def fileDownloader(urlOfFileToDownload: String, fileName: String) = {
val url = new URL(urlOfFileToDownload)
val connection = url.openConnection().asInstanceOf[HttpURLConnection]
connection.setConnectTimeout(5000)
connection.setReadTimeout(5000)
connection.connect()
if (connection.getResponseCode >= 400)
println("error")
else
url #> new File(fileName) !!
}
fileDownloader("http://data.gdeltproject.org/gdeltv2/masterfilelist.txt",
"/home/aar/bigdata/proj2022/data/masterfilelist.txt") // save the list file to the Spark MasterProjet Bigdata
Andrei Arion, LesFurets.com, tp-bigdata@lesfurets.com
Plan
GDELT
Projet propose
TP: exploration des donnes GDELT + reflexion sujets de projet

GDELT
" The Global Database of Events, Language, and Tone monitors the world’s broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organizations, themes, sources, emotions, counts, quotes, images and events driving our global society every second of every day, creating a free open platform for computing on the entire world.
GDELT Database

GDELT pipeline (summarised by Olivier Dupuis)
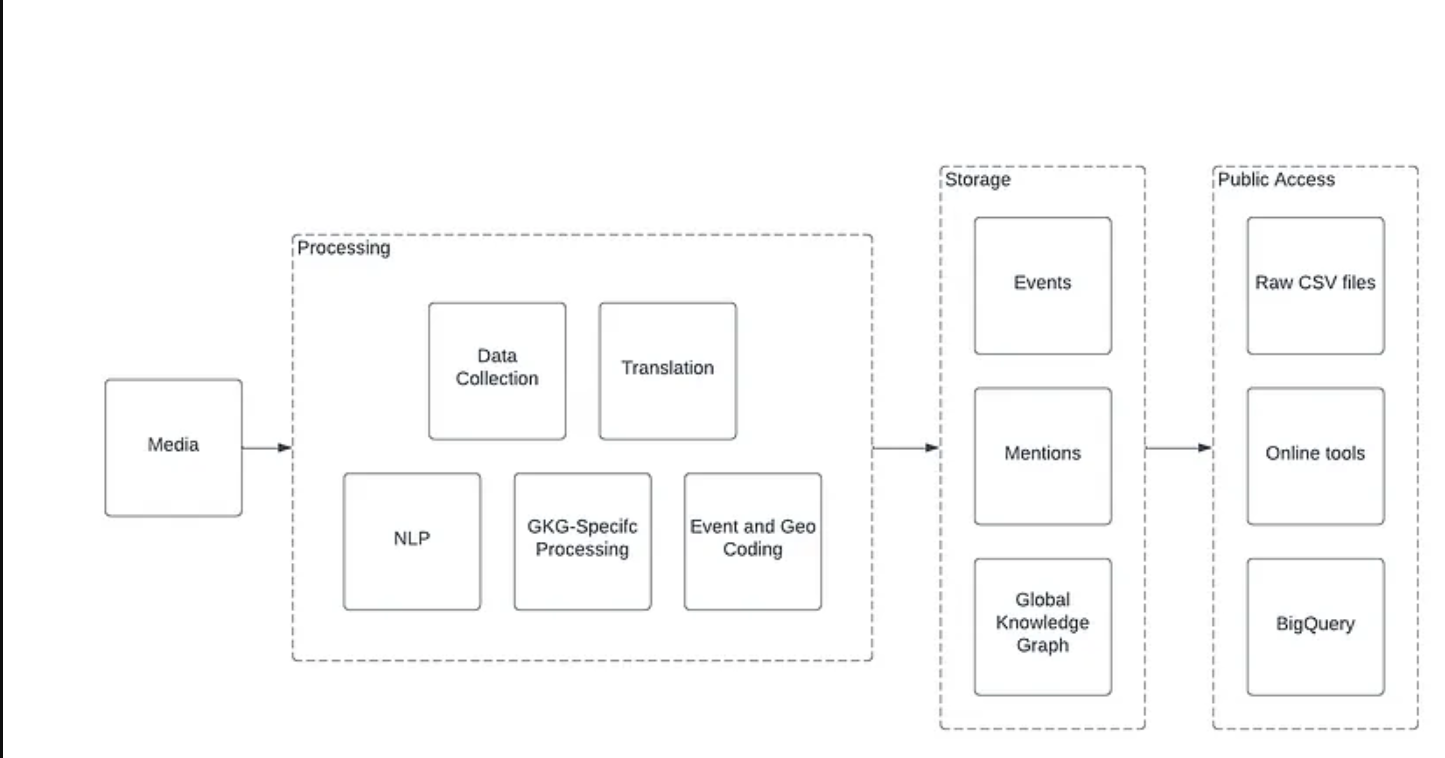
Jeu de données GDELT
trois types de fichiers CSV compresses:
les events (CAMEO Ontology, documentation)
les mentions (documentation)
le graph des conaissances ⇒ GKG, Global Knowledge Graph ( documentation)
Index des fichiers
masterfilelist.txt Master CSV Data File List – English
masterfilelist-translation.txt Master CSV Data File List – GDELT Translingual
Disponibilite des donnees
access libre sur http://data.gdeltproject.org/gdeltv2/
disponible egalement sur Google BigQuery
pratique pour explorer la structure des donnees, generation des types de donnees, donees anexes
GDELT projects
Beyond GDELT
discursus.io : example of use of GDELT

discursus.io Social Movements
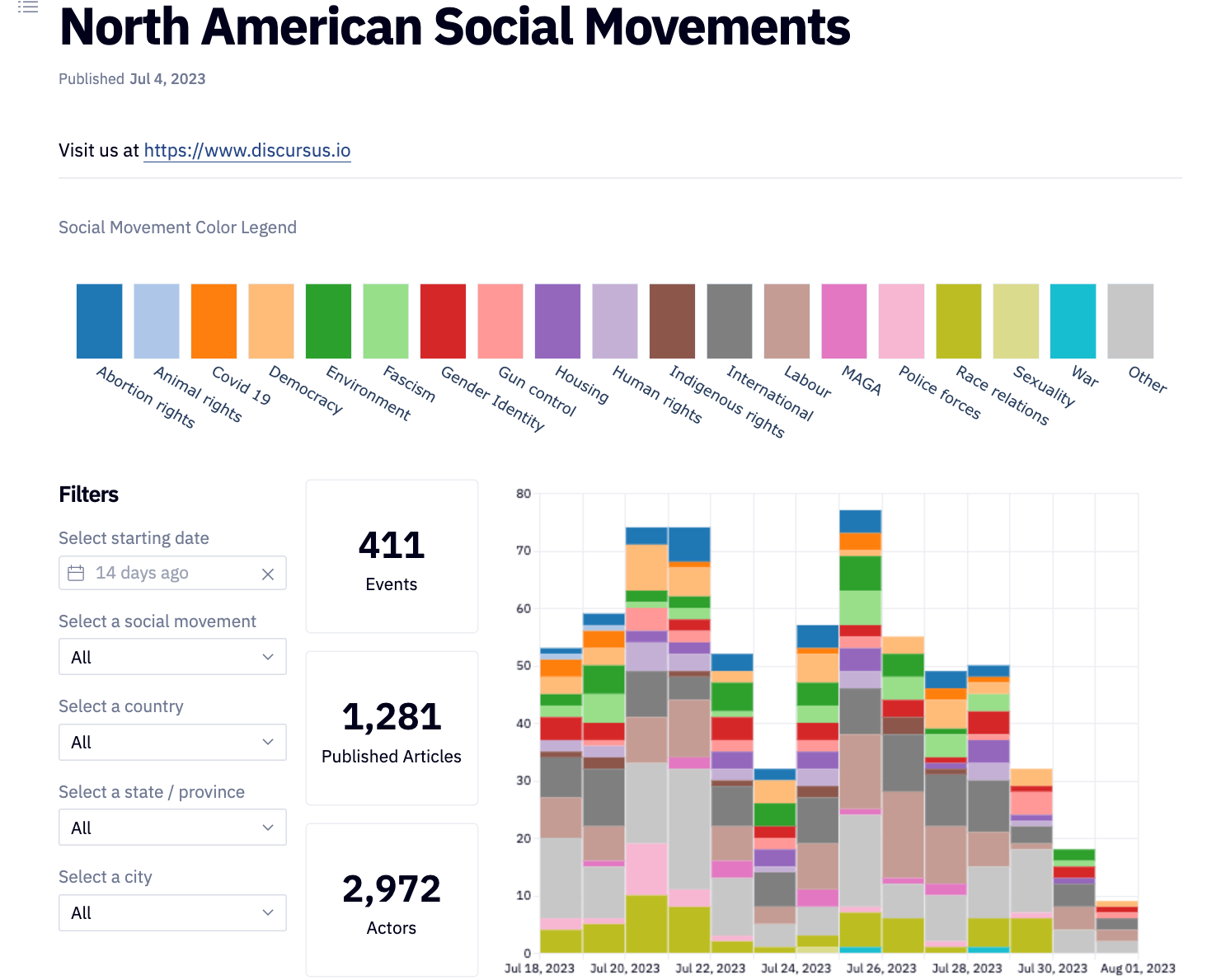
discursus.io Relations Between Movements
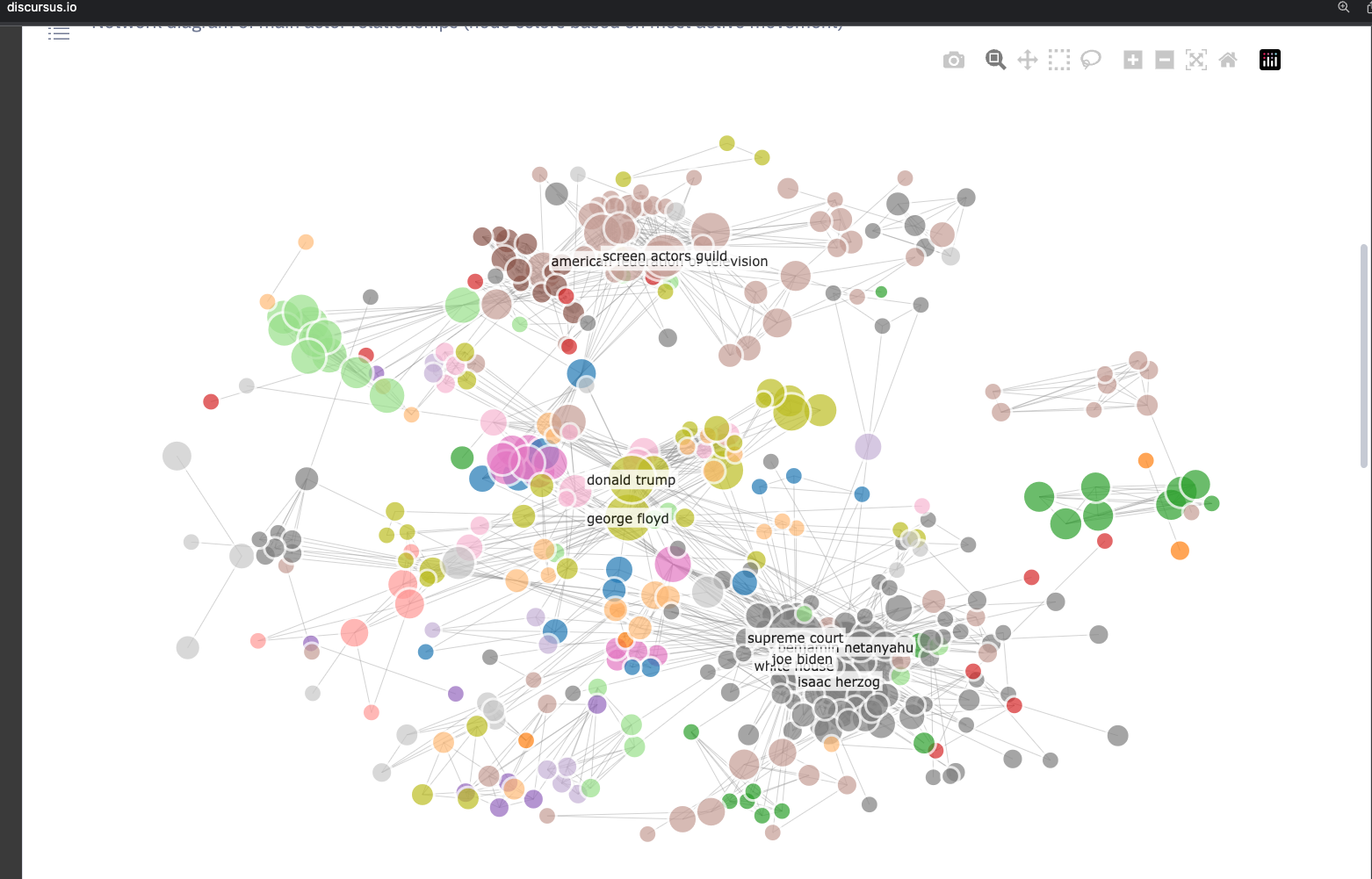
discursus.io Data Pipeline
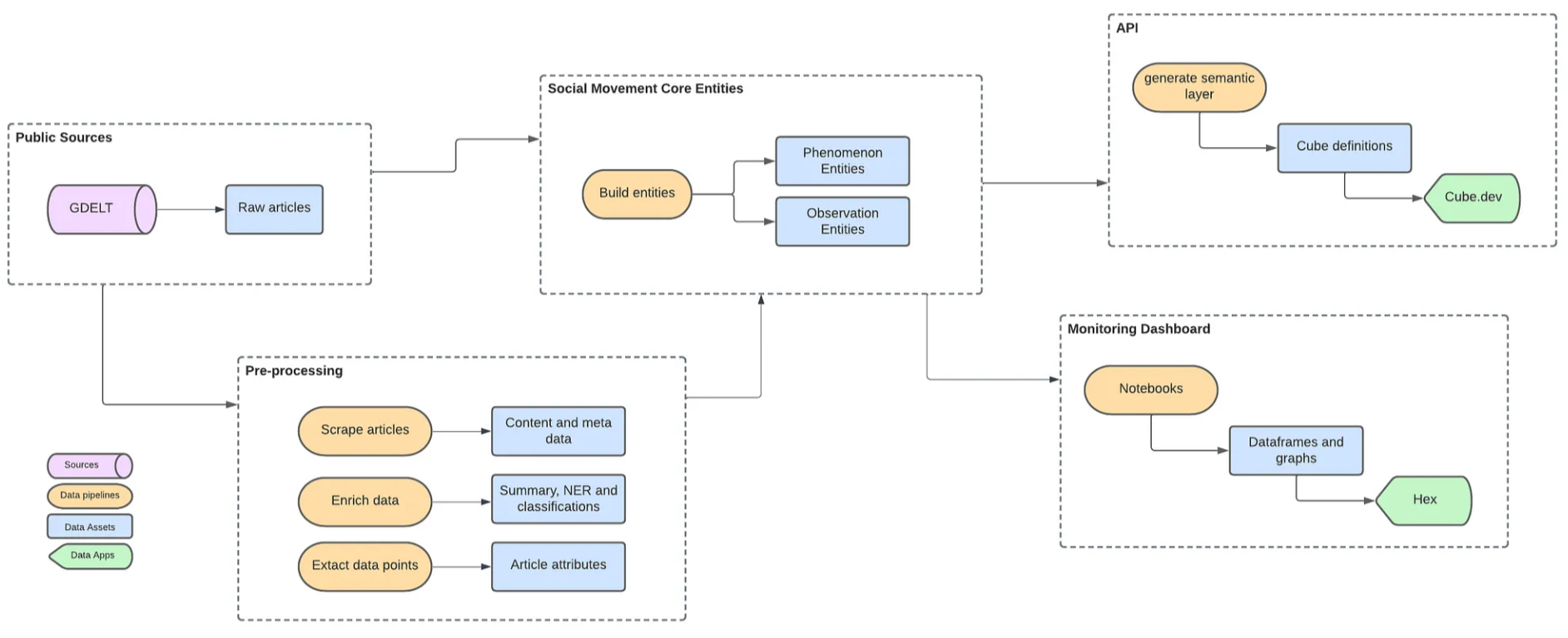
Olivier Dupuis - discursus.io blog series
Projet Bigdata:
PROJET AU CHOIX (note /23)
GDELT: Les evenements marquants de l’année (note /20)
Objectif
L’objectif de ce projet est de mettre en œuvre les technologies presentees dans ce module pour proposer un système de stockage distribué, résilient et performant pour répondre a une problematique specifique qui traite des donnees d’une volumetrie importante.
Vous pouvez utiliser toutes sources de donnees disponibles.
Contraintes:
taille du jeu de donnes initial > 100GB
taille du jeu de donnees stoques > 5GB
le systeme devrait repondre a 3-4 requetes de votre choix pour addresser une problematique specifique (a valider avec les encadrants)
vous devez utiliser au moins 1 technologie vue en cours en expliquant les raisons de votre choix (SQL/Cassandra/MongoDB/Spark/Neo4j8)
lors de la soutenance, les données devront être préalablement chargées dans votre cluster. Vous devez démontrer la résilience de votre système de stocquage en desactivant un noeud de votre clusteur.
Organisation
Vous allez travailler par groupe de 4 personnes. Nous aurons 3 seances encadres pour: le cadrage du projet(sujet/archi), repondre a vos questions ou bien travail individuel.
La composition du group et le sujet valide avec les intervenants devraient etre envoyes par email au plus tard le 13/01/2023 (dernier delai)
Environnement:
vous allez utiliser les VMs du module Hadoop (donc les 8 machines/VMs des 4 personnes du group).
Soutenance
La soutenance se déroulera de la manière suivante:
Présentation: 15 minutes
Démo: 10 minutes
Questions & Réponses : 10 minutes
Projet: Les evenements marquants de l’annee
Objectif: Proposer un système de stockage distribué, resilient et performant pour les données de GDELT.
Fonctionnalités
afficher le nombre d’articles/évènements qu’il y a eu pour chaque triplet (jour, pays de l’évènement, langue de l’article).
pour un pays donné en paramètre, affichez les évènements qui y ont eu place triées par le nombre de mentions (tri décroissant); permettez une agrégation par jour/mois/année
pour une source de donnés passée en paramètre (gkg.SourceCommonName) affichez les thèmes, personnes, lieux dont les articles de cette sources parlent ainsi que le nombre d’articles et le ton moyen des articles (pour chaque thème/personne/lieu); permettez une agrégation par jour/mois/année.
étudiez l’évolution des relations entre deux pays (specifies en paramètre) au cours de l’année. Vous pouvez vous baser sur la langue de l’article, le ton moyen des articles, les themes plus souvent citées, les personalités ou tout element qui vous semble pertinent.
C. Contraintes
au moins 1 technologie vue en cours en expliquant les raisons de votre choix
système distribué et tolérant aux pannes
une annee de données (commencez par tester sur 1 heure, 1 jour, 1 mois!)
D. Les livrables
code source (lien sur github…)
presentation: architecture, modélisation, les avantages et inconvénients, des choix de modélisation et d’architecture, volumetrie, limites et contraintes
Notation
qualité et clarte de presentation (5/20)
infra/performances/budget (5/20)
implementation des fonctionnalités (modelisation/stoquage/requetage) (10/20)
F. Organisation
travail en equipe (4 personnes )
soutenance
Présentation: 15 minutes
Démo: 10 minutes
Questions & Réponses : 10 minutes
F. Demo
les données devront être préalablement chargées dans votre cluster
demo des fonctionnalités
démontrer la resilience de votre systeme (chaos monkey)
Questions ?
Exemple: Exploration des donnees GDELT
exploration du jeu de donnees, reflexions sur l’architecture a mettre en place
Approche:
explorer les donnees: types/organisation/volumetrie
explorer les fonctionalitees demandees
identifier les agregats, comment les stocquer
⇒ decider la techno/modelisation
tests/ajustements/optimisations
Disponibilite des donnees
telechargement depuis http://data.gdeltproject.org/
copie en local
Script de telechargement
Stockage (parallel)
sqlContext.read.
option("delimiter"," ").
option("infer_schema","true").
csv("/tmp/data/masterfilelist-translation.txt").
withColumnRenamed("_c2","url").
filter(col("url").contains("/202212")).
repartition(200).foreach( r=> {
val URL = r.getAs[String](0)
val fileName = r.getAs[String](0).split("/").last
val dir = "/home/aar/bigdata/gdelt/"
val localFileName = dir + fileName
fileDownloader(URL, localFileName)
val localFile = new File(localFileName)
})Chargement events
val eventsRDD = sc.binaryFiles(".../data/20221[0-9]*.export.CSV.zip",100).
flatMap { // decompresser les fichiers
case (name: String, content: PortableDataStream) =>
val zis = new ZipInputStream(content.open)
Stream.continually(zis.getNextEntry).
takeWhile(_ != null).
flatMap { _ =>
val br = new BufferedReader(new InputStreamReader(zis))
Stream.continually(br.readLine()).takeWhile(_ != null)
}
}
val cachedEvents = eventsRDD.cache // RDDcachedEvents.take(1)
res5: Array[String] = Array(807502237 20171204 201712 2017 2017.9151 LEG LAWMAKER LEG 0 036 036 03 1 4.0 2 1 2 -4.47928331466966 0 3 Salem, Oregon, United States US USOR OR047 44.9429 -123.035 1167861 3 Salem, Oregon, United States US USOR OR047 44.9429 -123.035 1167861 20221204094500 https://pamplinmedia.com/pt/10-opinion/413643-314656-our-opinion-tough-call-crucial-for-easing-pers-debt)----RDD / DataSets / SparkSQL
Use types stored in BigQuery
~/b/p/schema ❯❯❯ google-cloud-sdk/bin/bq show --format=prettyjson gdelt-bq:gdeltv2.events
{
"creationTime": "1463679409113",
"etag": "O5/wP5Yg/W1CN+rDMM85/w==",
"id": "gdelt-bq:gdeltv2.events",
"kind": "bigquery#table",
"lastModifiedTime": "1545240340088",
"location": "US",
"numBytes": "171542041673",
"numLongTermBytes": "0",
"numRows": "399903677",
"schema": {
"fields": [
{
"description": "Globally unique identifier assigned to each event record that uniquely identifies it in the master dataset. NOTE: While these will often be sequential with date, this is NOT always the case and this field should NOT be used to sort events by date: the date fields should be used for this. NOTE: There is a large gap in the sequence between February 18, 2015 and February 19, 2015 with the switchover to GDELT 2.0 \u2013 these are not missing events, the ID sequence was simply reset at a higher number so that it is possible to easily distinguish events created after the switchover to GDELT 2.0 from those created using the older GDELT 1.0 system.",
"mode": "NULLABLE",
"name": "GLOBALEVENTID",
"type": "INTEGER"
},
{
"description": "Date the event took place in YYYYMMDD format. See DATEADDED field for YYYYMMDDHHMMSS date.",
"mode": "NULLABLE",
"name": "SQLDATE",
"type": "INTEGER"
},
{
"description": "Alternative formatting of the event date, in YYYYMM format.",
"mode": "NULLABLE",
"name": "MonthYear",
"type": "INTEGER"
},
{
"description": "Alternative formatting of the event date, in YYYY format.",
"mode": "NULLABLE",
"name": "Year",
"type": "INTEGER"
},
{
"description": "Alternative formatting of the event date, computed as YYYY.FFFF, where FFFF is the percentage of the year completed by that day. This collapses the month and day into a fractional range from 0 to 0.9999, capturing the 365 days of the year. The fractional component (FFFF) is computed as (MONTH * 30 + DAY) / 365. This is an approximation and does not correctly take into account the differing numbers of days in each month or leap years, but offers a simple single-number sorting mechanism for applications that wish to estimate the rough temporal distance between dates.",
"mode": "NULLABLE",
"name": "FractionDate",
"type": "FLOAT"
},
{
"description": "The complete raw CAMEO code for Actor1 (includes geographic, class, ethnic, religious, and type classes). May be blank if the system was unable to identify an Actor1.",
"mode": "NULLABLE",
"name": "Actor1Code",
"type": "STRING"
},
{
"description": "The actual name of the Actor1. In the case of a political leader or organization, this will be the leader\u2018s formal name (GEORGE W BUSH, UNITED NATIONS), for a geographic match it will be either the country or capital/major city name (UNITED STATES / PARIS), and for ethnic, religious, and type matches it will reflect the root match class (KURD, CATHOLIC, POLICE OFFICER, etc). May be blank if the system was unable to identify an Actor1.",
"mode": "NULLABLE",
"name": "Actor1Name",
"type": "STRING"
},
{
"description": "The 3-character CAMEO code for the country affiliation of Actor1. May be blank if the system was unable to identify an Actor1 or determine its country affiliation (such as \u201cUNIDENTIFIED GUNMEN\u201d).",
"mode": "NULLABLE",
"name": "Actor1CountryCode",
"type": "STRING"
},
{
"description": "If Actor1 is a known IGO/NGO/rebel organization (United Nations, World Bank, al-Qaeda, etc) with its own CAMEO code, this field will contain that code.",
"mode": "NULLABLE",
"name": "Actor1KnownGroupCode",
"type": "STRING"
},
{
"description": "If the source document specifies the ethnic affiliation of Actor1 and that ethnic group has a CAMEO entry, the CAMEO code is entered here. NOTE: a few special groups like ARAB may also have entries in the type column due to legacy CAMEO behavior. NOTE: this behavior is highly experimental and may not capture all affiliations properly \u2013 for more comprehensive and sophisticated identification of ethnic affiliation, it is recommended that users use the GDELT Global Knowledge Graph\u2018s ethnic, religious, and social group taxonomies and post-enrich actors from the GKG.",
"mode": "NULLABLE",
"name": "Actor1EthnicCode",
"type": "STRING"
},
{
"description": "If the source document specifies the religious affiliation of Actor1 and that religious group has a CAMEO entry, the CAMEO code is entered here. NOTE: a few special groups like JEW may also have entries in the geographic or type columns due to legacy CAMEO behavior. NOTE: this behavior is highly experimental and may not capture all affiliations properly \u2013 for more comprehensive and sophisticated identification of ethnic affiliation, it is recommended that users use the GDELT Global Knowledge Graph\u2018s ethnic, religious, and social group taxonomies and post-enrich actors from the GKG.",
"mode": "NULLABLE",
"name": "Actor1Religion1Code",
"type": "STRING"
},
{
"description": "If multiple religious codes are specified for Actor1, this contains the secondary code. Some religion entries automatically use two codes, such as Catholic, which invokes Christianity as Code1 and Catholicism as Code2.",
"mode": "NULLABLE",
"name": "Actor1Religion2Code",
"type": "STRING"
},
{
"description": "The 3-character CAMEO code of the CAMEO \u201ctype\u201d or \u201crole\u201d of Actor1, if specified. This can be a specific role such as Police Forces, Government, Military, Political Opposition, Rebels, etc, a broad role class such as Education, Elites, Media, Refugees, or organizational classes like Non-Governmental Movement. Special codes such as Moderate and Radical may refer to the operational strategy of a group.",
"mode": "NULLABLE",
"name": "Actor1Type1Code",
"type": "STRING"
},
{
"description": "If multiple type/role codes are specified for Actor1, this returns the second code.",
"mode": "NULLABLE",
"name": "Actor1Type2Code",
"type": "STRING"
},
{
"description": "If multiple type/role codes are specified for Actor1, this returns the third code.",
"mode": "NULLABLE",
"name": "Actor1Type3Code",
"type": "STRING"
},
{
"description": "The complete raw CAMEO code for Actor2 (includes geographic, class, ethnic, religious, and type classes). May be blank if the system was unable to identify an Actor2.",
"mode": "NULLABLE",
"name": "Actor2Code",
"type": "STRING"
},
{
"description": "The actual name of the Actor2. In the case of a political leader or organization, this will be the leader\u2018s formal name (GEORGE W BUSH, UNITED NATIONS), for a geographic match it will be either the country or capital/major city name (UNITED STATES / PARIS), and for ethnic, religious, and type matches it will reflect the root match class (KURD, CATHOLIC, POLICE OFFICER, etc). May be blank if the system was unable to identify an Actor2.",
"mode": "NULLABLE",
"name": "Actor2Name",
"type": "STRING"
},
{
"description": "The 3-character CAMEO code for the country affiliation of Actor2. May be blank if the system was unable to identify an Actor1 or determine its country affiliation (such as \u201cUNIDENTIFIED GUNMEN\u201d).",
"mode": "NULLABLE",
"name": "Actor2CountryCode",
"type": "STRING"
},
{
"description": "If Actor2 is a known IGO/NGO/rebel organization (United Nations, World Bank, al-Qaeda, etc) with its own CAMEO code, this field will contain that code.",
"mode": "NULLABLE",
"name": "Actor2KnownGroupCode",
"type": "STRING"
},
{
"description": "If the source document specifies the ethnic affiliation of Actor2 and that ethnic group has a CAMEO entry, the CAMEO code is entered here. NOTE: a few special groups like ARAB may also have entries in the type column due to legacy CAMEO behavior. NOTE: this behavior is highly experimental and may not capture all affiliations properly \u2013 for more comprehensive and sophisticated identification of ethnic affiliation, it is recommended that users use the GDELT Global Knowledge Graph\u2018s ethnic, religious, and social group taxonomies and post-enrich actors from the GKG.",
"mode": "NULLABLE",
"name": "Actor2EthnicCode",
"type": "STRING"
},
{
"description": "If the source document specifies the religious affiliation of Actor2 and that religious group has a CAMEO entry, the CAMEO code is entered here. NOTE: a few special groups like JEW may also have entries in the geographic or type columns due to legacy CAMEO behavior. NOTE: this behavior is highly experimental and may not capture all affiliations properly \u2013 for more comprehensive and sophisticated identification of ethnic affiliation, it is recommended that users use the GDELT Global Knowledge Graph\u2018s ethnic, religious, and social group taxonomies and post-enrich actors from the GKG.",
"mode": "NULLABLE",
"name": "Actor2Religion1Code",
"type": "STRING"
},
{
"description": "If multiple religious codes are specified for Actor2, this contains the secondary code. Some religion entries automatically use two codes, such as Catholic, which invokes Christianity as Code1 and Catholicism as Code2.",
"mode": "NULLABLE",
"name": "Actor2Religion2Code",
"type": "STRING"
},
{
"description": "The 3-character CAMEO code of the CAMEO \u201ctype\u201d or \u201crole\u201d of Actor2, if specified. This can be a specific role such as Police Forces, Government, Military, Political Opposition, Rebels, etc, a broad role class such as Education, Elites, Media, Refugees, or organizational classes like Non-Governmental Movement. Special codes such as Moderate and Radical may refer to the operational strategy of a group.",
"mode": "NULLABLE",
"name": "Actor2Type1Code",
"type": "STRING"
},
{
"description": "If multiple type/role codes are specified for Actor2, this returns the second code.",
"mode": "NULLABLE",
"name": "Actor2Type2Code",
"type": "STRING"
},
{
"description": "If multiple type/role codes are specified for Actor2, this returns the third code.",
"mode": "NULLABLE",
"name": "Actor2Type3Code",
"type": "STRING"
},
{
"description": "The system codes every event found in an entire document, using an array of techniques to deference and link information together. A number of previous projects such as the ICEWS initiative have found that events occurring in the lead paragraph of a document tend to be the most \u201cimportant.\u201d This flag can therefore be used as a proxy for the rough importance of an event to create subsets of the event stream. NOTE: this field refers only to the first news report to mention an event and is not updated if the event is found in a different context in other news reports. It is included for legacy purposes \u2013 for more precise information on the positioning of an event, see the Mentions table.",
"mode": "NULLABLE",
"name": "IsRootEvent",
"type": "INTEGER"
},
{
"description": "This is the raw CAMEO action code describing the action that Actor1 performed upon Actor2. NOTE: it is strongly recommended that this field be stored as a string instead of an integer, since the CAMEO taxonomy can include zero-leaded event codes that can make distinguishing between certain event types more difficult when stored as an integer.",
"mode": "NULLABLE",
"name": "EventCode",
"type": "STRING"
},
{
"description": "CAMEO event codes are defined in a three-level taxonomy. For events at level three in the taxonomy, this yields its level two leaf root node. For example, code \u201c0251\u201d (\u201cAppeal for easing of administrative sanctions\u201d) would yield an EventBaseCode of \u201c025\u201d (\u201cAppeal to yield\u201d). This makes it possible to aggregate events at various resolutions of specificity. For events at levels two or one, this field will be set to EventCode. NOTE: it is strongly recommended that this field be stored as a string instead of an integer, since the CAMEO taxonomy can include zero-leaded event codes that can make distinguishing between certain event types more difficult when stored as an integer.",
"mode": "NULLABLE",
"name": "EventBaseCode",
"type": "STRING"
},
{
"description": "Similar to EventBaseCode, this defines the root-level category the event code falls under. For example, code \u201c0251\u201d (\u201cAppeal for easing of administrative sanctions\u201d) has a root code of \u201c02\u201d (\u201cAppeal\u201d). This makes it possible to aggregate events at various resolutions of specificity. For events at levels two or one, this field will be set to EventCode. NOTE: it is strongly recommended that this field be stored as a string instead of an integer, since the CAMEO taxonomy can include zero-leaded event codes that can make distinguishing between certain event types more difficult when stored as an integer.",
"mode": "NULLABLE",
"name": "EventRootCode",
"type": "STRING"
},
{
"description": "The entire CAMEO event taxonomy is ultimately organized under four primary classifications: Verbal Cooperation, Material Cooperation, Verbal Conflict, and Material Conflict. This field specifies this primary classification for the event type, allowing analysis at the highest level of aggregation. The numeric codes in this field map to the Quad Classes as follows: 1=Verbal Cooperation, 2=Material Cooperation, 3=Verbal Conflict, 4=Material Conflict.",
"mode": "NULLABLE",
"name": "QuadClass",
"type": "INTEGER"
},
{
"description": "Each CAMEO event code is assigned a numeric score from -10 to +10, capturing the theoretical potential impact that type of event will have on the stability of a country. This is known as the Goldstein Scale. This field specifies the Goldstein score for each event type. NOTE: this score is based on the type of event, not the specifics of the actual event record being recorded \u2013 thus two riots, one with 10 people and one with 10,000, will both receive the same Goldstein score. This can be aggregated to various levels of time resolution to yield an approximation of the stability of a location over time.",
"mode": "NULLABLE",
"name": "GoldsteinScale",
"type": "FLOAT"
},
{
"description": "This is the total number of mentions of this event across all source documents during the 15 minute update in which it was first seen. Multiple references to an event within a single document also contribute to this count. This can be used as a method of assessing the \u201cimportance\u201d of an event: the more discussion of that event, the more likely it is to be significant. The total universe of source documents and the density of events within them vary over time, so it is recommended that this field be normalized by the average or other measure of the universe of events during the time period of interest. This field is actually a composite score of the total number of raw mentions and the number of mentions extracted from reprocessed versions of each article (see the discussion for the Mentions table). NOTE: this field refers only to the first news report to mention an event and is not updated if the event is found in a different context in other news reports. It is included for legacy purposes \u2013 for more precise information on the positioning of an event, see the Mentions table.",
"mode": "NULLABLE",
"name": "NumMentions",
"type": "INTEGER"
},
{
"description": "This is the total number of information sources containing one or more mentions of this event during the 15 minute update in which it was first seen. This can be used as a method of assessing the \u201cimportance\u201d of an event: the more discussion of that event, the more likely it is to be significant. The total universe of sources varies over time, so it is recommended that this field be normalized by the average or other measure of the universe of events during the time period of interest. NOTE: this field refers only to the first news report to mention an event and is not updated if the event is found in a different context in other news reports. It is included for legacy purposes \u2013 for more precise information on the positioning of an event, see the Mentions table.",
"mode": "NULLABLE",
"name": "NumSources",
"type": "INTEGER"
},
{
"description": "This is the total number of source documents containing one or more mentions of this event during the 15 minute update in which it was first seen. This can be used as a method of assessing the \u201cimportance\u201d of an event: the more discussion of that event, the more likely it is to be significant. The total universe of source documents varies over time, so it is recommended that this field be normalized by the average or other measure of the universe of events during the time period of interest. NOTE: this field refers only to the first news report to mention an event and is not updated if the event is found in a different context in other news reports. It is included for legacy purposes \u2013 for more precise information on the positioning of an event, see the Mentions table.",
"mode": "NULLABLE",
"name": "NumArticles",
"type": "INTEGER"
},
{
"description": "This is the average \u201ctone\u201d of all documents containing one or more mentions of this event during the 15 minute update in which it was first seen. The score ranges from -100 (extremely negative) to +100 (extremely positive). Common values range between -10 and +10, with 0 indicating neutral. This can be used as a method of filtering the \u201ccontext\u201d of events as a subtle measure of the importance of an event and as a proxy for the \u201cimpact\u201d of that event. For example, a riot event with a slightly negative average tone is likely to have been a minor occurrence, whereas if it had an extremely negative average tone, it suggests a far more serious occurrence. A riot with a positive score likely suggests a very minor occurrence described in the context of a more positive narrative (such as a report of an attack occurring in a discussion of improving conditions on the ground in a country and how the number of attacks per day has been greatly reduced). NOTE: this field refers only to the first news report to mention an event and is not updated if the event is found in a different context in other news reports. It is included for legacy purposes \u2013 for more precise information on the positioning of an event, see the Mentions table. NOTE: this provides only a basic tonal assessment of an article and it is recommended that users interested in emotional measures use the Mentions and Global Knowledge Graph tables to merge the complete set of 2,300 emotions and themes from the GKG GCAM system into their analysis of event records.",
"mode": "NULLABLE",
"name": "AvgTone",
"type": "FLOAT"
},
{
"description": "This field specifies the geographic resolution of the match type and holds one of the following values: 1=COUNTRY (match was at the country level), 2=USSTATE (match was to a US state), 3=USCITY (match was to a US city or landmark), 4=WORLDCITY (match was to a city or landmark outside the US), 5=WORLDSTATE (match was to an Administrative Division 1 outside the US \u2013 roughly equivalent to a US state). This can be used to filter events by geographic specificity, for example, extracting only those events with a landmark-level geographic resolution for mapping. Note that matches with codes 1 (COUNTRY), 2 (USSTATE), and 5 (WORLDSTATE) will still provide a latitude/longitude pair, which will be the centroid of that country or state, but the FeatureID field below will be blank.",
"mode": "NULLABLE",
"name": "Actor1Geo_Type",
"type": "INTEGER"
},
{
"description": "This is the full human-readable name of the matched location. In the case of a country it is simply the country name. For US and World states it is in the format of \u201cState, Country Name\u201d, while for all other matches it is in the format of \u201cCity/Landmark, State, Country\u201d. This can be used to label locations when placing events on a map. NOTE: this field reflects the precise name used to refer to the location in the text itself, meaning it may contain multiple spellings of the same location \u2013 use the FeatureID column to determine whether two location names refer to the same place.",
"mode": "NULLABLE",
"name": "Actor1Geo_FullName",
"type": "STRING"
},
{
"description": "This is the 2-character FIPS10-4 country code for the location.",
"mode": "NULLABLE",
"name": "Actor1Geo_CountryCode",
"type": "STRING"
},
{
"description": "This is the 2-character FIPS10-4 country code followed by the 2-character FIPS10-4 administrative division 1 (ADM1) code for the administrative division housing the landmark. In the case of the United States, this is the 2-character shortform of the state\u2018s name (such as \u201cTX\u201d for Texas).",
"mode": "NULLABLE",
"name": "Actor1Geo_ADM1Code",
"type": "STRING"
},
{
"description": "For international locations this is the numeric Global Administrative Unit Layers (GAUL) administrative division 2 (ADM2) code assigned to each global location, while for US locations this is the two-character shortform of the state\u2018s name (such as \u201cTX\u201d for Texas) followed by the 3-digit numeric county code (following the INCITS 31:200x standard used in GNIS). For more detail on the contents and computation of this field, please see the following footnoted URL. NOTE: This field may be blank/null in cases where no ADM2 information was available, for some ADM1-level matches, and for all country-level matches. NOTE: this field may still contain a value for ADM1-level matches depending on how they are codified in GNS.",
"mode": "NULLABLE",
"name": "Actor1Geo_ADM2Code",
"type": "STRING"
},
{
"description": "This is the centroid latitude of the landmark for mapping.",
"mode": "NULLABLE",
"name": "Actor1Geo_Lat",
"type": "FLOAT"
},
{
"description": "This is the centroid longitude of the landmark for mapping.",
"mode": "NULLABLE",
"name": "Actor1Geo_Long",
"type": "FLOAT"
},
{
"description": "This is the GNS or GNIS FeatureID for this location. More information on these values can be found in Leetaru (2012). NOTE: When Actor1Geo_Type has a value of 3 or 4 this field will contain a signed numeric value, while it will contain a textual FeatureID in the case of other match resolutions (usually the country code or country code and ADM1 code). A small percentage of small cities and towns may have a blank value in this field even for Actor1Geo_Type values of 3 or 4: this will be corrected in the 2.0 release of GDELT. NOTE: This field can contain both positive and negative numbers, see Leetaru (2012) for more information on this.",
"mode": "NULLABLE",
"name": "Actor1Geo_FeatureID",
"type": "STRING"
},
{
"description": "This field specifies the geographic resolution of the match type and holds one of the following values: 1=COUNTRY (match was at the country level), 2=USSTATE (match was to a US state), 3=USCITY (match was to a US city or landmark), 4=WORLDCITY (match was to a city or landmark outside the US), 5=WORLDSTATE (match was to an Administrative Division 1 outside the US \u2013 roughly equivalent to a US state). This can be used to filter events by geographic specificity, for example, extracting only those events with a landmark-level geographic resolution for mapping. Note that matches with codes 1 (COUNTRY), 2 (USSTATE), and 5 (WORLDSTATE) will still provide a latitude/longitude pair, which will be the centroid of that country or state, but the FeatureID field below will be blank.",
"mode": "NULLABLE",
"name": "Actor2Geo_Type",
"type": "INTEGER"
},
{
"description": "This is the full human-readable name of the matched location. In the case of a country it is simply the country name. For US and World states it is in the format of \u201cState, Country Name\u201d, while for all other matches it is in the format of \u201cCity/Landmark, State, Country\u201d. This can be used to label locations when placing events on a map. NOTE: this field reflects the precise name used to refer to the location in the text itself, meaning it may contain multiple spellings of the same location \u2013 use the FeatureID column to determine whether two location names refer to the same place.",
"mode": "NULLABLE",
"name": "Actor2Geo_FullName",
"type": "STRING"
},
{
"description": "This is the 2-character FIPS10-4 country code for the location.",
"mode": "NULLABLE",
"name": "Actor2Geo_CountryCode",
"type": "STRING"
},
{
"description": "This is the 2-character FIPS10-4 country code followed by the 2-character FIPS10-4 administrative division 1 (ADM1) code for the administrative division housing the landmark. In the case of the United States, this is the 2-character shortform of the state\u2018s name (such as \u201cTX\u201d for Texas).",
"mode": "NULLABLE",
"name": "Actor2Geo_ADM1Code",
"type": "STRING"
},
{
"description": "For international locations this is the numeric Global Administrative Unit Layers (GAUL) administrative division 2 (ADM2) code assigned to each global location, while for US locations this is the two-character shortform of the state\u2018s name (such as \u201cTX\u201d for Texas) followed by the 3-digit numeric county code (following the INCITS 31:200x standard used in GNIS). For more detail on the contents and computation of this field, please see the following footnoted URL. NOTE: This field may be blank/null in cases where no ADM2 information was available, for some ADM1-level matches, and for all country-level matches. NOTE: this field may still contain a value for ADM1-level matches depending on how they are codified in GNS.",
"mode": "NULLABLE",
"name": "Actor2Geo_ADM2Code",
"type": "STRING"
},
{
"description": "This is the centroid latitude of the landmark for mapping.",
"mode": "NULLABLE",
"name": "Actor2Geo_Lat",
"type": "FLOAT"
},
{
"description": "This is the centroid longitude of the landmark for mapping.",
"mode": "NULLABLE",
"name": "Actor2Geo_Long",
"type": "FLOAT"
},
{
"description": "This is the GNS or GNIS FeatureID for this location. More information on these values can be found in Leetaru (2012). NOTE: When Actor2Geo_Type has a value of 3 or 4 this field will contain a signed numeric value, while it will contain a textual FeatureID in the case of other match resolutions (usually the country code or country code and ADM1 code). A small percentage of small cities and towns may have a blank value in this field even for Actor2Geo_Type values of 3 or 4: this will be corrected in the 2.0 release of GDELT. NOTE: This field can contain both positive and negative numbers, see Leetaru (2012) for more information on this.",
"mode": "NULLABLE",
"name": "Actor2Geo_FeatureID",
"type": "STRING"
},
{
"description": "This field specifies the geographic resolution of the match type and holds one of the following values: 1=COUNTRY (match was at the country level), 2=USSTATE (match was to a US state), 3=USCITY (match was to a US city or landmark), 4=WORLDCITY (match was to a city or landmark outside the US), 5=WORLDSTATE (match was to an Administrative Division 1 outside the US \u2013 roughly equivalent to a US state). This can be used to filter events by geographic specificity, for example, extracting only those events with a landmark-level geographic resolution for mapping. Note that matches with codes 1 (COUNTRY), 2 (USSTATE), and 5 (WORLDSTATE) will still provide a latitude/longitude pair, which will be the centroid of that country or state, but the FeatureID field below will be blank.",
"mode": "NULLABLE",
"name": "ActionGeo_Type",
"type": "INTEGER"
},
{
"description": "This is the full human-readable name of the matched location. In the case of a country it is simply the country name. For US and World states it is in the format of \u201cState, Country Name\u201d, while for all other matches it is in the format of \u201cCity/Landmark, State, Country\u201d. This can be used to label locations when placing events on a map. NOTE: this field reflects the precise name used to refer to the location in the text itself, meaning it may contain multiple spellings of the same location \u2013 use the FeatureID column to determine whether two location names refer to the same place.",
"mode": "NULLABLE",
"name": "ActionGeo_FullName",
"type": "STRING"
},
{
"description": "This is the 2-character FIPS10-4 country code for the location.",
"mode": "NULLABLE",
"name": "ActionGeo_CountryCode",
"type": "STRING"
},
{
"description": "This is the 2-character FIPS10-4 country code followed by the 2-character FIPS10-4 administrative division 1 (ADM1) code for the administrative division housing the landmark. In the case of the United States, this is the 2-character shortform of the state\u2018s name (such as \u201cTX\u201d for Texas).",
"mode": "NULLABLE",
"name": "ActionGeo_ADM1Code",
"type": "STRING"
},
{
"description": "For international locations this is the numeric Global Administrative Unit Layers (GAUL) administrative division 2 (ADM2) code assigned to each global location, while for US locations this is the two-character shortform of the state\u2018s name (such as \u201cTX\u201d for Texas) followed by the 3-digit numeric county code (following the INCITS 31:200x standard used in GNIS). For more detail on the contents and computation of this field, please see the following footnoted URL. NOTE: This field may be blank/null in cases where no ADM2 information was available, for some ADM1-level matches, and for all country-level matches. NOTE: this field may still contain a value for ADM1-level matches depending on how they are codified in GNS.",
"mode": "NULLABLE",
"name": "ActionGeo_ADM2Code",
"type": "STRING"
},
{
"description": "This is the centroid latitude of the landmark for mapping.",
"mode": "NULLABLE",
"name": "ActionGeo_Lat",
"type": "FLOAT"
},
{
"description": "This is the centroid longitude of the landmark for mapping.",
"mode": "NULLABLE",
"name": "ActionGeo_Long",
"type": "FLOAT"
},
{
"description": "This is the GNS or GNIS FeatureID for this location. More information on these values can be found in Leetaru (2012). NOTE: When ActionGeo_Type has a value of 3 or 4 this field will contain a signed numeric value, while it will contain a textual FeatureID in the case of other match resolutions (usually the country code or country code and ADM1 code). A small percentage of small cities and towns may have a blank value in this field even for ActionGeo_Type values of 3 or 4: this will be corrected in the 2.0 release of GDELT. NOTE: This field can contain both positive and negative numbers, see Leetaru (2012) for more information on this.",
"mode": "NULLABLE",
"name": "ActionGeo_FeatureID",
"type": "STRING"
},
{
"description": "This field stores the date the event was added to the master database in YYYYMMDDHHMMSS format in the UTC timezone. For those needing to access events at 15 minute resolution, this is the field that should be used in queries.",
"mode": "NULLABLE",
"name": "DATEADDED",
"type": "INTEGER"
},
{
"description": "This field records the URL or citation of the first news report it found this event in. In most cases this is the first report it saw the article in, but due to the timing and flow of news reports through the processing pipeline, this may not always be the very first report, but is at least in the first few reports.",
"mode": "NULLABLE",
"name": "SOURCEURL",
"type": "STRING"
}
]
},
"selfLink": "https://www.googleapis.com/bigquery/v2/projects/gdelt-bq/datasets/gdeltv2/tables/events",
"tableReference": {
"datasetId": "gdeltv2",
"projectId": "gdelt-bq",
"tableId": "events"
},
"type": "TABLE"
}BigQuery JSON Type ⇒ case class Event
bq show --format=prettyjson gdelt-bq:gdeltv2.events | jq '.schema' |jq '.[]|.[]|[.name +": " + .type + ","]|.[]' |sed "s/INTEGER/Int/"| sed "s/FLOAT/Double/" | sed "s/STRING/String/" | sed "s/\"//g"Event case class
case class Event(
GLOBALEVENTID: Int,
SQLDATE: Int,
MonthYear: Int,
Year: Int,
FractionDate: Double,
Actor1Code: String,
Actor1Name: String,
Actor1CountryCode: String,
Actor1KnownGroupCode: String,
Actor1EthnicCode: String,
Actor1Religion1Code: String,
Actor1Religion2Code: String,
Actor1Type1Code: String,
Actor1Type2Code: String,
Actor1Type3Code: String,
Actor2Code: String,
Actor2Name: String,
Actor2CountryCode: String,
Actor2KnownGroupCode: String,
Actor2EthnicCode: String,
Actor2Religion1Code: String,
Actor2Religion2Code: String,
Actor2Type1Code: String,
Actor2Type2Code: String,
Actor2Type3Code: String,
IsRootEvent: Int,
EventCode: String,
EventBaseCode: String,
EventRootCode: String,
QuadClass: Int,
GoldsteinScale: Double,
NumMentions: Int,
NumSources: Int,
NumArticles: Int,
AvgTone: Double,
Actor1Geo_Type: Int,
Actor1Geo_FullName: String,
Actor1Geo_CountryCode: String,
Actor1Geo_ADM1Code: String,
Actor1Geo_ADM2Code: String,
Actor1Geo_Lat: Double,
Actor1Geo_Long: Double,
Actor1Geo_FeatureID: String,
Actor2Geo_Type: Int,
Actor2Geo_FullName: String,
Actor2Geo_CountryCode: String,
Actor2Geo_ADM1Code: String,
Actor2Geo_ADM2Code: String,
Actor2Geo_Lat: Double,
Actor2Geo_Long: Double,
Actor2Geo_FeatureID: String,
ActionGeo_Type: Int,
ActionGeo_FullName: String,
ActionGeo_CountryCode: String,
ActionGeo_ADM1Code: String,
ActionGeo_ADM2Code: String,
ActionGeo_Lat: Double,
ActionGeo_Long: Double,
ActionGeo_FeatureID: String,
DATEADDED: BigInt,
SOURCEURL: String
)Data cleanup (wrangling/munging)
correction des types de donnees (STRING→DATE,INT→BIGINT…)
correction des valeurs (lignes incompletes, valeurs incorrectes…)
…
RDD ⇒ DataSet ⇒ SparkSQL
def toDouble(s : String): Double = if (s.isEmpty) 0 else s.toDouble
def toInt(s : String): Int = if (s.isEmpty) 0 else s.toInt
def toBigInt(s : String): BigInt = if (s.isEmpty) BigInt(0) else BigInt(s)
cachedEvents.map(_.split("\t")).filter(_.length==61).map(
e=> Event(
toInt(e(0)),toInt(e(1)),toInt(e(2)),toInt(e(3)),toDouble(e(4)),e(5),e(6),e(7),e(8),e(9),e(10),e(11),e(12),e(13),e(14),e(15),e(16),e(17),e(18),e(19),e(20),
e(21),e(22),e(23),e(24),toInt(e(25)),e(26),e(27),e(28),toInt(e(29)),toDouble(e(30)),toInt(e(31)),toInt(e(32)),toInt(e(33)),toDouble(e(34)),toInt(e(35)),e(36),e(37),e(38),e(39),toDouble(e(40)),
toDouble(e(41)),e(42),toInt(e(43)),e(44),e(45),e(46),e(47),toDouble(e(48)),toDouble(e(49)),e(50),toInt(e(51)),e(52),e(53),e(54),e(55),toDouble(e(56)),toDouble(e(57)),e(58),toBigInt(e(59)),e(60))
).toDS.createOrReplaceTempView("export")
spark.catalog.cacheTable("export")Exploration via Zeppelin/SparkUI
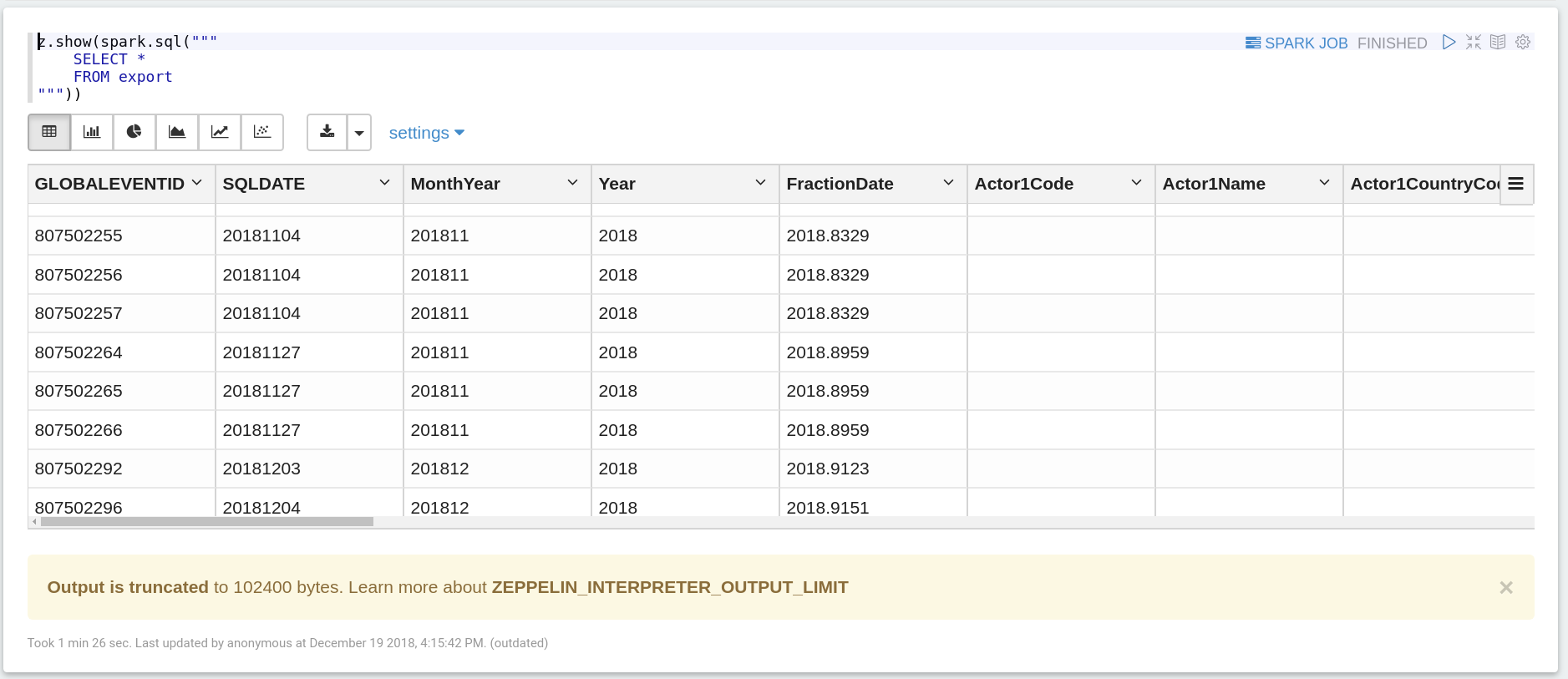
Output is truncated
Volumetrie
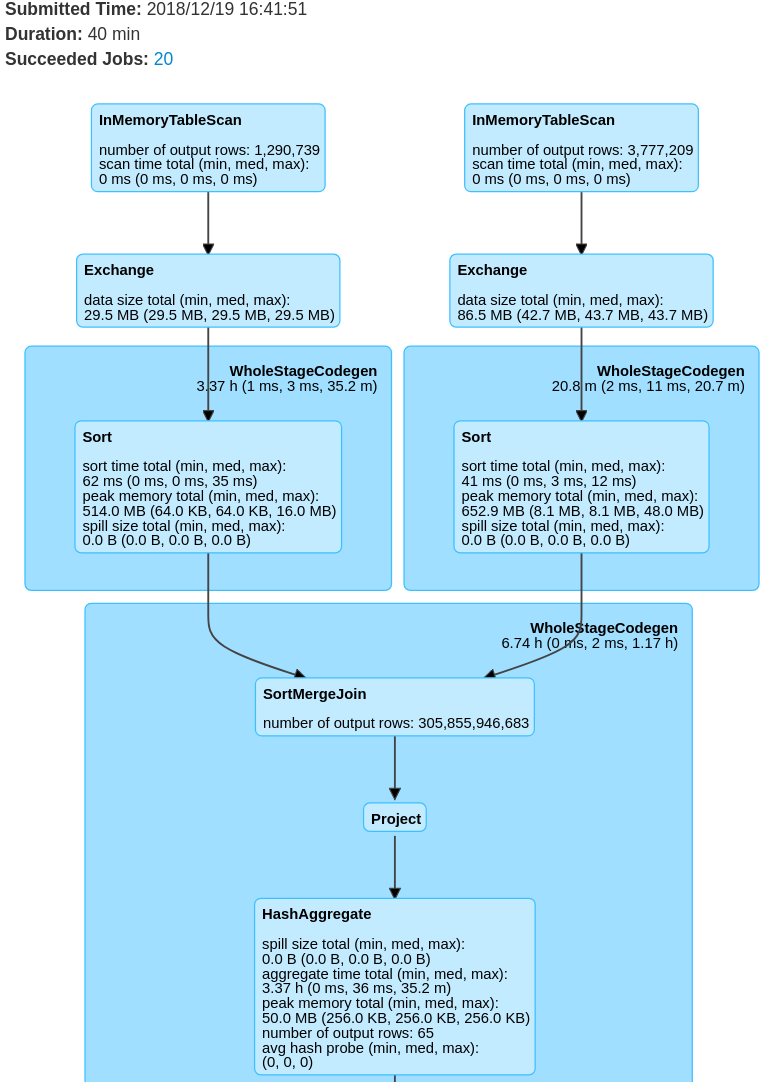
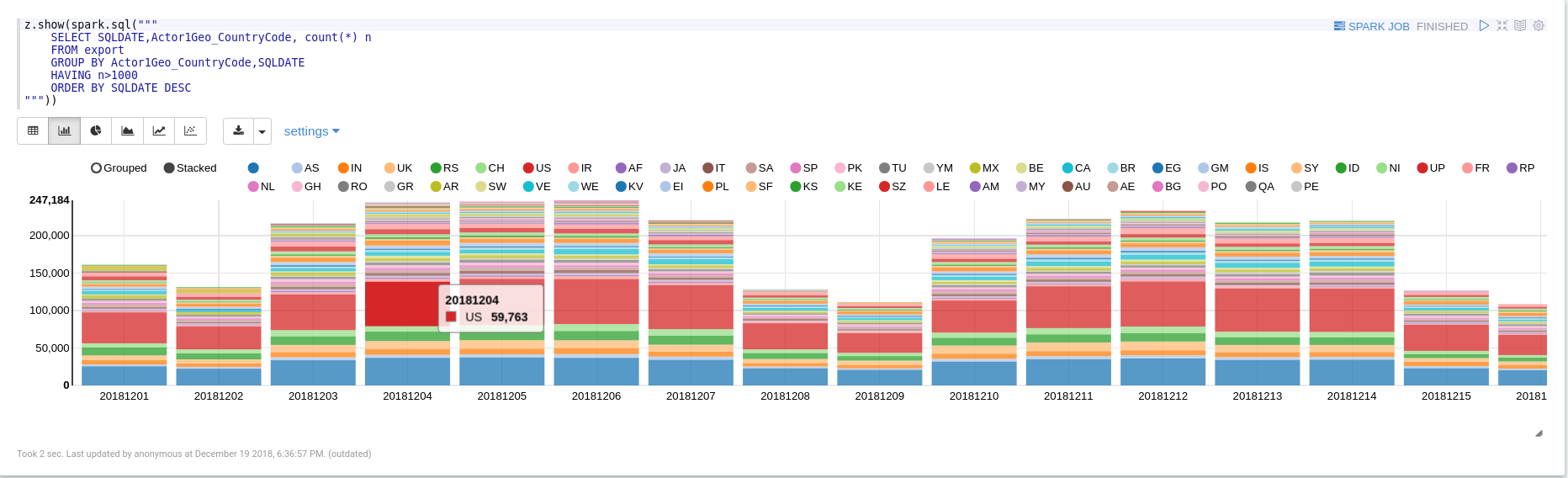
Events by Actor1Country (export)
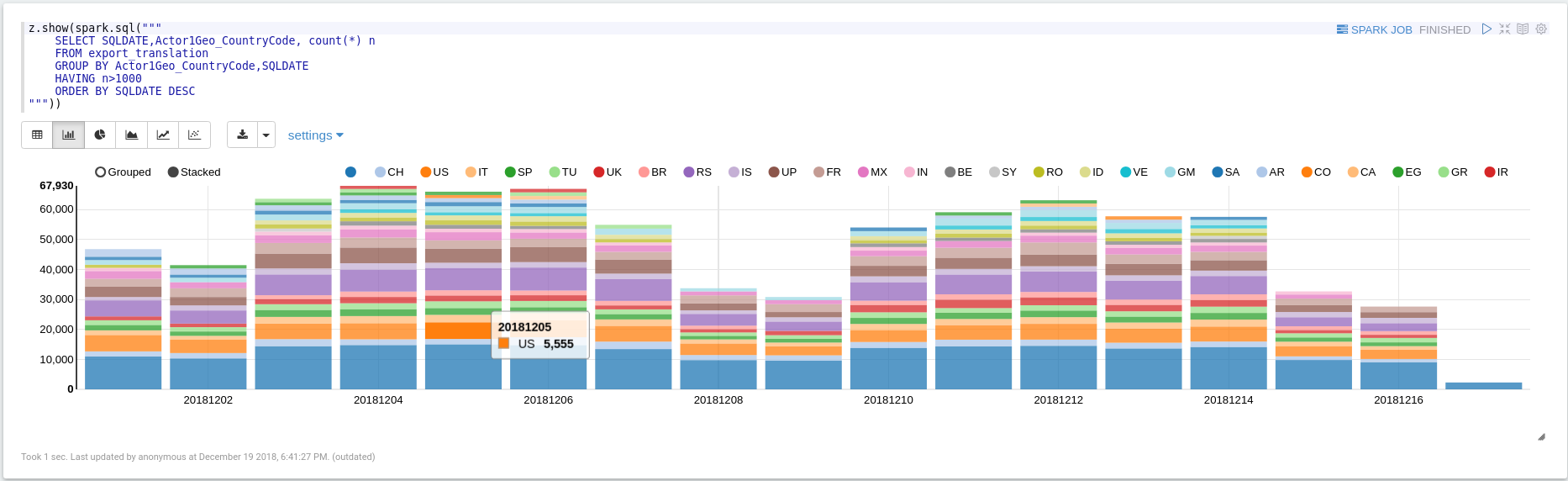
Events by Actor1Country (export-translation)
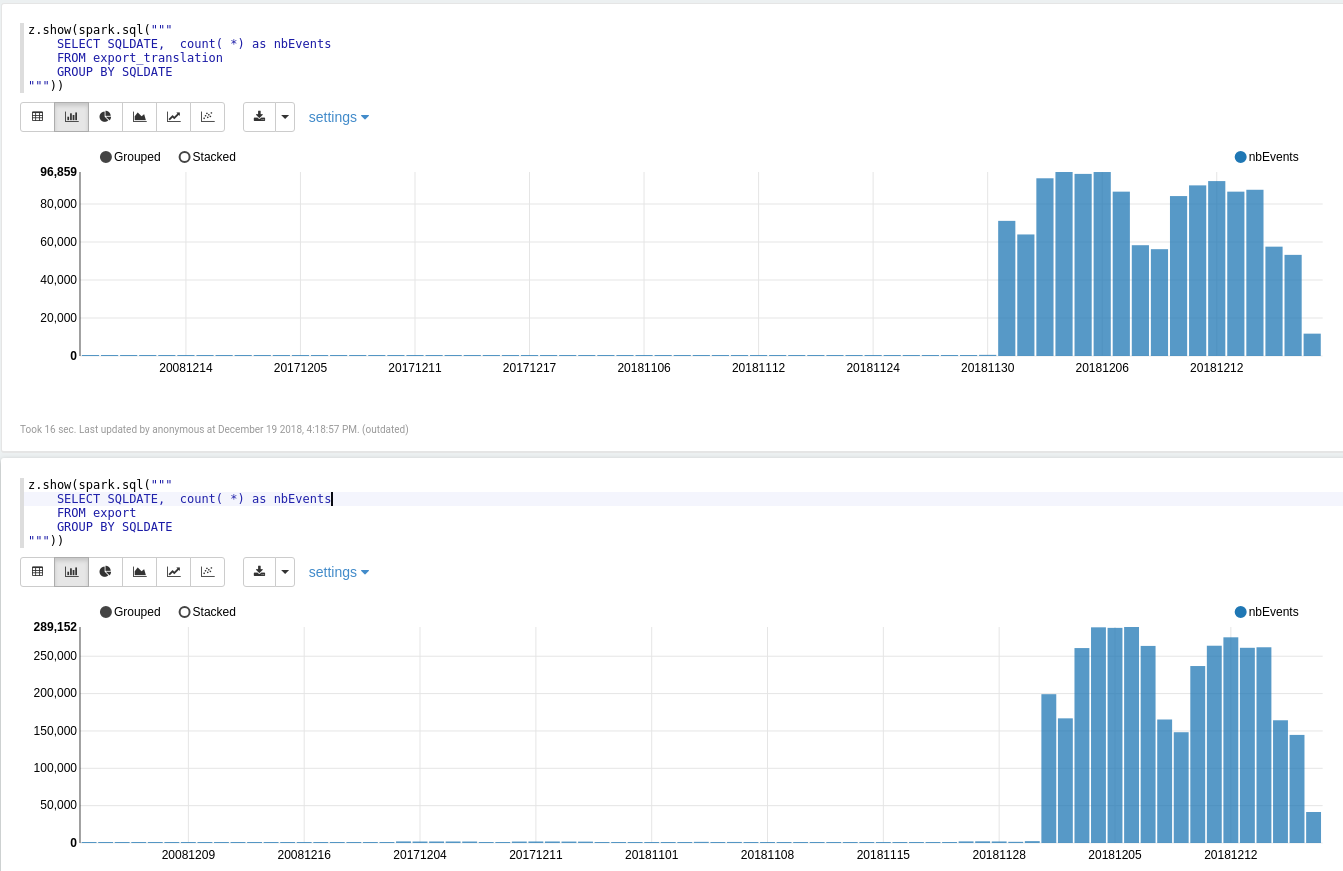
Volumetrie (cached table)
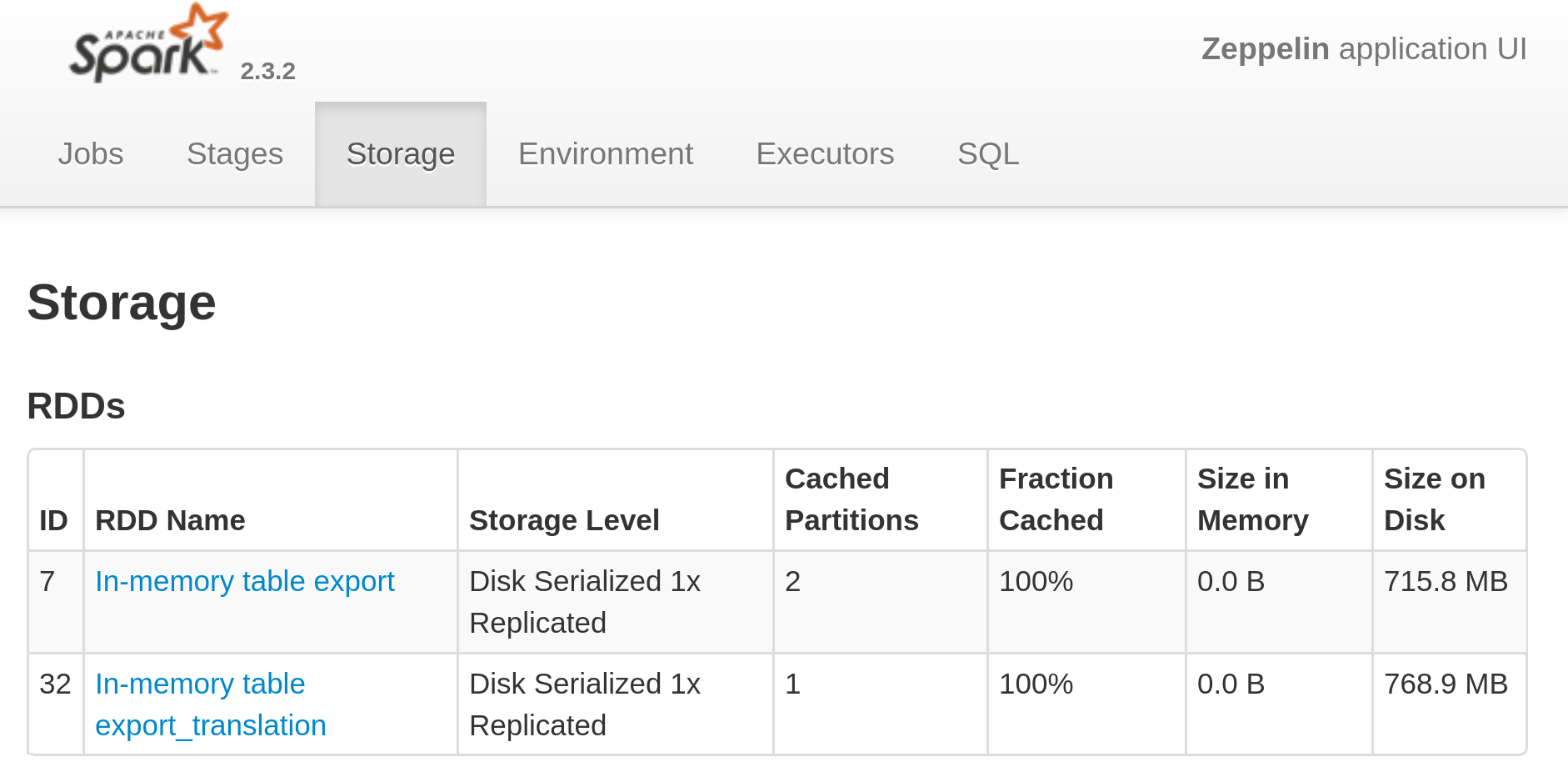
Volumetrie (cached table)