Intro
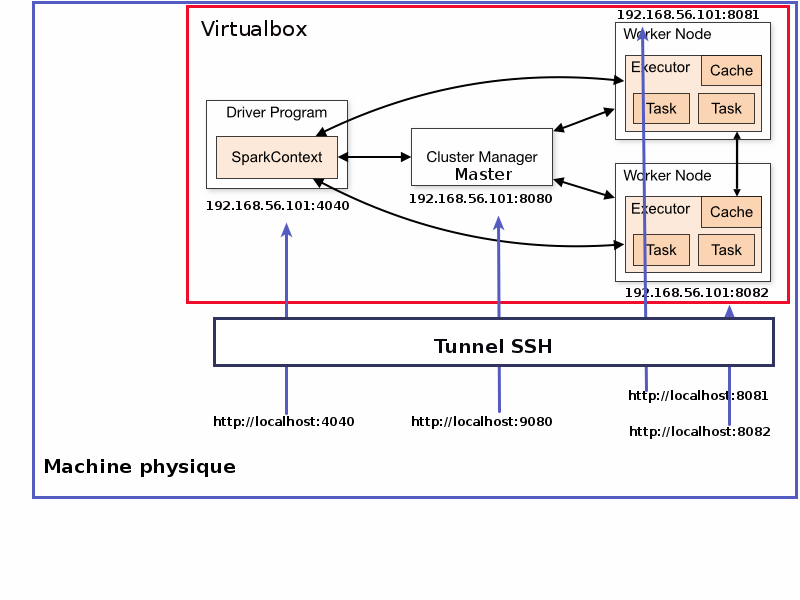
Pour le TP Spark vous allez utiliser une machine virtuelle qui contient un cluster Cassandra de 3 noeuds ainsi que Apache Spark. Le cluster Spark est composé d’un master et d’un noeud worker avec deux executeurs ( documentation deployement standalone) Vous allez vous connecter a cette machine via ssh.
|
Pour ce TP vous avez besoin d’une machine (idéalement linux) avec 4GB de RAM et 4GB d’espace disque disponible. VirtualBox et un client SSH doivent être déjà installés. Si vous etes sous Windows vous pouvez utiliser http://www.putty.org/ |
Connexion en ssh sur la VM depuis votre machine physique
Pour pouvoir accéder à l’interface SparkUI nous allons rediriger 4 ports :
-
le port de SparkUI pour le Spark shell (4040) ⇒ sera dirige sur votre machine physique localhost:4040
-
le port qui contient l’UI du master spark (8080) ⇒ sera dirige sur votre machine physique localhost:9080
-
le port qui contient l’UI du premier worker (8081) ⇒ sera dirige sur votre machine physique localhost:8081
-
le port qui contient l’UI du deuxiem worker (8082) ⇒ sera dirige sur votre machine physique localhost:8082
Pour Windows suivre le tuto suivant: Configuration Tunnel SSH avec putty
-
Connectez vous en ssh sur la VM depuis votre machine physique (un terminal linux/ putty sous windows). On profite pour rediriger les ports locaux de votre machine physique vers les ports de la VM :
[andrei@desktop ~]$ ssh -L 9080:127.0.0.1:8080 \
-L 8081:127.0.0.1:8081 \
-L 8082:127.0.0.1:8082 \
-L 4040:127.0.0.1:4040 \
bigdata@192.168.56.101
bigdata@192.168.56.101's password:
Last login: Sun Jan 4 14:53:32 2015 from pc12.home
[bigdata@bigdata ~]$|
Identifiants de connexion:
Si vous êtes sur Windows vous pouvez utiliser putty |
Demarrage du cluster Spark
Chaque application Spark utilise un programme driver qui sert a lancer des calculs distribués sur un cluster. Ce programme définit les structures de données distribuées dans le cluster ainsi que le DAG d’opérations sur ces structures de données. Un noeud coordinateur(appele aussi master) lancera ces operations sur deux noeuds Worker qui hebergeront un/plusieurs executeur(s).
Configuration de l’environement
Rajouter dans le script de configuration de l’environement spark (conf/spark-env.sh) la ligne export SPARK_WORKER_INSTANCES=2 puis démarrer le master et les workers via le script spark-2.0.2-bin-hadoop2.7/sbin/start-all.sh
[bigdata@bigdata ~]$[bigdata@bigdata ~]$ cat spark-2.0.2-bin-hadoop2.7/conf/spark-env.sh | grep SPARK_WORKER_INSTANCES (1)
# - SPARK_WORKER_INSTANCES, to set the number of worker processes per node
export SPARK_WORKER_INSTANCES=2
[bigdata@bigdata ~]$ spark-2.0.2-bin-hadoop2.7/sbin/start-all.sh (2)
starting org.apache.spark.deploy.master.Master, logging to /home/bigdata/spark-2.0.2-bin-hadoop2.7/logs/spark-bigdata-org.apache.spark.deploy.master.Master-1-bigdata.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /home/bigdata/spark-2.0.2-bin-hadoop2.7/logs/spark-bigdata-org.apache.spark.deploy.worker.Worker-1-bigdata.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /home/bigdata/spark-2.0.2-bin-hadoop2.7/logs/spark-bigdata-org.apache.spark.deploy.worker.Worker-2-bigdata.out| 1 | vérifier la configuration de l’environnement |
| 2 | on utilise le script start-all.sh pour démarrer le master et les workers |
Spark Shell
-
Une fois demarees le master Spark et les Workers on se connecte via le shell Spark:
[bigdata@bigdata ~]$ spark-2.0.2-bin-hadoop2.7/bin/spark-shell\
--master spark://bigdata:7077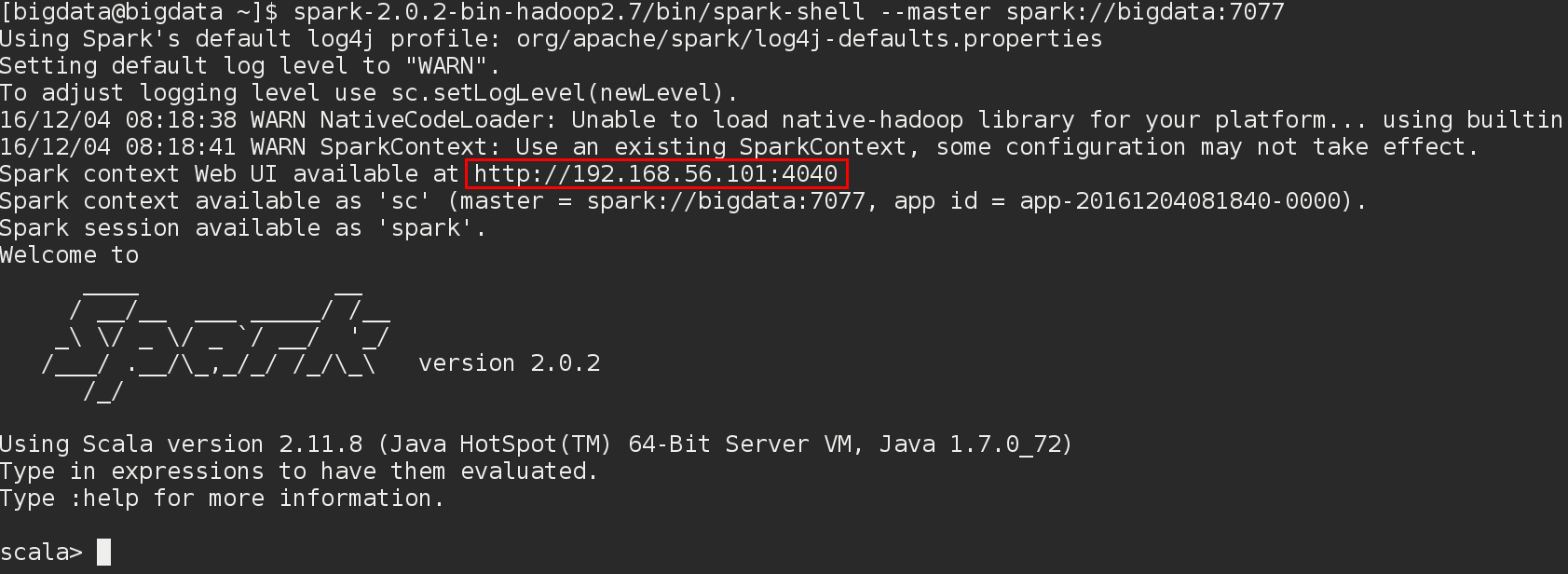
-
Notez le port utilisé par SparkUI dans les messages de démarrage:
Dans ce qui suit on va utiliser le shell Spark comme driver.
Pour se connecter au cluster le shell Spark nous a crée automatiquement un objet sc de type SparkContext :
scala> sc (1)
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@3f10439f
scala> sc.getConf.toDebugString (2)
res1: String =
hive.metastore.warehouse.dir=file:/home/bigdata/spark-warehouse
spark.app.id=app-20161204081840-0000
spark.app.name=Spark shell
spark.driver.host=192.168.56.101
spark.driver.port=33541
spark.executor.id=driver
spark.home=/home/bigdata/spark-2.0.2-bin-hadoop2.7
spark.jars=
spark.master=spark://bigdata:7077
spark.repl.class.outputDir=/tmp/spark-d120dc7d-9f40-4b5d-99ec-91cb46425e2d/repl-e18a9b14-f2d4-4f23-b916-bd61e3dd983b
spark.repl.class.uri=spark://192.168.56.101:33541/classes
spark.sql.catalogImplementation=hive
spark.submit.deployMode=client| 1 | afficher le type de l’objet |
| 2 | sc.getConf.toDebugString permet d’afficher la configuration du cluster |
SparkUI
L’interface SparkUI permet de voir la configuration et l’état du cluster Spark.
Une fois la mise en place des 4 tunnels ssh (4040,8080,8081,8082) vous pouvez vous connecter à:
-
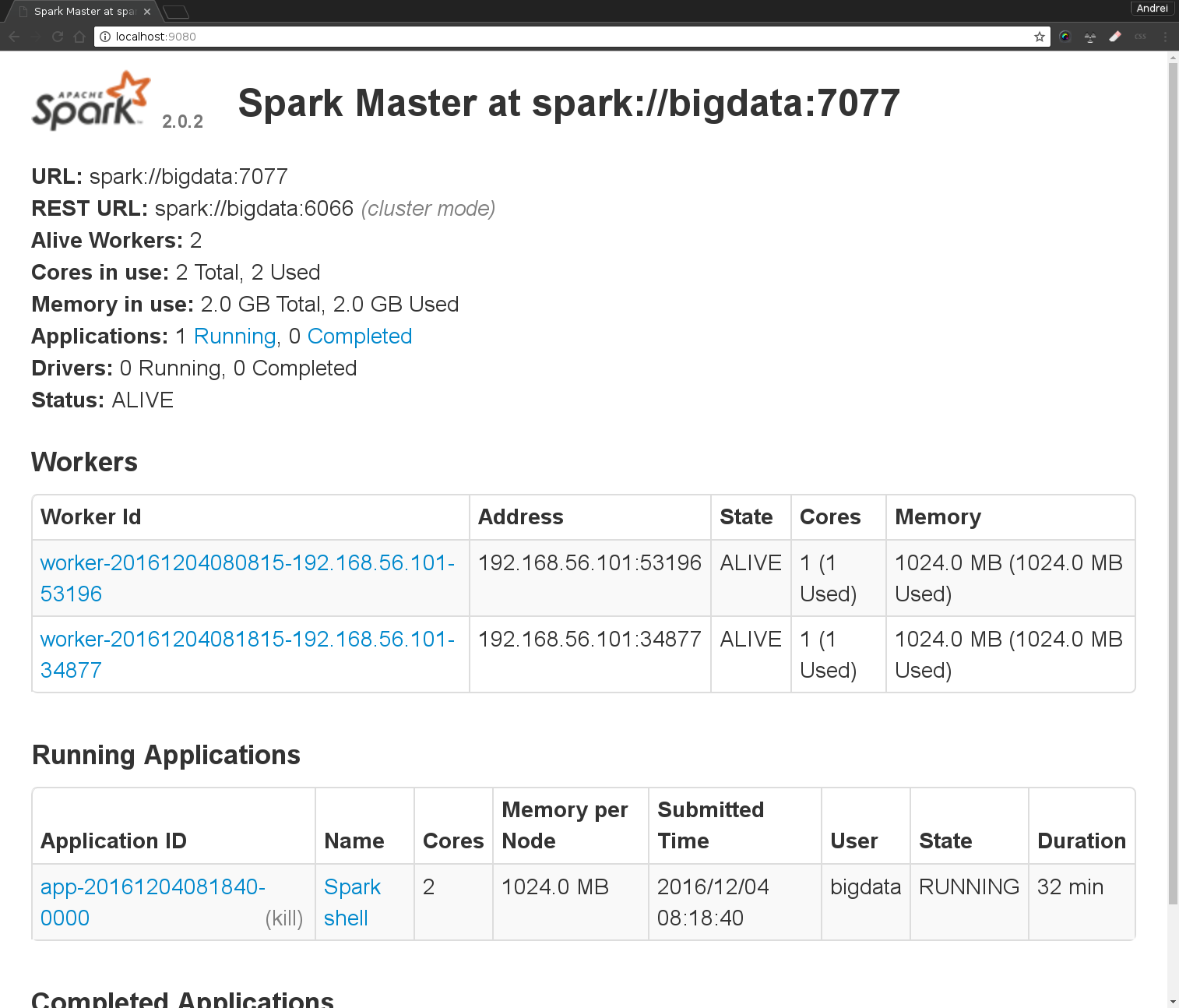
l’interface SparkUI qui tourne sur le master : http://localhost:9080 (permettra de connaitre l’etat du master, voir les jobs et logs)
-
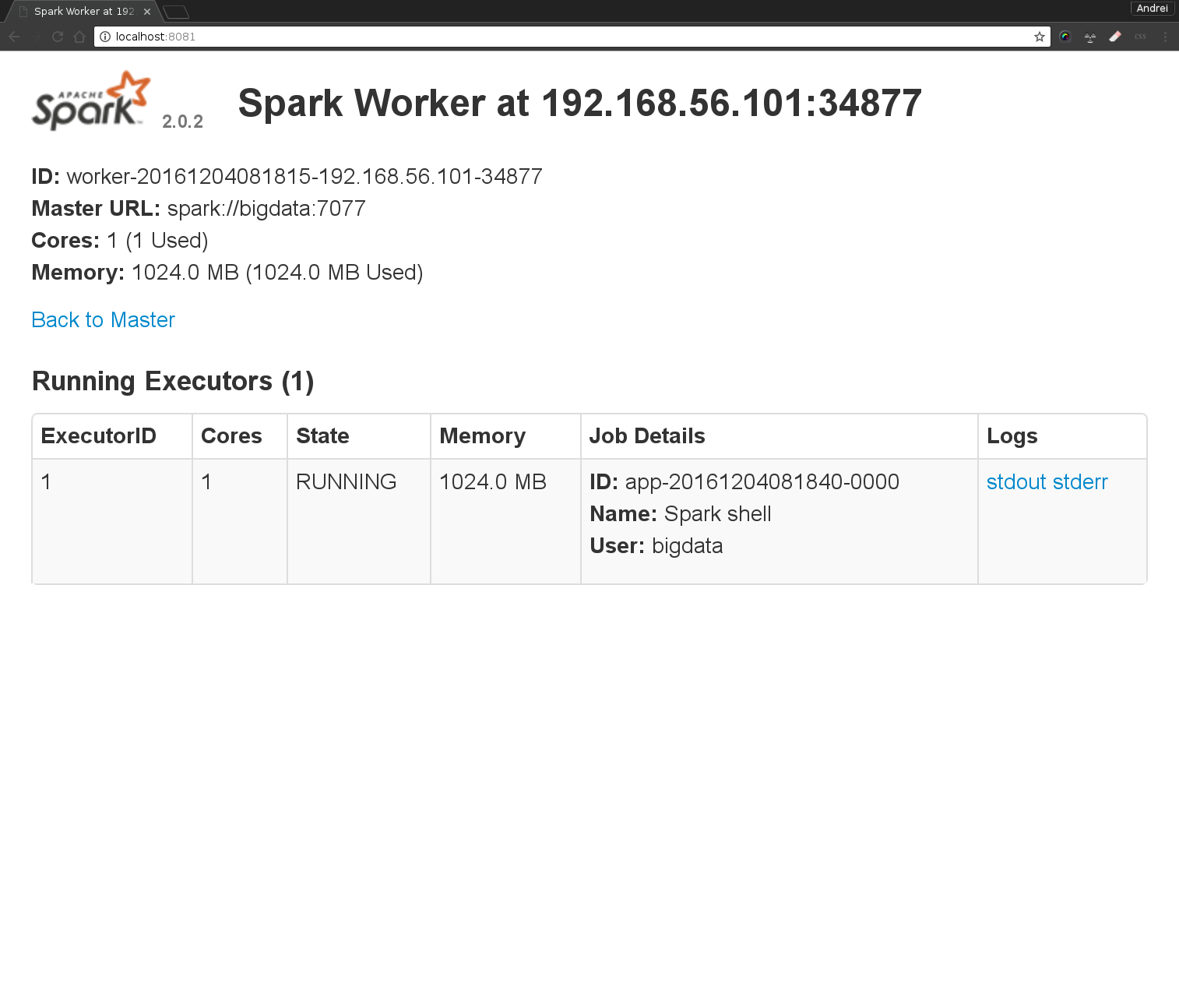
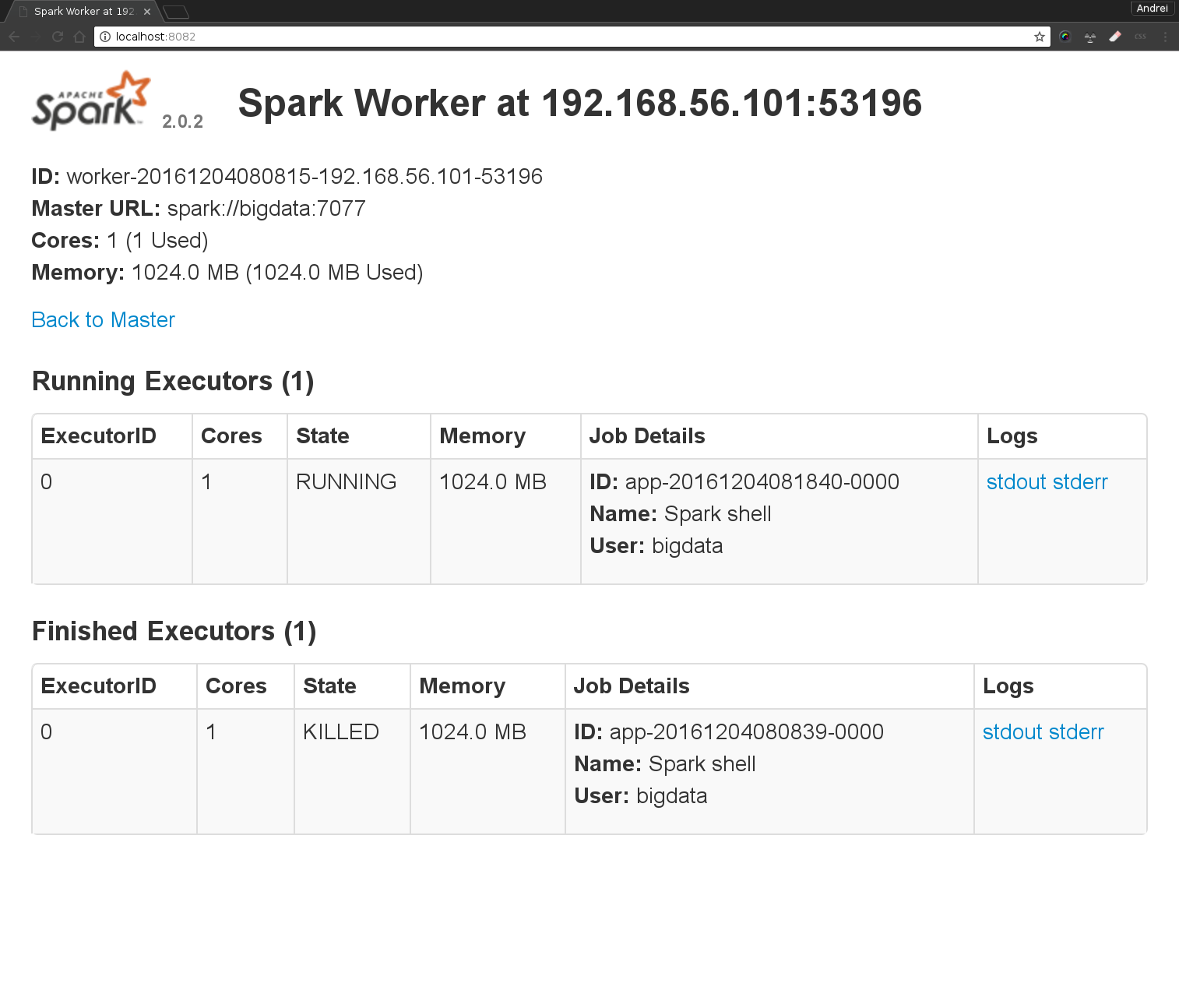
l’interface du Worker 1 : http://localhost:8081 (permettra de connaitre l’etat du worker, voir les jobs et logs)
-
l’interface du Worker 2 : http://localhost:8082 (permettra de connaitre l’etat du worker, voir les jobs et logs)
-
l’interface du driver http://localhost:4040 (permettra de suivre l’execution de nos programmes Spark)
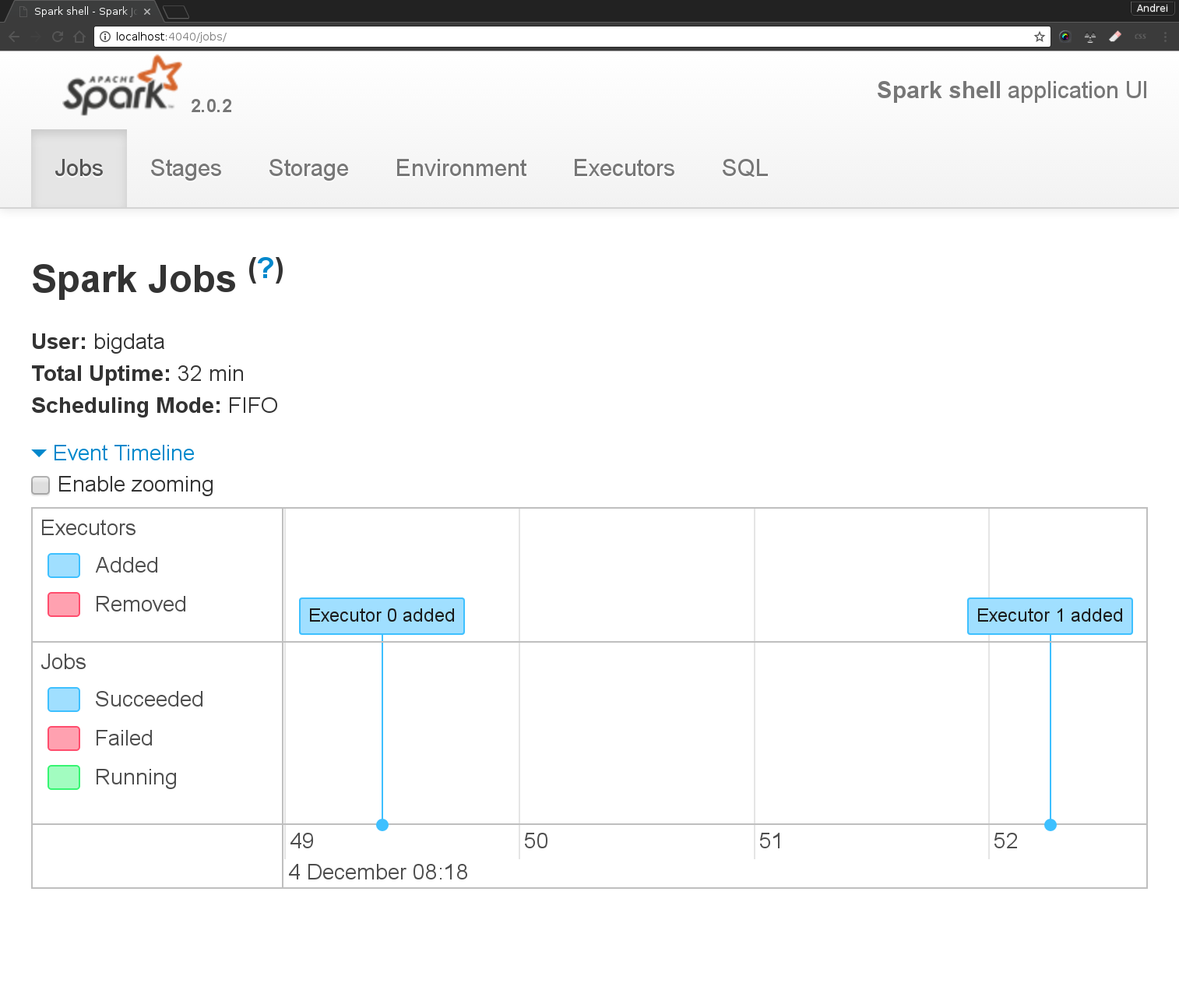
Vérifier dans SparkUI que tous les noeuds worker sont connectés. Quelles sont les informations disponibles sur le cluster? Combien de noeuds sont dans votre cluster?
Spark shell
Excercices scala
Le Spark shell est un shell Scala dans lequel des classes supplémentaires ont été pré-importées et qui construit automatiquement un contexte Spark pour gérer l’échange avec un cluster. Dans Spark shell on peut donc écrire n’importe quelle instruction Scala.
scala> val myNumbers = List(1, 2, 5, 4, 7, 3)(1)
myNumbers: List[Int] = List(1, 2, 5, 4, 7, 3)
scala> def cube(a: Int): Int = a * a * a (2)
cube: (a: Int)Int
scala> myNumbers.map(x => cube(x)) (3)
res2: List[Int] = List(1, 8, 125, 64, 343, 27)
scala> myNumbers.map{x => x * x * x} (4)
res3: List[Int] = List(1, 8, 125, 64, 343, 27)
scala> def even(a:Int):Boolean = { a%2 == 0 } (5)
even: (a: Int)Boolean
scala> myNumbers.map(x=>even(x)) (6)
res4: List[Boolean] = List(false, true, false, true, false, false)
scala> myNumbers.map(even(_)) (7)
res5: List[Boolean] = List(false, true, false, true, false, false)
scala> myNumbers.filter(even(_))(8)
res6: List[Int] = List(2, 4)
scala> myNumbers.foldLeft (9)
def foldLeft[B](z: B)(f: (B, A) => B): B
scala> myNumbers.foldLeft(0)(_+_) (10)
res10: Int = 22| 1 | définir une variable immutable(val) de type List[Int] |
| 2 | définir une fonction qui prend en entrée un entier et retourne le cube |
| 3 | utiliser la fonction map pour appliquer un traitement (ici la fonction cube est appliquée à chaque element de la liste) |
| 4 | utilisation d’une fonction anonyme pour faire le même traitement |
| 5 | definition d’une fonction Int→Boolean qui retourne si un nombre est pair |
| 6 | on transforme la liste des entiers dans une liste de booleans |
| 7 | la même chose qu’avant mais en utilisant une écriture plus compacte |
| 8 | filtrage des numéros paires de la liste |
| 9 | dans le shell on peut utiliser l’aide via la touche TAB. Ecrire myNumbers.foldLeft puis appuyer sur TAB permet d’afficher la signature de la function foldLeft de scala. Elle prend deux listes d’arguments ⇒ un élèment neutre de type B et une fonction f: (B, A) ⇒ B |
| 10 | utilisation de foldLeft pour calculer la somme des élèments de la liste |
Ecrire une courte séquence Scala qui affiche les nombres inférieurs à 1000 à la fois divisibles par 2 et par 13 .
-
Version non parallelisée (Scala uniquement)
scala> val data = 1 to 1000 (1) data: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170... scala> val filteredData= data.filter(n=> (n%2==0) && (n%13==0) ) (2) filteredData: scala.collection.immutable.IndexedSeq[Int] = Vector(26, 52, 78, 104, 130, 156, 182, 208, 234, 260, 286, 312, 338, 364, 390, 416, 442, 468, 494, 520, 546, 572, 598, 624, 650, 676, 702, 728, 754, 780, 806, 832, 858, 884, 910, 936, 962, 988)
| 1 | génerer une séquence (du type Scala scala.collection.immutable.Range.Inclusive) de tous les nombres de 1 à 1000. Cette séquence sera stockée dans la variable immutable data |
| 2 | garder les nombres qui sont divisible par 2 et 13 |
|
Dans l’exemple précedent on n’a pas utilisé le context Spark (l’objet sc). Les objets qu’on a manipulé sont les objets des collections standard Scala. |
Exercices RDDs
1.1 Utiliser Spark pour distribuer les données et le filtrage de l’exercice precedent sur le cluster Spark.
scala> val data = 1 to 1000 (1)
data: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170...
scala> val paralelizedData= sc.parallelize(data) (2)
paralelizedData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:14
scala> val filteredData=A_COMPLETER (3)
filteredData: org.apache.spark.rdd.RDD[Int] = FilteredRDD[1] at filter at <console>:16
scala> filteredData.collect (4)
...| 1 | géneration des données (! dans la JVM du driver/shell Spark) |
| 2 | créer un RDD (paralelizedData) qui va contenir les données (distribuées sur les noeuds du cluster) |
| 3 | créer un RDD (filteredData) qui va contenir les données filtrées (distribuées sur les noeuds du cluster) |
| 4 | lancer l’action (collect) qui va déclencher le traitement parallèle et va retourner le résultat Suivre dans le UI l’execution de votre script Spark http://localhost:4040. |
1.2 Ecrire une courte séquence Scala/Spark qui affiche la somme des nombres paires de 1 a 1000 (utilisez la fonction fold disponible sur un RDD qui est similaire a foldLeft de scala).
1.3 Ecrire une courte séquence Scala/Spark qui affiche le produit des nombres paires de 1 a 1000.
1.4 Combiner les deux derniers programmes en un seul. Mettre en cache les données au niveau des noeuds et vérifier la répartition des ces données via le Spark UI
scala> val parDataCached = sc.parallelize(1 to 1000).filter(_%2==0).cache (1)
parDataCached: org.apache.spark.rdd.RDD[Int] = FilteredRDD[6] at filter at <console>:13
scala> parDataCached.fold(0)(_+_) (2)
res7: Int = 250500
scala> parDataCached.TODO (2)| 1 | définition d’un RDD qui va stocquer tous les nombres paires sur les noeuds |
| 2 | ré-utilisation du RDD pour calculer la somme et le produit de ces nombres ( A FAIRE) |
Vous pouvez vérifier sur les noeuds le contenu du RDD mis en cache via le SparkUI (http://localhost:4040/storage/ puis cliquer sur le lien dans la colonne RDD Name)
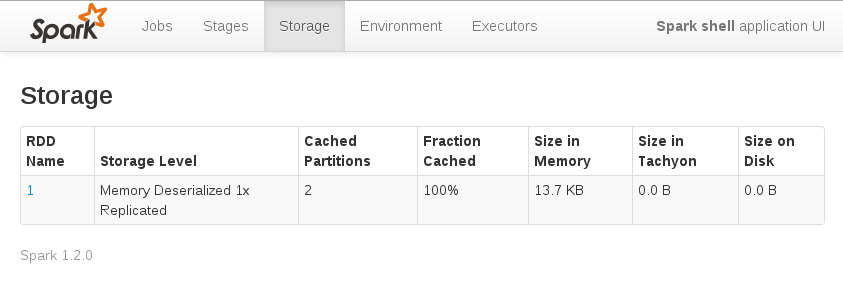
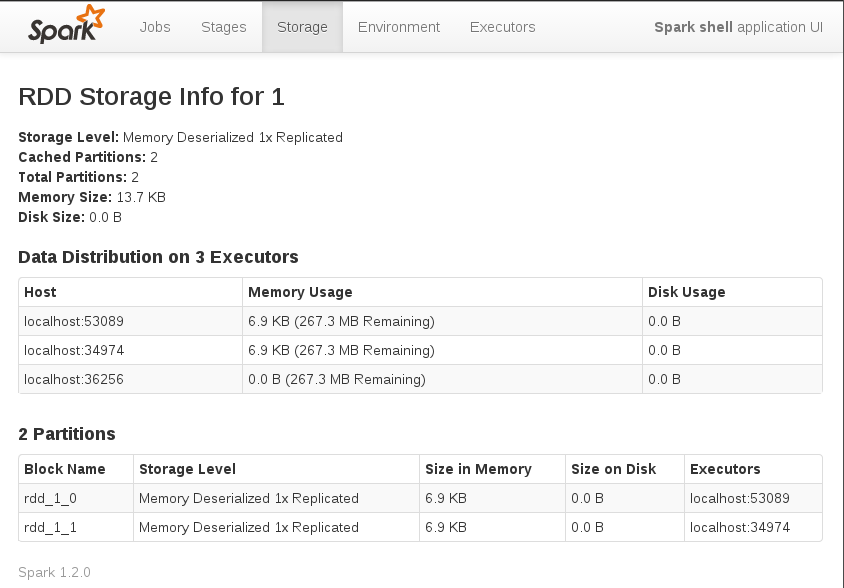
1.5 WordCount: écrire le programme pour compter l’occurence des mots du fichier /home/bigdata/spark-2.0.2-bin-hadoop2.7/README.md.
1.6 Ecrire le programme qui donne le mot le plus souvent utilisé du fichier (vous pouvez utiliser sortByKey après avoir inversé la liste des paires (mot,nb_occurences)). Suivez via le SparkUI les stage d’executions de votre traitement (http://localhost:4040/)
SparkSQL
3.1 Utiliser SparkSQL pour trouver dans le fichier /home/bigdata/spark-2.0.2-bin-hadoop2.7/examples/src/main/resources/people.txt les noms des personnes qui ont moins de 19 ans
val sqlContext = new org.apache.spark.sql.SQLContext(sc) (1)
case class Person(name: String, age: Int) (2)
val people = sc.textFile("/home/bigdata/spark-2.0.2-bin-hadoop2.7/examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF (3)
people.createOrReplaceTempView("people") (4)
val teenagers = sql("TODO") (5)
teenagers.show (6)| 1 | création d’un contexte SQLContext |
| 2 | définition du modèle de données en utilisant une case classe Scala |
| 3 | création d’un dataframe Spark a partir d’un RDD |
| 4 | enregistrement du dataframe dans une table temporaire |
| 5 | requêtage sur la table → A COMPLETER ! |
| 6 | le résultat d’une requête SparkSQL est un DataFrame, nous utilisons la methode show to afficher son contenu |
Spark et Cassandra
|
Démarrer votre cluster Cassandra et vérifier qu’il est démarré: |
Pour se connecter a Cassandra depuis le shell Spark il faut arrêter le shell (Ctrl+C or Ctrl+D) puis le redémarrer en ajoutant en paramètre l’adresse d’un noeud Cassandra et la dependence vers le connecteur spark-cassandra:
[bigdata@bigdata ~]$ spark-2.0.2-bin-hadoop2.7/bin/spark-shell --master spark://bigdata:7077 --conf spark.cassandra.connection.host=127.0.0.1 --packages datastax:spark-cassandra-connector:2.0.0-M2-s_2.113.1 WordCount avec Spark et Cassandra
scala> import com.datastax.spark.connector._ (1)
import com.datastax.spark.connector._
scala> val rdd = sc.cassandraTable("temperature", "temp1") (2)
rdd: com.datastax.spark.connector.rdd.CassandraTableScanRDD[com.datastax.spark.connector.CassandraRow] = CassandraTableScanRDD[0] at RDD at CassandraRDD.scala:18
scala> rdd.collect (3)
res0: Array[com.datastax.spark.connector.CassandraRow] = Array(CassandraRow{ville: Paris, date: 2016-12-01 00:00:00+0100, temperature: 4}, CassandraRow{ville: Rennes, date: 2016-12-01 00:02:00+0100, temperature: 8}, CassandraRow{ville: Rennes, date: 2016-12-01 00:01:00+0100, temperature: 7}, CassandraRow{ville: Paris, date: 2016-12-01 00:02:00+0100, temperature: 6}, CassandraRow{ville: Rennes, date: 2016-12-01 00:00:00+0100, temperature: 6}, CassandraRow{ville: Paris, date: 2016-12-01 00:01:00+0100, temperature: 5})
scala>import com.datastax.spark.connector.cql.CassandraConnector (4)
scala>CassandraConnector(sc.getConf).withSessionDo { session =>
session.execute(s"CREATE KEYSPACE IF NOT EXISTS demo WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1 }")
session.execute(s"CREATE TABLE IF NOT EXISTS demo.wordcount (word TEXT PRIMARY KEY, count COUNTER)")
session.execute(s"TRUNCATE demo.wordcount")
} (5)
scala>val rdd= sc.textFile("/home/bigdata/spark-2.0.2-bin-hadoop2.7/README.md").flatMap(_.split("[^a-zA-Z0-9']+")).map(word => (word.toLowerCase, 1)).reduceByKey(_ + _).filter(x => x._1!="")(6)
scala>rdd.collect.foreach(println(_))
scala> rdd.saveToCassandra("demo","wordcount") <(7)
scala> sc.cassandraTable("demo", "wordcount").collect (8)| 1 | importer toutes les classes du pacakge com.datastax.spark.connector. |
| 2 | creer un RDD a partir de la table de temperatures. |
| 3 | collecter le RDD et afficher les temperatures |
| 4 | import de la classe CassandraConnector du package cql |
| 5 | creer un nouveau keyspace et une nouvelle table |
| 6 | créer un RDD avec les occurence des mots du fichier README.md |
| 7 | sauver ce RDD dans la table Cassandra wordcount |
| 8 | afficher le contenu de la table wordcount |