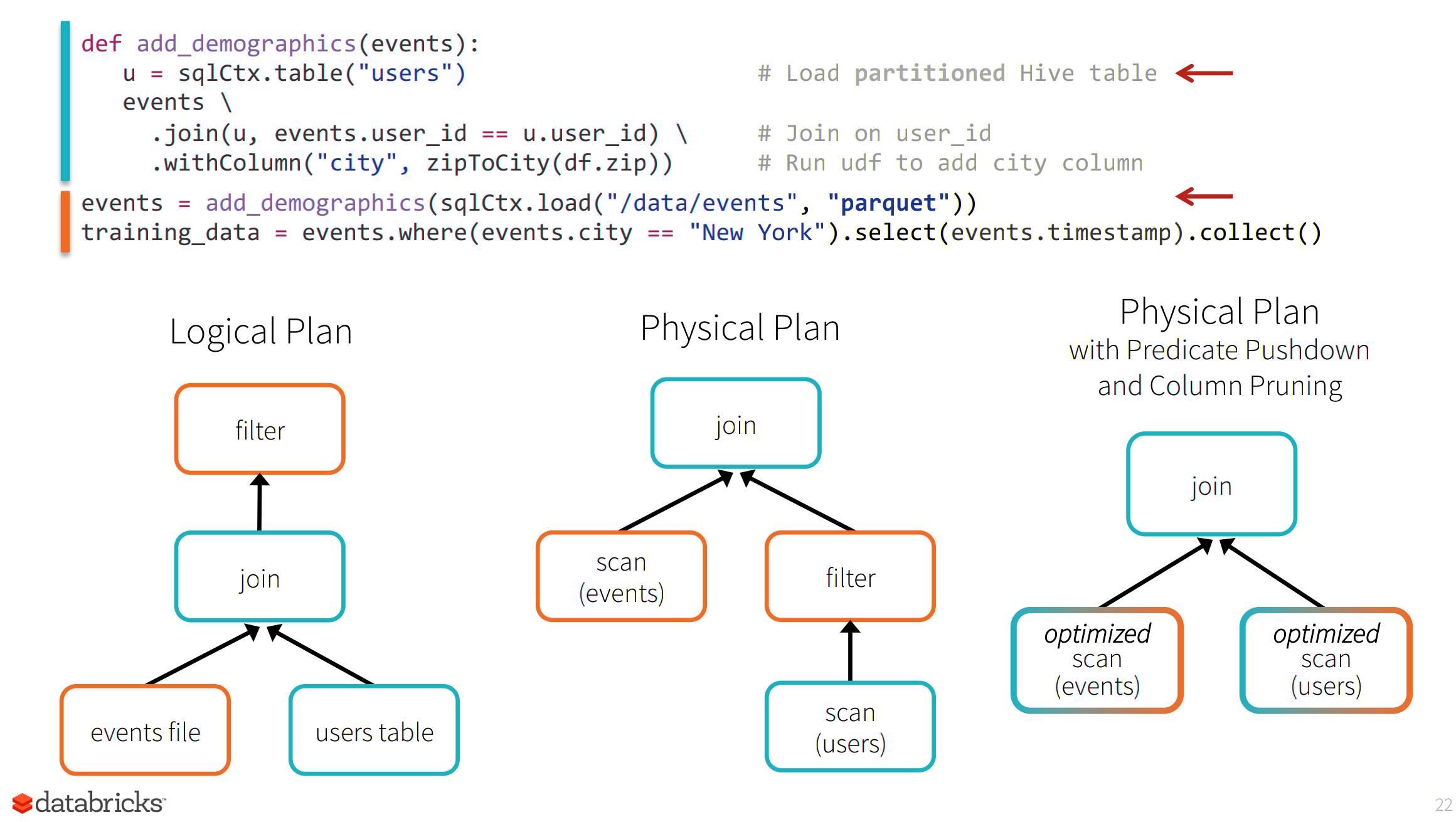
SparkSQL/Dataframe optimisations
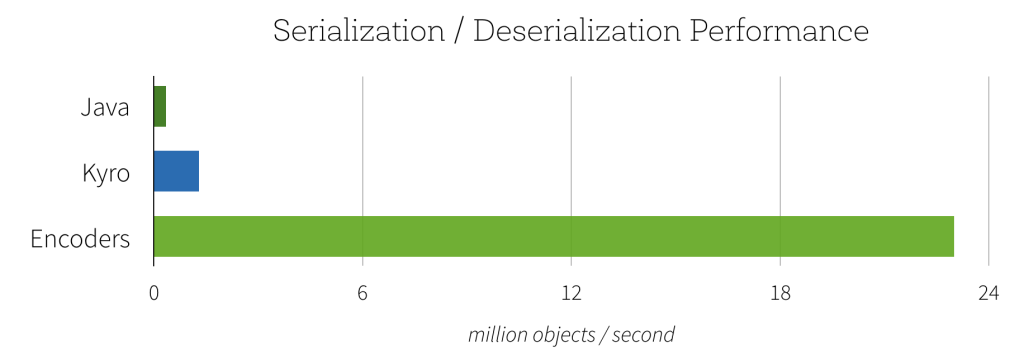
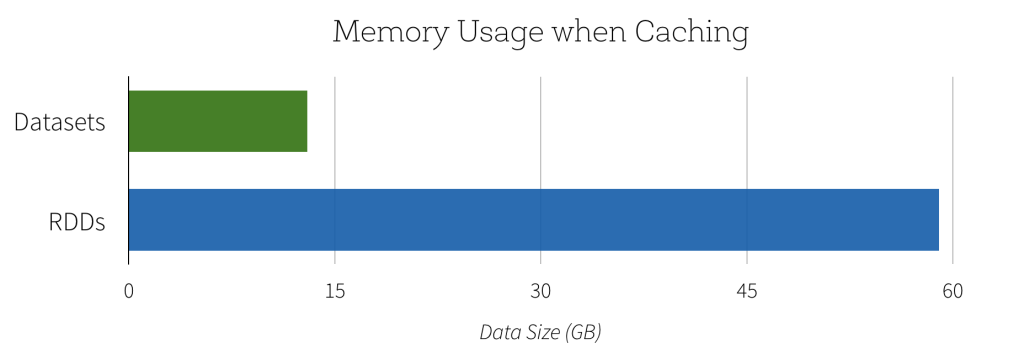
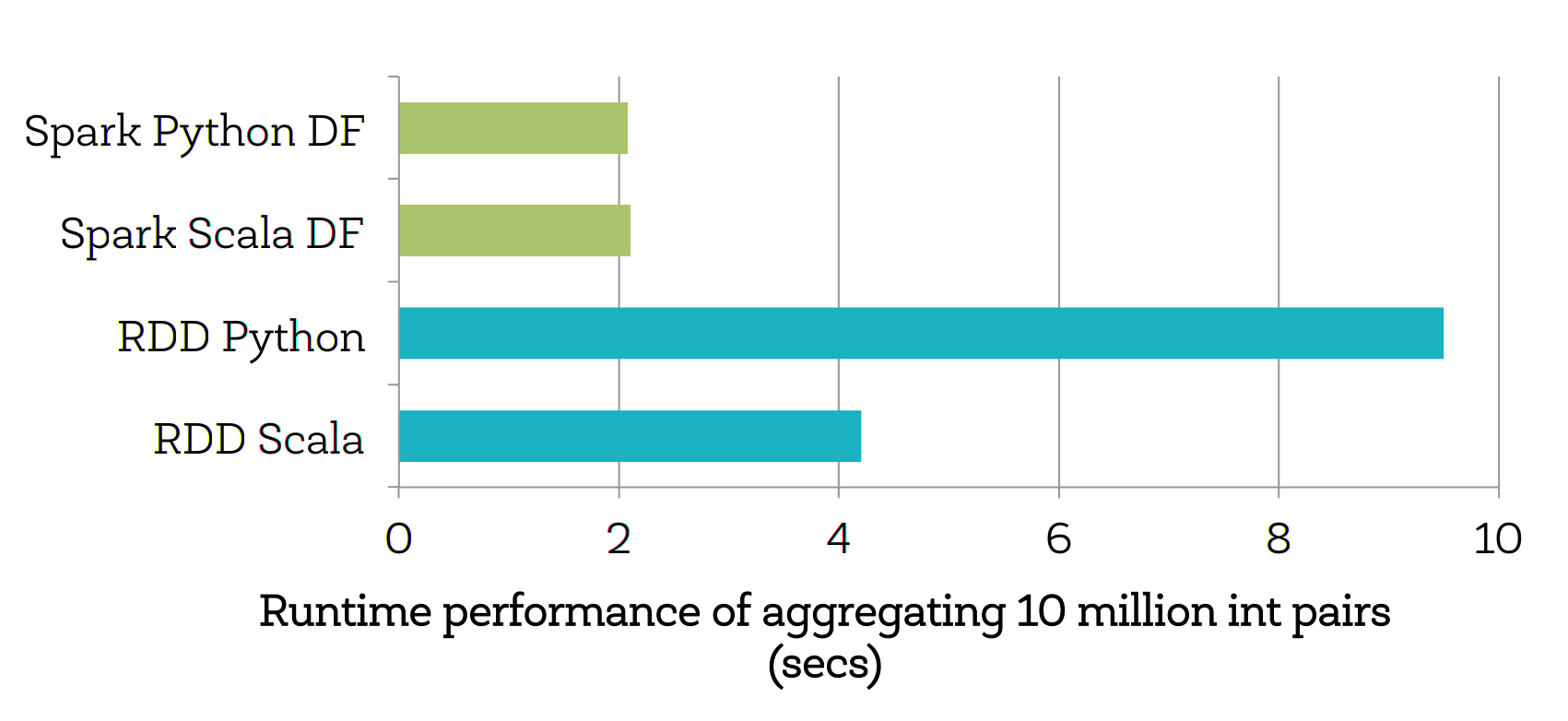
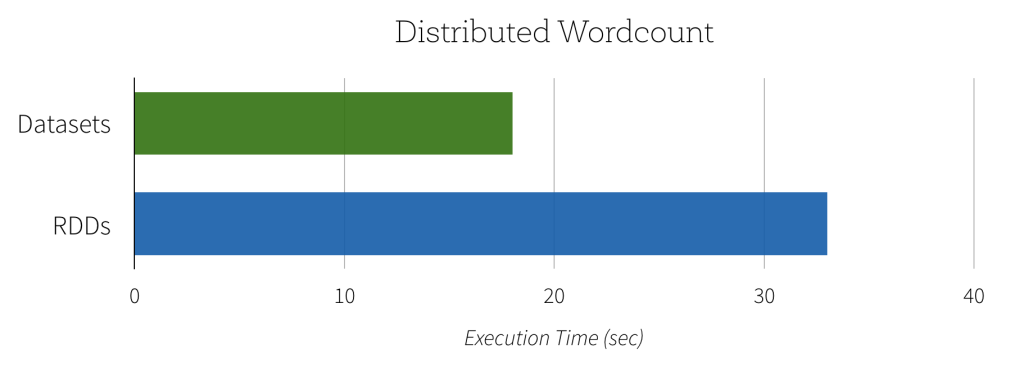
SparkSQL/Dataframe performance
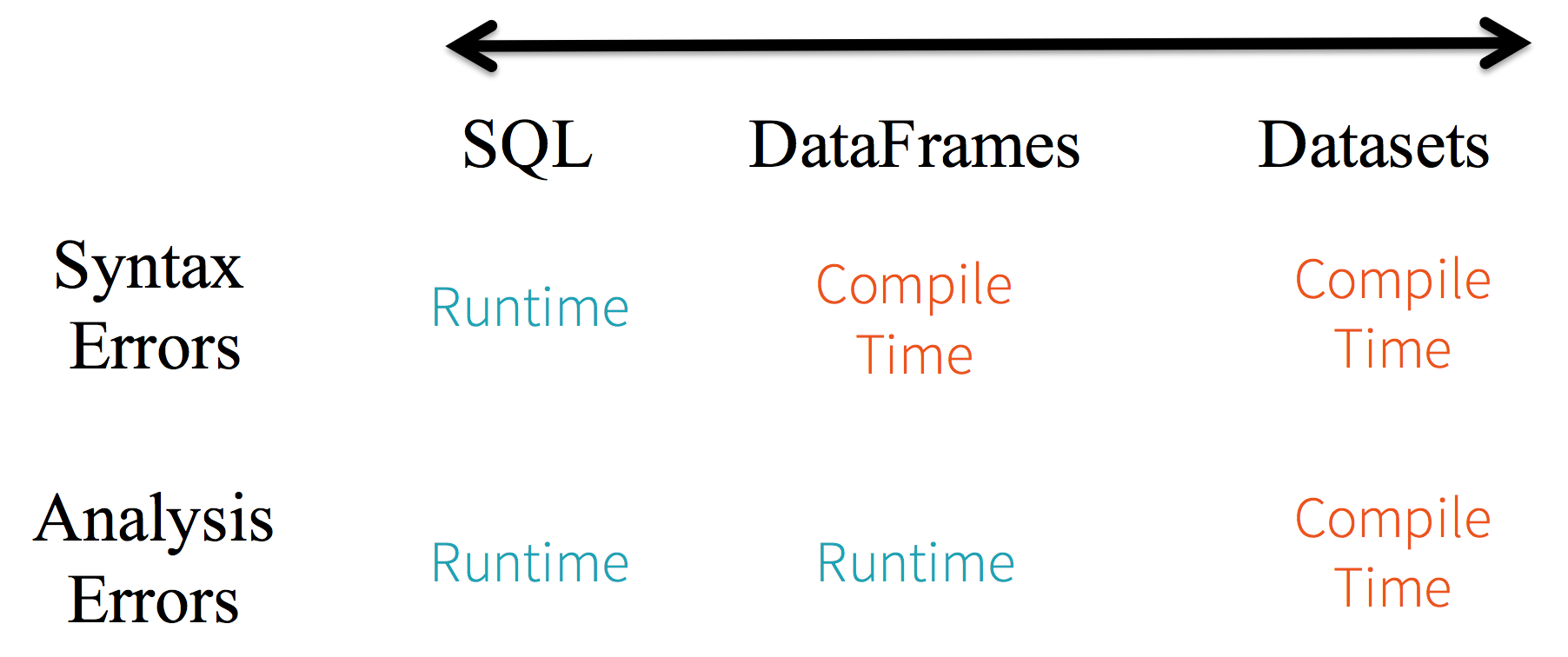
SparkSQL vs Dataframe vs Datasets
Frameless (BETA)
new Spark API, called TypedDataset
Typesafe columns referencing (no more runtime errors when accessing non-existing columns)
Customizable, typesafe encoders (if a type does not have an encoder, it should not compile)
Enhanced type signature for built-in functions (if you apply an arithmetic operation on a non-numeric column, you get a compilation error)
Typesafe casting and projections
Frameless (1)
import spark.implicits._
// Our example case class Foo acting here as a schema
case class Foo(i: Long, j: String)
// Assuming spark is loaded and SparkSession is bind to spark
val initialDs = spark.createDataset( Foo(1, "Q") :: Foo(10, "W") :: Foo(100, "E") :: Nil )
// Assuming you are on Linux or Mac OS
initialDs.write.parquet("/tmp/foo")
val ds = spark.read.parquet("/tmp/foo").as[Foo]
// ds: org.apache.spark.sql.Dataset[Foo] = [i: bigint, j: string]Frameless (2)
ds.show()
// +---+---+
// | i| j|
// +---+---+
// | 1| Q|
// | 10| W|
// |100| E|
// +---+---+
//
//The value ds holds the content of the initialDs read from a parquet file. Let's try to only use field i from Foo and see how Spark's Catalyst (the query optimizer) optimizes this.
// Using a standard Spark TypedColumn in select()
val filteredDs = ds.filter($"i" === 10).select($"i".as[Long])
// filteredDs: org.apache.spark.sql.Dataset[Long] = [i: bigint]
filteredDs.show()
// +---+
// | i|
// +---+
// | 10|
// +---+
//Frameless (3)
// Using a standard Spark TypedColumn in select()
val filteredDs = ds.filter($"i" === 10).select($"i".as[Long])
// filteredDs: org.apache.spark.sql.Dataset[Long] = [i: bigint]
filteredDs.show()
// +---+
// | i|
// +---+
// | 10|
// +---+
//
filteredDs.explain()
// == Physical Plan ==
// *Project [i#1771L]
// +- *Filter (isnotnull(i#1771L) && (i#1771L = 10))
// +- *FileScan parquet [i#1771L] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/foo], PartitionFilters: [], PushedFilters: [IsNotNull(i), EqualTo(i,10)], ReadSchema: struct<i:bigint>Frameless (4)
//Unfortunately, this syntax is not bulletproof: it fails at run-time if we try to access a non existing column x:
scala> ds.filter($"i" === 10).select($"x".as[Long])
org.apache.spark.sql.AnalysisException: cannot resolve '`x`' given input columns: [i, j];;
'Project ['x]
+- Filter (i#1771L = cast(10 as bigint))
+- Relation[i#1771L,j#1772] parquetFrameless (5)
//There are two things to improve:
// * we would want to avoid the as[Long] casting that we are required to type for type-safety.
// * we want a solution where reference to a non existing column name fails at compilation time
// Proposition
ds.filter(_.i == 10).map(_.i).show()
// +-----+
// |value|
// +-----+
// | 10|
// +-----+
//----
// The two closures in filter and map are functions that operate on Foo and the compiler will helps us capture all the mistakes we mentioned above.
//
//scala> ds.filter(_.i == 10).map(_.x).show()
//<console>:20: error: value x is not a member of Foo
// ds.filter(_.i == 10).map(_.x).show()Frameless (6)
// Unfortunately, this syntax does not allow Spark to optimize the code.
ds.filter(_.i == 10).map(_.i).explain()
// == Physical Plan ==
// *SerializeFromObject [input[0, bigint, false] AS value#1805L]
// +- *MapElements <function1>, obj#1804: bigint
// +- *Filter <function1>.apply
// +- *DeserializeToObject newInstance(class $line14.$read$$iw$$iw$$iw$$iw$Foo), obj#1803: $line14.$read$$iw$$iw$$iw$$iw$Foo
// +- *FileScan parquet [i#1771L,j#1772] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/foo], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<i:bigint,j:string>Frameless (7)
import frameless.TypedDataset
import frameless.syntax._
val fds = TypedDataset.create(ds)
// fds: frameless.TypedDataset[Foo] = [i: bigint, j: string]
fds.filter(fds('i) === 10).select(fds('i)).show().run()
// +---+
// | _1|
// +---+
// | 10|
// +---+
//Frameless (8)
//And the optimized Physical Plan:
fds.filter(fds('i) === 10).select(fds('i)).explain()
// == Physical Plan ==
// *Project [i#1771L AS _1#1876L]
// +- *Filter (isnotnull(i#1771L) && (i#1771L = 10))
// +- *FileScan parquet [i#1771L] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/foo], PartitionFilters: [], PushedFilters: [IsNotNull(i), EqualTo(i,10)], ReadSchema: struct<i:bigint>
//And the compiler is our friend.
scala> fds.filter(fds('i) === 10).select(fds('x))
<console>:24: error: No column Symbol with shapeless.tag.Tagged[String("x")] of type A in Foo
fds.filter(fds('i) === 10).select(fds('x))
^Conclusions
To understand Spark you need to understand RDDs
Use Dataframes/Datasets/SparkSQL for the optimisations
Use RDD for custom optimisations
Watch for data shuffles (use the Spark UI)
Use the documentation: http://spark.apache.org/docs/latest/programming-guide.html
TP2 - Spark Dataframes et Datasets
work in spark-notebooks http://andreiarion.github.io/TP6_TPSpark_Dataframes.html
Spark notebooks
Visual tools for data exploration (@scale)
syntax highlight, external tool integration
Spark notebooks
custom interpretors (Scala,Python,R,SQL,Markdown…)
Spark 2.0.2 not yet supported
bleeding edge, most up-to-date, reactive
few bugs, scala only ex. tp !
nothing to install, easy to use, AWS integration, stable, supported
cost! (DBU + subscription)
TP2 - Spark Dataframes et Datasets
work in spark-notebooks http://andreiarion.github.io/TP6_TPSpark_Dataframes.html

{kind=link}